 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Expert Trajectory Utilization in LLM Post-training
Dec 12, 2025While effective post-training integrates Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), the optimal mechanism for utilizing expert trajectories remains unresolved. We propose the Plasticity-Ceiling Framework to theoretically ground this landscape, decomposing performance into foundational SFT performance and the subsequent RL plasticity. Through extensive benchmarking, we establish the Sequential SFT-then-RL pipeline as the superior standard, overcoming the stability deficits of synchronized approaches. Furthermore, we derive precise scaling guidelines: (1) Transitioning to RL at the SFT Stable or Mild Overfitting Sub-phase maximizes the final ceiling by securing foundational SFT performance without compromising RL plasticity; (2) Refuting ``Less is More'' in the context of SFT-then-RL scaling, we demonstrate that Data Scale determines the primary post-training potential, while Trajectory Difficulty acts as a performance multiplier; and (3) Identifying that the Minimum SFT Validation Loss serves as a robust indicator for selecting the expert trajectories that maximize the final performance ceiling. Our findings provide actionable guidelines for maximizing the value extracted from expert trajectories.
TunaGAN: Interpretable GAN for Smart Editing
Aug 16, 2019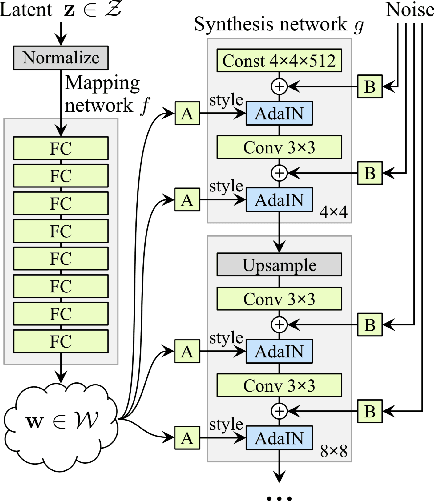
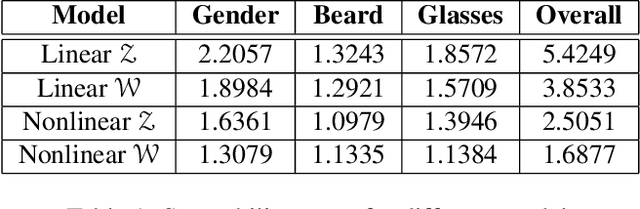
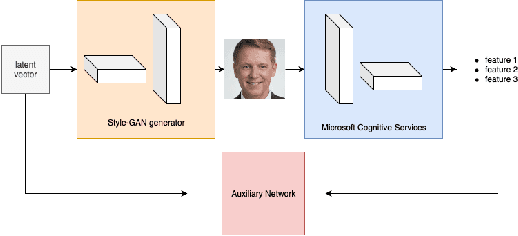

In this paper, we introduce a tunable generative adversary network (TunaGAN) that uses an auxiliary network on top of existing generator networks (Style-GAN) to modify high-resolution face images according to user's high-level instructions, with good qualitative and quantitative performance. To optimize for feature disentanglement, we also investigate two different latent space that could be traversed for modification. The problem of mode collapse is characterized in detail for model robustness. This work could be easily extended to content-aware image editor based on other GANs and provide insight on mode collapse problems in more general settings.