 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence Simplification Using Paraphrase Corpus for Initialization
May 31, 2023Neural sentence simplification method based on sequence-to-sequence framework has become the mainstream method for sentence simplification (SS) task. Unfortunately, these methods are currently limited by the scarcity of parallel SS corpus. In this paper, we focus on how to reduce the dependence on parallel corpus by leveraging a careful initialization for neural SS methods from paraphrase corpus. Our work is motivated by the following two findings: (1) Paraphrase corpus includes a large proportion of sentence pairs belonging to SS corpus. (2) We can construct large-scale pseudo parallel SS data by keeping these sentence pairs with a higher complexity difference. Therefore, we propose two strategies to initialize neural SS methods using paraphrase corpus. We train three different neural SS methods with our initialization, which can obtain substantial improvements on the available WikiLarge data compared with themselves without initialization.
ParaLS: Lexical Substitution via Pretrained Paraphraser
May 14, 2023



Lexical substitution (LS) aims at finding appropriate substitutes for a target word in a sentence. Recently, LS methods based on pretrained language models have made remarkable progress, generating potential substitutes for a target word through analysis of its contextual surroundings. However, these methods tend to overlook the preservation of the sentence's meaning when generating the substitutes. This study explores how to generate the substitute candidates from a paraphraser, as the generated paraphrases from a paraphraser contain variations in word choice and preserve the sentence's meaning. Since we cannot directly generate the substitutes via commonly used decoding strategies, we propose two simple decoding strategies that focus on the variations of the target word during decoding. Experimental results show that our methods outperform state-of-the-art LS methods based on pre-trained language models on three benchmarks.
Sentence Simplification via Large Language Models
Feb 23, 2023



Sentence Simplification aims to rephrase complex sentences into simpler sentences while retaining original meaning. Large Language models (LLMs) have demonstrated the ability to perform a variety of natural language processing tasks. However, it is not yet known whether LLMs can be served as a high-quality sentence simplification system. In this work, we empirically analyze the zero-/few-shot learning ability of LLMs by evaluating them on a number of benchmark test sets. Experimental results show LLMs outperform state-of-the-art sentence simplification methods, and are judged to be on a par with human annotators.
Chinese Idiom Paraphrasing
Apr 20, 2022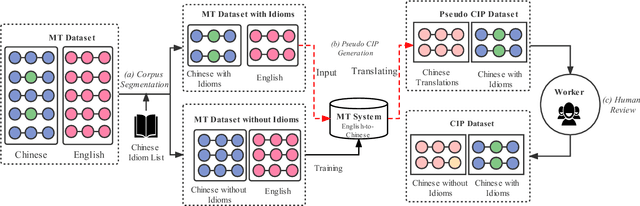
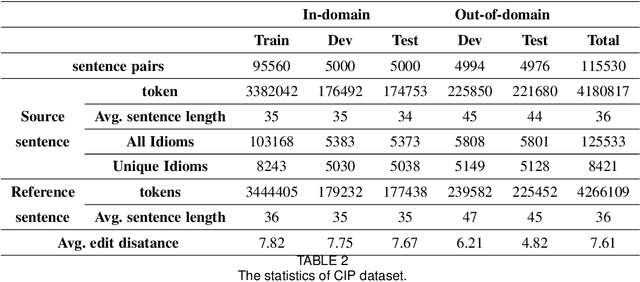
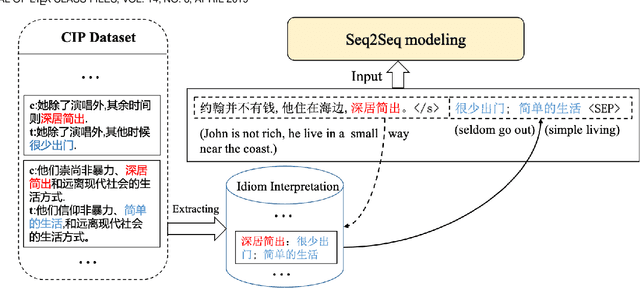

Idioms, are a kind of idiomatic expression in Chinese, most of which consist of four Chinese characters. Due to the properties of non-compositionality and metaphorical meaning, Chinese Idioms are hard to be understood by children and non-native speakers. This study proposes a novel task, denoted as Chinese Idiom Paraphrasing (CIP). CIP aims to rephrase idioms-included sentences to non-idiomatic ones under the premise of preserving the original sentence's meaning. Since the sentences without idioms are easier handled by Chinese NLP systems, CIP can be used to pre-process Chinese datasets, thereby facilitating and improving the performance of Chinese NLP tasks, e.g., machine translation system, Chinese idiom cloze, and Chinese idiom embeddings. In this study, CIP task is treated as a special paraphrase generation task. To circumvent difficulties in acquiring annotations, we first establish a large-scale CIP dataset based on human and machine collaboration, which consists of 115,530 sentence pairs. We further deploy three baselines and two novel CIP approaches to deal with CIP problems. The results show that the proposed methods have better performances than the baselines based on the established CIP dataset.
Prompt-Learning for Short Text Classification
Mar 31, 2022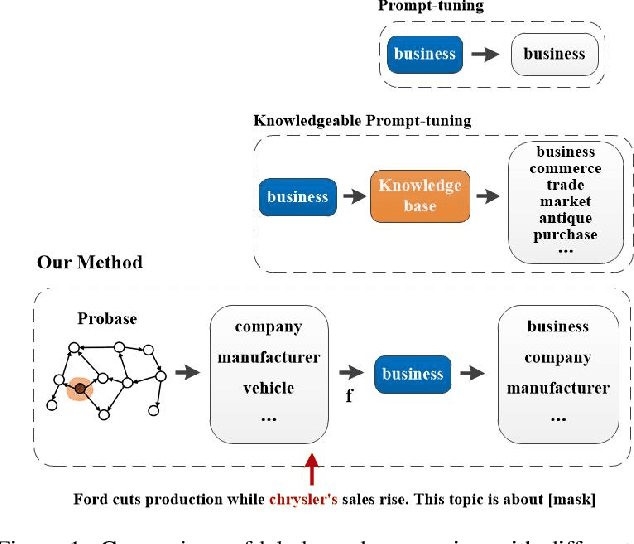

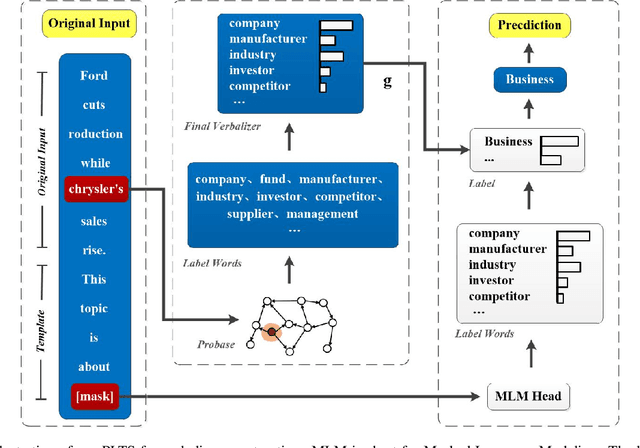
In the short text, the extremely short length, feature sparsity, and high ambiguity pose huge challenges to classification tasks. Recently, as an effective method for tuning Pre-trained Language Models for specific downstream tasks, prompt-learning has attracted a vast amount of attention and research. The main intuition behind the prompt-learning is to insert the template into the input and convert the text classification tasks into equivalent cloze-style tasks. However, most prompt-learning methods expand label words manually or only consider the class name for knowledge incorporating in cloze-style prediction, which will inevitably incur omissions and bias in short text classification tasks. In this paper, we propose a simple short text classification approach that makes use of prompt-learning based on knowledgeable expansion. Taking the special characteristics of short text into consideration, the method can consider both the short text itself and class name during expanding label words space. Specifically, the top $N$ concepts related to the entity in the short text are retrieved from the open Knowledge Graph like Probase, and we further refine the expanded label words by the distance calculation between selected concepts and class labels. Experimental results show that our approach obtains obvious improvement compared with other fine-tuning, prompt-learning, and knowledgeable prompt-tuning methods, outperforming the state-of-the-art by up to 6 Accuracy points on three well-known datasets.
An Unsupervised Method for Building Sentence Simplification Corpora in Multiple Languages
Sep 01, 2021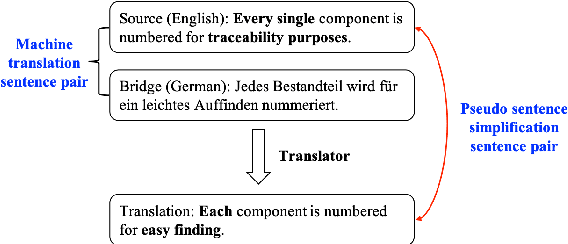

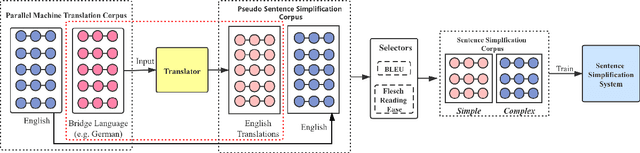
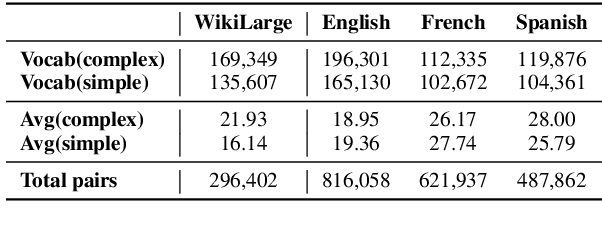
The availability of parallel sentence simplification (SS) is scarce for neural SS modelings. We propose an unsupervised method to build SS corpora from large-scale bilingual translation corpora, alleviating the need for SS supervised corpora. Our method is motivated by the following two findings: neural machine translation model usually tends to generate more high-frequency tokens and the difference of text complexity levels exists between the source and target language of a translation corpus. By taking the pair of the source sentences of translation corpus and the translations of their references in a bridge language, we can construct large-scale pseudo parallel SS data. Then, we keep these sentence pairs with a higher complexity difference as SS sentence pairs. The building SS corpora with an unsupervised approach can satisfy the expectations that the aligned sentences preserve the same meanings and have difference in text complexity levels. Experimental results show that SS methods trained by our corpora achieve the state-of-the-art results and significantly outperform the results on English benchmark WikiLarge.
Chinese Lexical Simplification
Oct 14, 2020

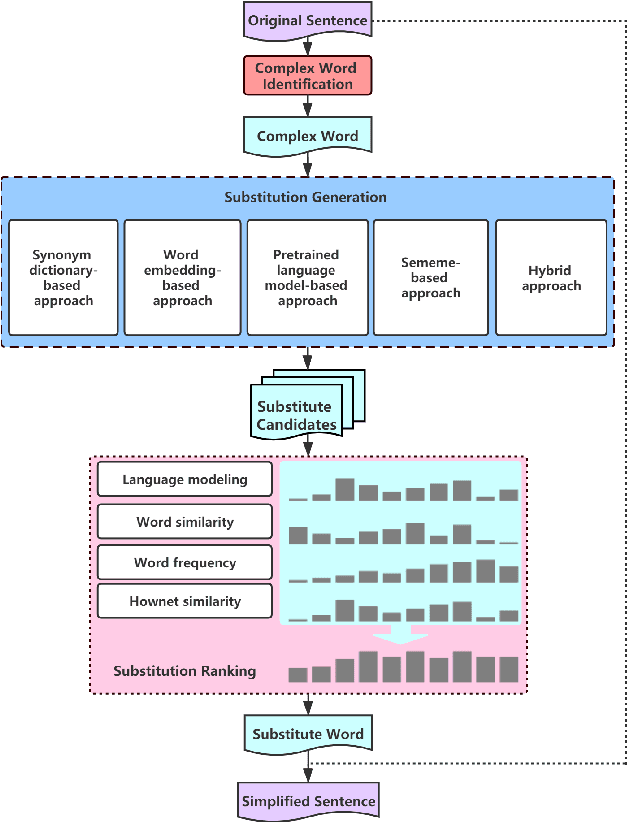
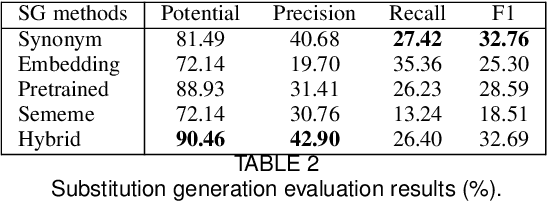
Lexical simplification has attracted much attention in many languages, which is the process of replacing complex words in a given sentence with simpler alternatives of equivalent meaning. Although the richness of vocabulary in Chinese makes the text very difficult to read for children and non-native speakers, there is no research work for Chinese lexical simplification (CLS) task. To circumvent difficulties in acquiring annotations, we manually create the first benchmark dataset for CLS, which can be used for evaluating the lexical simplification systems automatically. In order to acquire more thorough comparison, we present five different types of methods as baselines to generate substitute candidates for the complex word that include synonym-based approach, word embedding-based approach, pretrained language model-based approach, sememe-based approach, and a hybrid approach. Finally, we design the experimental evaluation of these baselines and discuss their advantages and disadvantages. To our best knowledge, this is the first study for CLS task.
LSBert: A Simple Framework for Lexical Simplification
Jun 25, 2020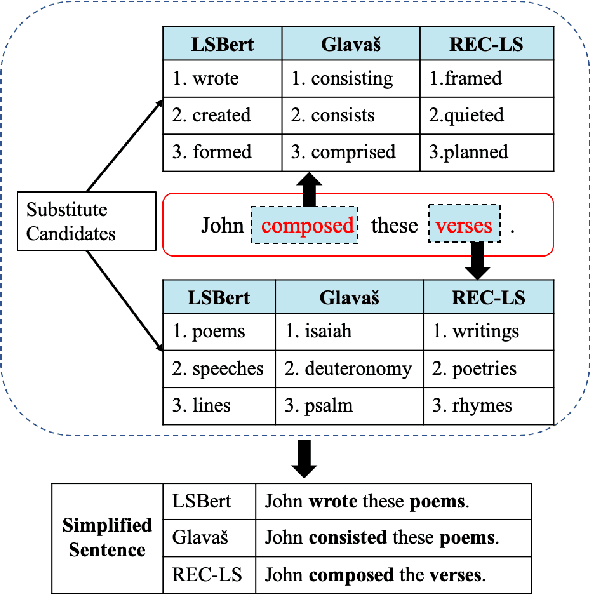
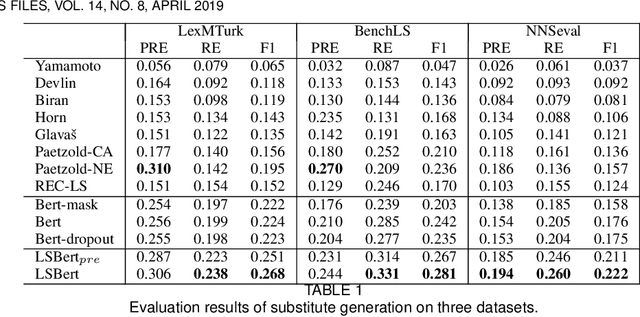
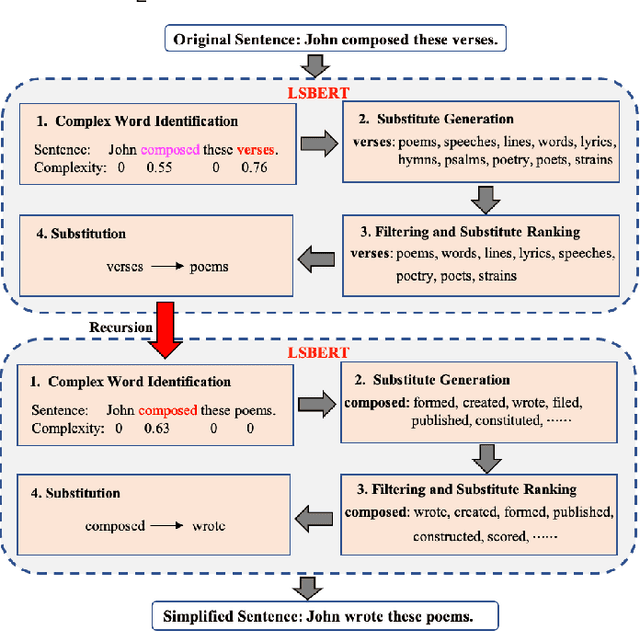
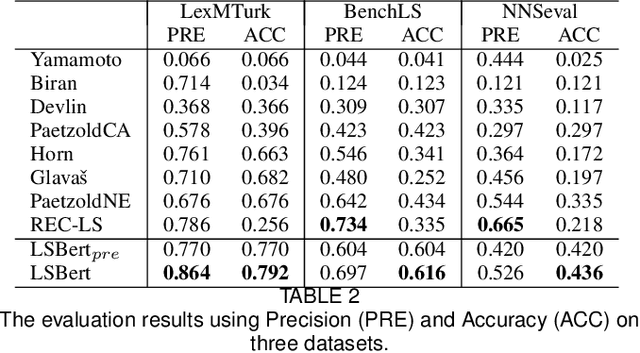
Lexical simplification (LS) aims to replace complex words in a given sentence with their simpler alternatives of equivalent meaning, to simplify the sentence. Recently unsupervised lexical simplification approaches only rely on the complex word itself regardless of the given sentence to generate candidate substitutions, which will inevitably produce a large number of spurious candidates. In this paper, we propose a lexical simplification framework LSBert based on pretrained representation model Bert, that is capable of (1) making use of the wider context when both detecting the words in need of simplification and generating substitue candidates, and (2) taking five high-quality features into account for ranking candidates, including Bert prediction order, Bert-based language model, and the paraphrase database PPDB, in addition to the word frequency and word similarity commonly used in other LS methods. We show that our system outputs lexical simplifications that are grammatically correct and semantically appropriate, and obtains obvious improvement compared with these baselines, outperforming the state-of-the-art by 29.8 Accuracy points on three well-known benchmarks.
A Simple BERT-Based Approach for Lexical Simplification
Aug 16, 2019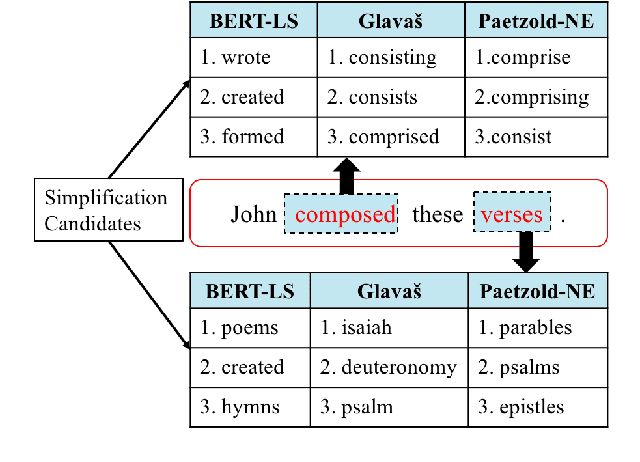
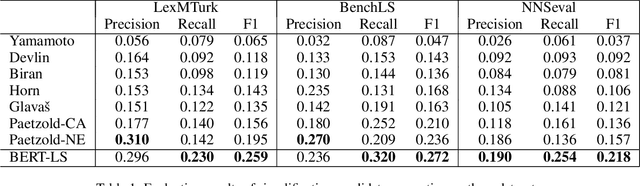
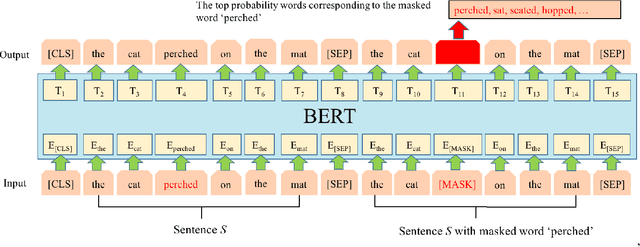
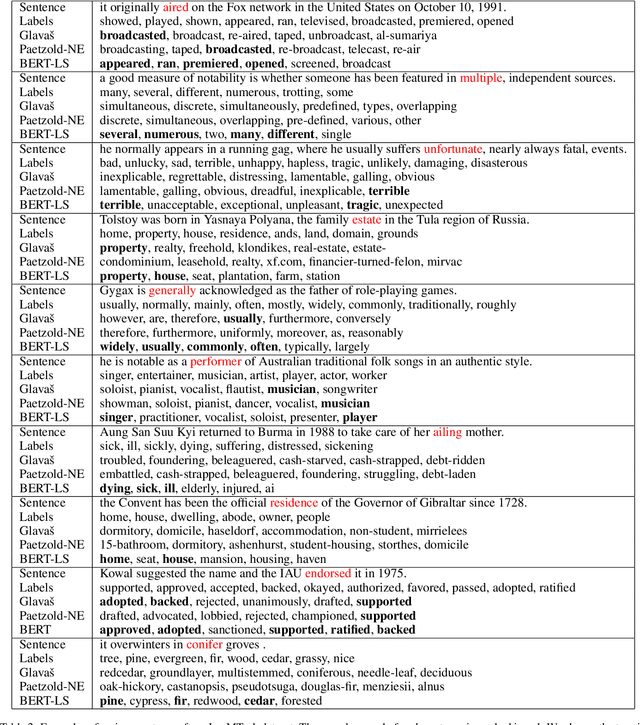
Lexical simplification (LS) aims to replace complex words in a given sentence with their simpler alternatives of equivalent meaning. Recently unsupervised lexical simplification approaches only rely on the complex word itself regardless of the given sentence to generate candidate substitutions, which will inevitably produce a large number of spurious candidates. We present a simple BERT-based LS approach that makes use of the pre-trained unsupervised deep bidirectional representations BERT. Despite being entirely unsupervised, experimental results show that our approach obtains obvious improvement than these baselines leveraging linguistic databases and parallel corpus, outperforming the state-of-the-art by more than 11 Accuracy points on three well-known benchmarks.
Improving Neural Text Simplification Model with Simplified Corpora
Oct 10, 2018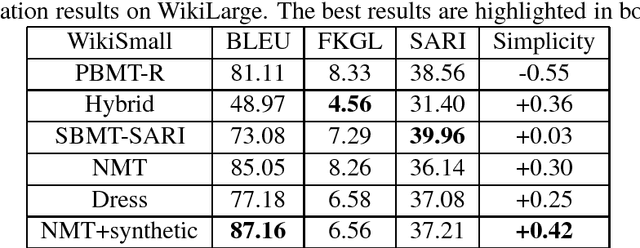
Text simplification (TS) can be viewed as monolingual translation task, translating between text variations within a single language. Recent neural TS models draw on insights from neural machine translation to learn lexical simplification and content reduction using encoder-decoder model. But different from neural machine translation, we cannot obtain enough ordinary and simplified sentence pairs for TS, which are expensive and time-consuming to build. Target-side simplified sentences plays an important role in boosting fluency for statistical TS, and we investigate the use of simplified sentences to train, with no changes to the network architecture. We propose to pair simple training sentence with a synthetic ordinary sentence via back-translation, and treating this synthetic data as additional training data. We train encoder-decoder model using synthetic sentence pairs and original sentence pairs, which can obtain substantial improvements on the available WikiLarge data and WikiSmall data compared with the state-of-the-art methods.