 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Fraudster: Adversarial Attacks on Graph Neural Network Based Vertical Federated Learning
Oct 13, 2021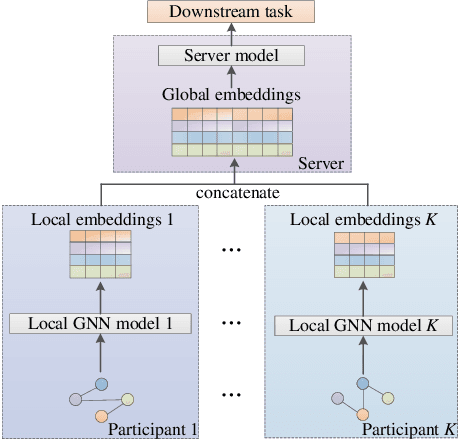
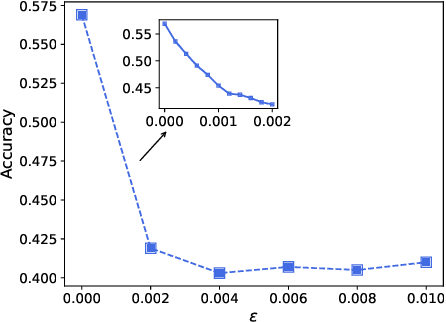
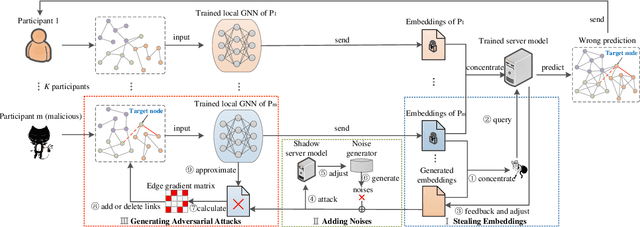
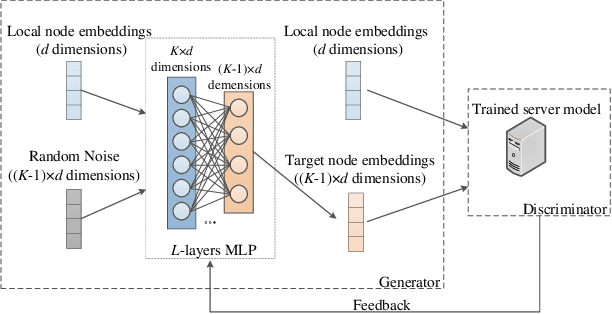
Graph neural network (GNN) models have achieved great success on graph representation learning. Challenged by large scale private data collection from user-side, GNN models may not be able to reflect the excellent performance, without rich features and complete adjacent relationships. Addressing to the problem, vertical federated learning (VFL) is proposed to implement local data protection through training a global model collaboratively. Consequently, for graph-structured data, it is natural idea to construct VFL framework with GNN models. However, GNN models are proven to be vulnerable to adversarial attacks. Whether the vulnerability will be brought into the VFL has not been studied. In this paper, we devote to study the security issues of GNN based VFL (GVFL), i.e., robustness against adversarial attacks. Further, we propose an adversarial attack method, named Graph-Fraudster. It generates adversarial perturbations based on the noise-added global node embeddings via GVFL's privacy leakage, and the gradient of pairwise node. First, it steals the global node embeddings and sets up a shadow server model for attack generator. Second, noises are added into node embeddings to confuse the shadow server model. At last, the gradient of pairwise node is used to generate attacks with the guidance of noise-added node embeddings. To the best of our knowledge, this is the first study of adversarial attacks on GVFL. The extensive experiments on five benchmark datasets demonstrate that Graph-Fraudster performs better than three possible baselines in GVFL. Furthermore, Graph-Fraudster can remain a threat to GVFL even if two possible defense mechanisms are applied. This paper reveals that GVFL is vulnerable to adversarial attack similar to centralized GNN models.
Dyn-Backdoor: Backdoor Attack on Dynamic Link Prediction
Oct 08, 2021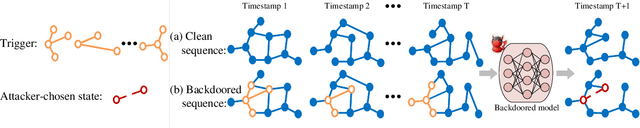
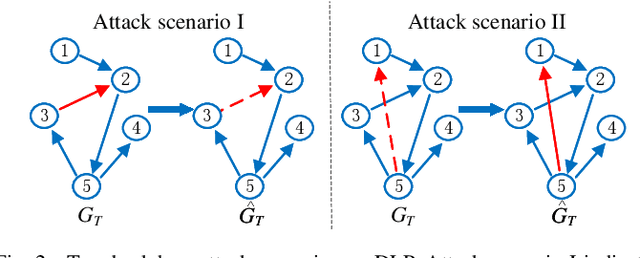
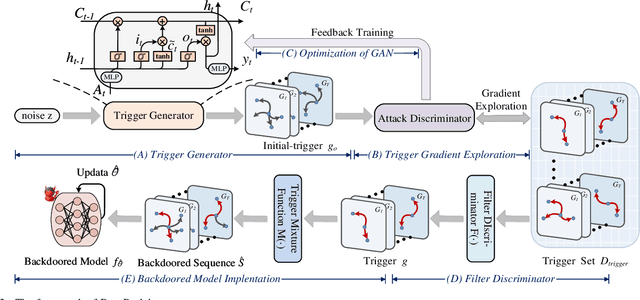
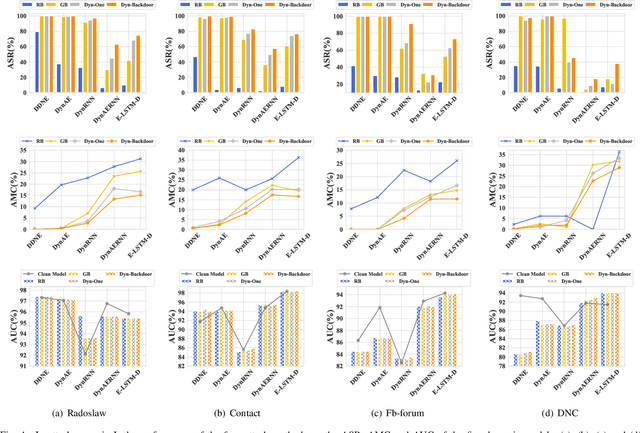
Dynamic link prediction (DLP) makes graph prediction based on historical information. Since most DLP methods are highly dependent on the training data to achieve satisfying prediction performance, the quality of the training data is crucial. Backdoor attacks induce the DLP methods to make wrong prediction by the malicious training data, i.e., generating a subgraph sequence as the trigger and embedding it to the training data. However, the vulnerability of DLP toward backdoor attacks has not been studied yet. To address the issue, we propose a novel backdoor attack framework on DLP, denoted as Dyn-Backdoor. Specifically, Dyn-Backdoor generates diverse initial-triggers by a generative adversarial network (GAN). Then partial links of the initial-triggers are selected to form a trigger set, according to the gradient information of the attack discriminator in the GAN, so as to reduce the size of triggers and improve the concealment of the attack. Experimental results show that Dyn-Backdoor launches successful backdoor attacks on the state-of-the-art DLP models with success rate more than 90%. Additionally, we conduct a possible defense against Dyn-Backdoor to testify its resistance in defensive settings, highlighting the needs of defenses for backdoor attacks on DLP.
Blockchain Phishing Scam Detection via Multi-channel Graph Classification
Aug 19, 2021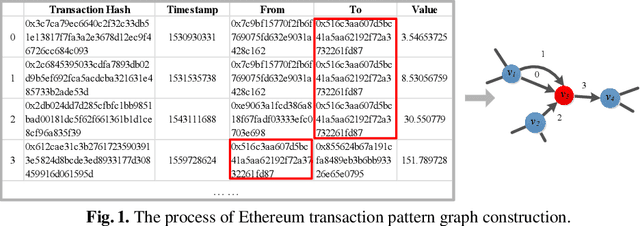
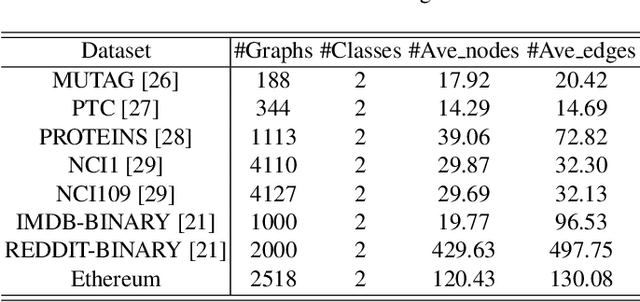
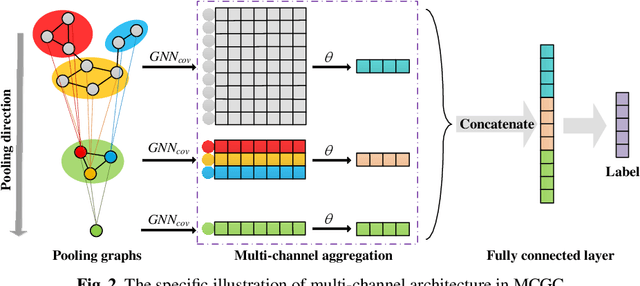
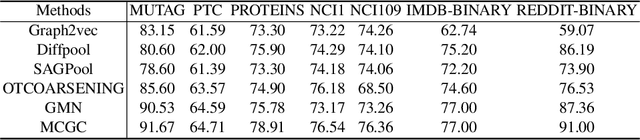
With the popularity of blockchain technology, the financial security issues of blockchain transaction networks have become increasingly serious. Phishing scam detection methods will protect possible victims and build a healthier blockchain ecosystem. Usually, the existing works define phishing scam detection as a node classification task by learning the potential features of users through graph embedding methods such as random walk or graph neural network (GNN). However, these detection methods are suffered from high complexity due to the large scale of the blockchain transaction network, ignoring temporal information of the transaction. Addressing this problem, we defined the transaction pattern graphs for users and transformed the phishing scam detection into a graph classification task. To extract richer information from the input graph, we proposed a multi-channel graph classification model (MCGC) with multiple feature extraction channels for GNN. The transaction pattern graphs and MCGC are more able to detect potential phishing scammers by extracting the transaction pattern features of the target users. Extensive experiments on seven benchmark and Ethereum datasets demonstrate that the proposed MCGC can not only achieve state-of-the-art performance in the graph classification task but also achieve effective phishing scam detection based on the target users' transaction pattern graphs.
EGC2: Enhanced Graph Classification with Easy Graph Compression
Jul 16, 2021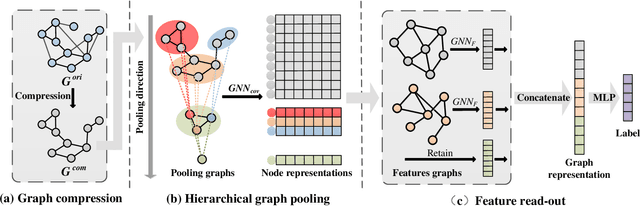
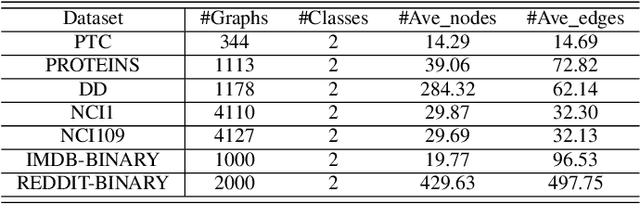
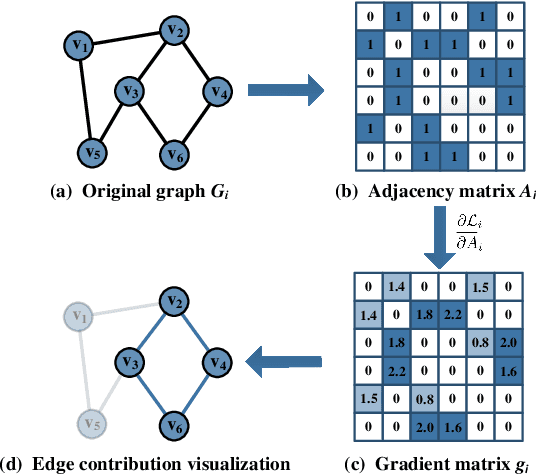
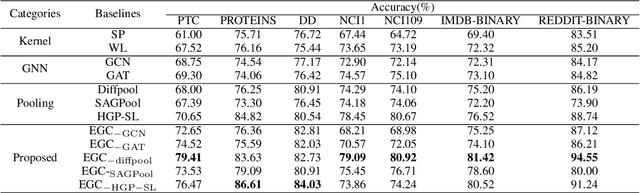
Graph classification plays a significant role in network analysis. It also faces potential security threat like adversarial attacks. Some defense methods may sacrifice algorithm complexity for robustness like adversarial training, while others may sacrifice the clean example performance such as smoothing-based defense. Most of them are suffered from high-complexity or less transferability. To address this problem, we proposed EGC$^2$, an enhanced graph classification model with easy graph compression. EGC$^2$ captures the relationship between features of different nodes by constructing feature graphs and improving aggregate node-level representation. To achieve lower complexity defense applied to various graph classification models, EGC$^2$ utilizes a centrality-based edge importance index to compress graphs, filtering out trivial structures and even adversarial perturbations of the input graphs, thus improves its robustness. Experiments on seven benchmark datasets demonstrate that the proposed feature read-out and graph compression mechanisms enhance the robustness of various basic models, thus achieving the state-of-the-art performance of accuracy and robustness in the threat of different adversarial attacks.
Salient Feature Extractor for Adversarial Defense on Deep Neural Networks
May 14, 2021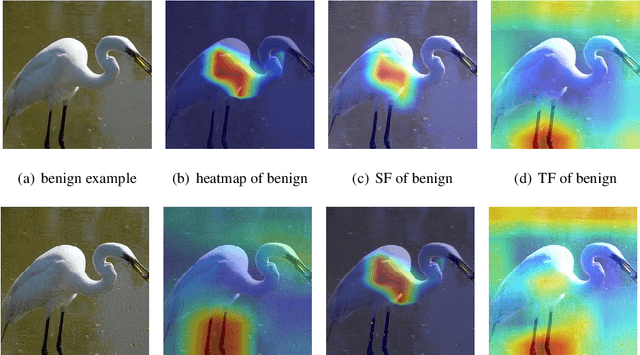

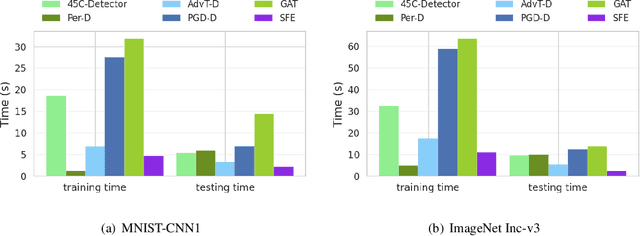
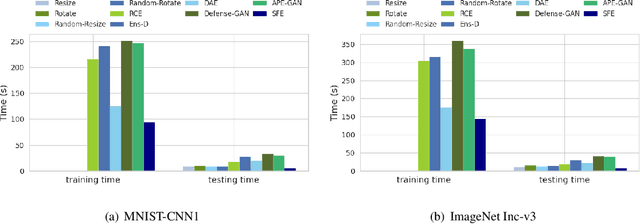
Recent years have witnessed unprecedented success achieved by deep learning models in the field of computer vision. However, their vulnerability towards carefully crafted adversarial examples has also attracted the increasing attention of researchers. Motivated by the observation that adversarial examples are due to the non-robust feature learned from the original dataset by models, we propose the concepts of salient feature(SF) and trivial feature(TF). The former represents the class-related feature, while the latter is usually adopted to mislead the model. We extract these two features with coupled generative adversarial network model and put forward a novel detection and defense method named salient feature extractor (SFE) to defend against adversarial attacks. Concretely, detection is realized by separating and comparing the difference between SF and TF of the input. At the same time, correct labels are obtained by re-identifying SF to reach the purpose of defense. Extensive experiments are carried out on MNIST, CIFAR-10, and ImageNet datasets where SFE shows state-of-the-art results in effectiveness and efficiency compared with baselines. Furthermore, we provide an interpretable understanding of the defense and detection process.
MASS: Multi-task Anthropomorphic Speech Synthesis Framework
May 10, 2021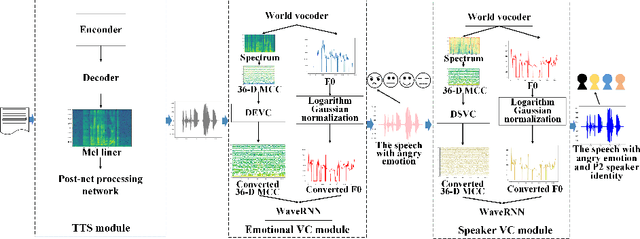
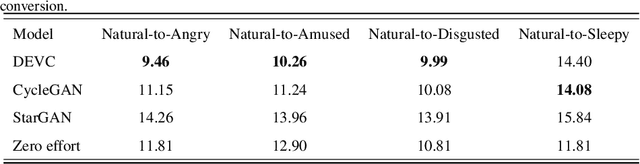
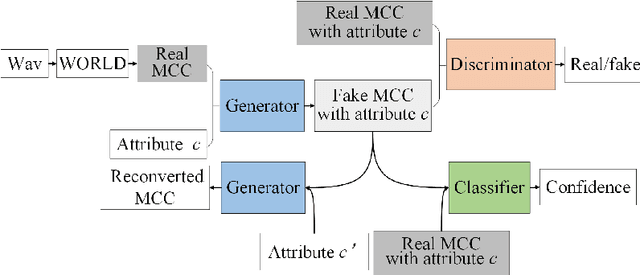
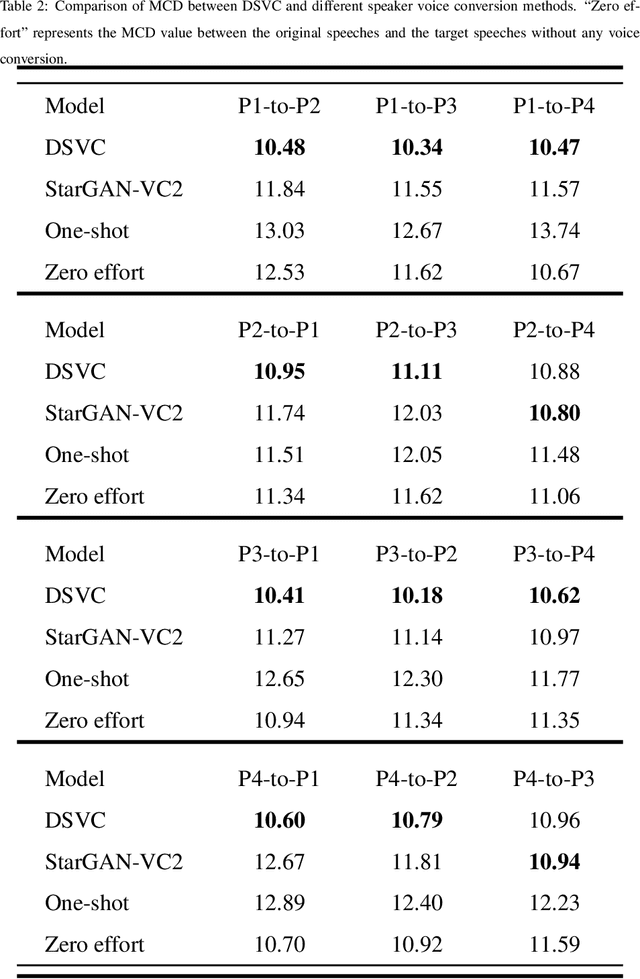
Text-to-Speech (TTS) synthesis plays an important role in human-computer interaction. Currently, most TTS technologies focus on the naturalness of speech, namely,making the speeches sound like humans. However, the key tasks of the expression of emotion and the speaker identity are ignored, which limits the application scenarios of TTS synthesis technology. To make the synthesized speech more realistic and expand the application scenarios, we propose a multi-task anthropomorphic speech synthesis framework (MASS), which can synthesize speeches from text with specified emotion and speaker identity. The MASS framework consists of a base TTS module and two novel voice conversion modules: the emotional voice conversion module and the speaker voice conversion module. We propose deep emotion voice conversion model (DEVC) and deep speaker voice conversion model (DSVC) based on convolution residual networks. It solves the problem of feature loss during voice conversion. The model trainings are independent of parallel datasets, and are capable of many-to-many voice conversion. In the emotional voice conversion, speaker voice conversion experiments, as well as the multi-task speech synthesis experiments, experimental results show DEVC and DSVC convert speech effectively. The quantitative and qualitative evaluation results of multi-task speech synthesis experiments show MASS can effectively synthesis speech with specified text, emotion and speaker identity.
Graphfool: Targeted Label Adversarial Attack on Graph Embedding
Feb 24, 2021
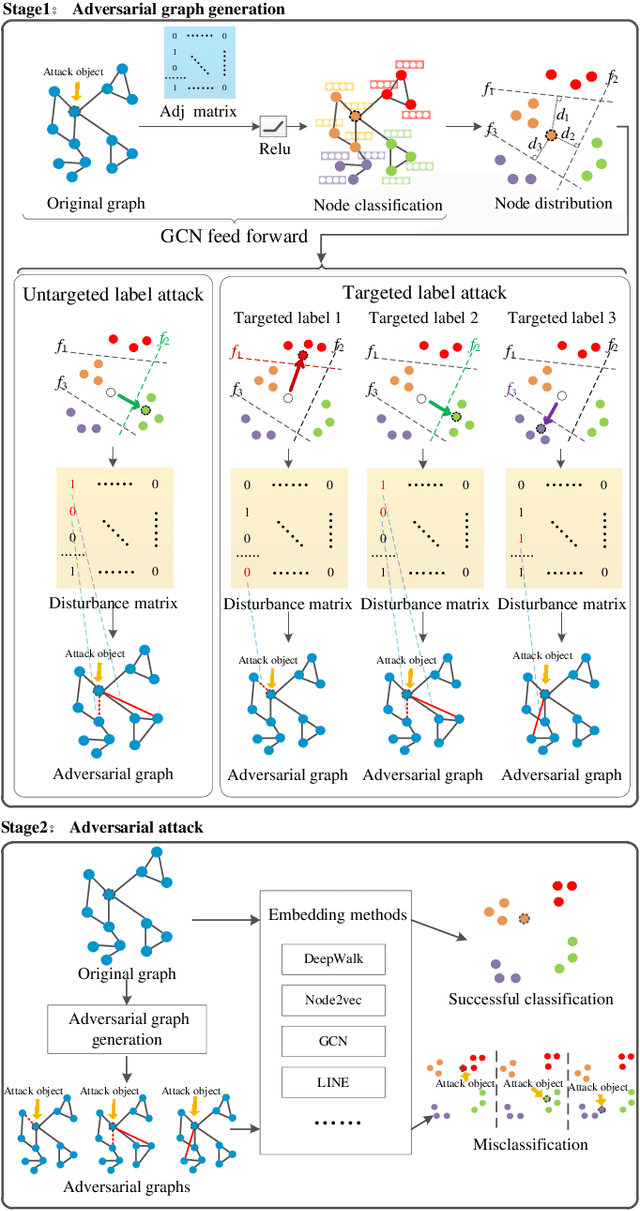
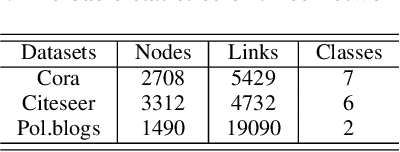
Deep learning is effective in graph analysis. It is widely applied in many related areas, such as link prediction, node classification, community detection, and graph classification etc. Graph embedding, which learns low-dimensional representations for vertices or edges in the graph, usually employs deep models to derive the embedding vector. However, these models are vulnerable. We envision that graph embedding methods based on deep models can be easily attacked using adversarial examples. Thus, in this paper, we propose Graphfool, a novel targeted label adversarial attack on graph embedding. It can generate adversarial graph to attack graph embedding methods via classifying boundary and gradient information in graph convolutional network (GCN). Specifically, we perform the following steps: 1),We first estimate the classification boundaries of different classes. 2), We calculate the minimal perturbation matrix to misclassify the attacked vertex according to the target classification boundary. 3), We modify the adjacency matrix according to the maximal absolute value of the disturbance matrix. This process is implemented iteratively. To the best of our knowledge, this is the first targeted label attack technique. The experiments on real-world graph networks demonstrate that Graphfool can derive better performance than state-of-art techniques. Compared with the second best algorithm, Graphfool can achieve an average improvement of 11.44% in attack success rate.
GraphAttacker: A General Multi-Task GraphAttack Framework
Jan 18, 2021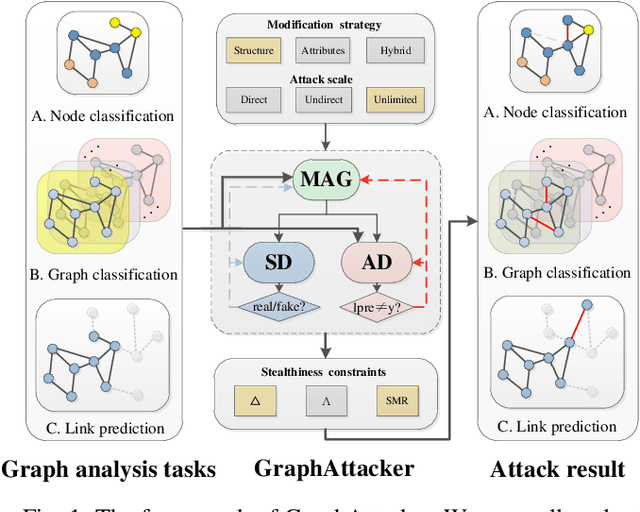
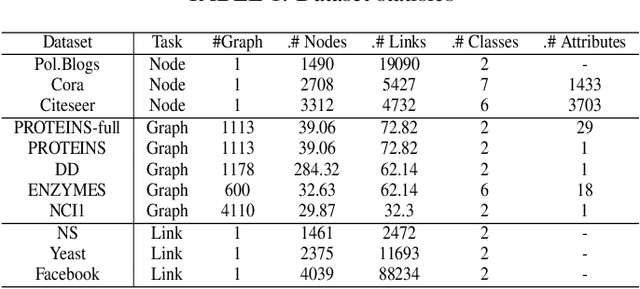
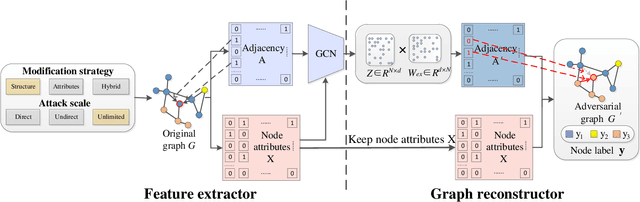
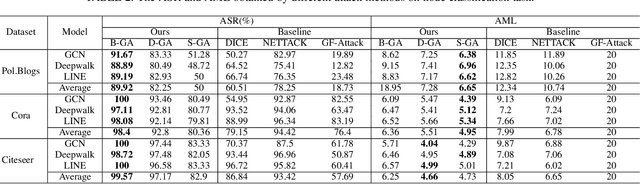
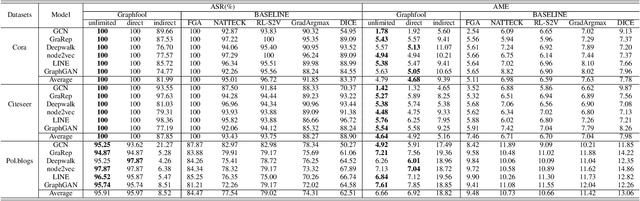
Graph Neural Networks (GNNs) have been successfully exploited in graph analysis tasks in many real-world applications. However, GNNs have been shown to have potential security issues imposed by adversarial samples generated by attackers, which achieved great attack performance with almost imperceptible perturbations. What limit the wide application of these attackers are their methods' specificity on a certain graph analysis task, such as node classification or link prediction. We thus propose GraphAttacker, a novel generic graph attack framework that can flexibly adjust the structures and the attack strategies according to the graph analysis tasks. Based on the Generative Adversarial Network (GAN), GraphAttacker generates adversarial samples through alternate training on three key components, the Multi-strategy Attack Generator (MAG), the Similarity Discriminator (SD), and the Attack Discriminator(AD). Furthermore, to achieve attackers within perturbation budget, we propose a novel Similarity Modification Rate (SMR) to quantify the similarity between nodes thus constrain the attack budget. We carry out extensive experiments and the results show that GraphAttacker can achieve state-of-the-art attack performance on graph analysis tasks of node classification, graph classification, and link prediction. Besides, we also analyze the unique characteristics of each task and their specific response in the unified attack framework. We will release GraphAttacker as an open-source simulation platform for future attack researches.
DeepPoison: Feature Transfer Based Stealthy Poisoning Attack
Jan 08, 2021
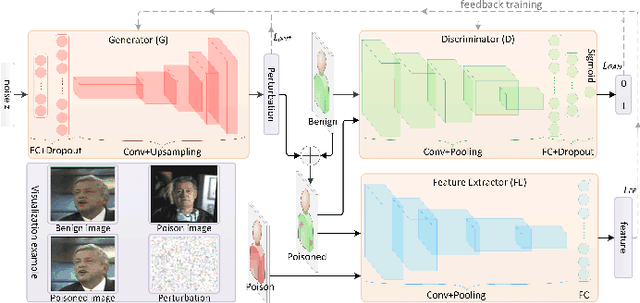
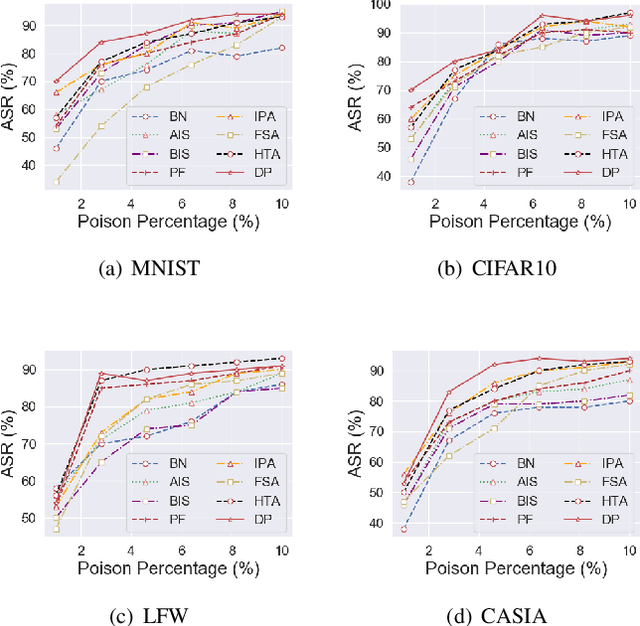
Deep neural networks are susceptible to poisoning attacks by purposely polluted training data with specific triggers. As existing episodes mainly focused on attack success rate with patch-based samples, defense algorithms can easily detect these poisoning samples. We propose DeepPoison, a novel adversarial network of one generator and two discriminators, to address this problem. Specifically, the generator automatically extracts the target class' hidden features and embeds them into benign training samples. One discriminator controls the ratio of the poisoning perturbation. The other discriminator works as the target model to testify the poisoning effects. The novelty of DeepPoison lies in that the generated poisoned training samples are indistinguishable from the benign ones by both defensive methods and manual visual inspection, and even benign test samples can achieve the attack. Extensive experiments have shown that DeepPoison can achieve a state-of-the-art attack success rate, as high as 91.74%, with only 7% poisoned samples on publicly available datasets LFW and CASIA. Furthermore, we have experimented with high-performance defense algorithms such as autodecoder defense and DBSCAN cluster detection and showed the resilience of DeepPoison.
ROBY: Evaluating the Robustness of a Deep Model by its Decision Boundaries
Dec 18, 2020
With the successful application of deep learning models in many real-world tasks, the model robustness becomes more and more critical. Often, we evaluate the robustness of the deep models by attacking them with purposely generated adversarial samples, which is computationally costly and dependent on the specific attackers and the model types. This work proposes a generic evaluation metric ROBY, a novel attack-independent robustness measure based on the model's decision boundaries. Independent of adversarial samples, ROBY uses the inter-class and intra-class statistic features to capture the features of the model's decision boundaries. We experimented on ten state-of-the-art deep models and showed that ROBY matches the robustness gold standard of attack success rate (ASR) by a strong first-order generic attacker. with only 1% of time cost. To the best of our knowledge, ROBY is the first lightweight attack-independent robustness evaluation metric that can be applied to a wide range of deep models. The code of ROBY is open sourced at https://github.com/baaaad/ROBY-Evaluating-the-Robustness-of-a-Deep-Model-by-its-Decision-Boundaries.