 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency and Monotonicity Regularization for Neural Knowledge Tracing
May 03, 2021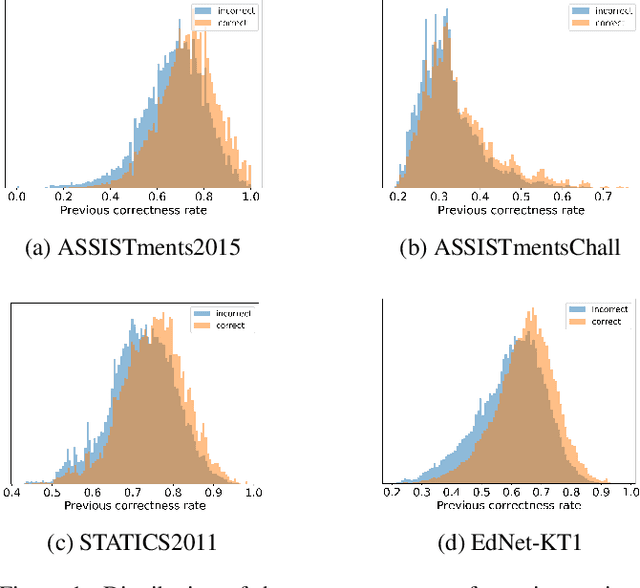
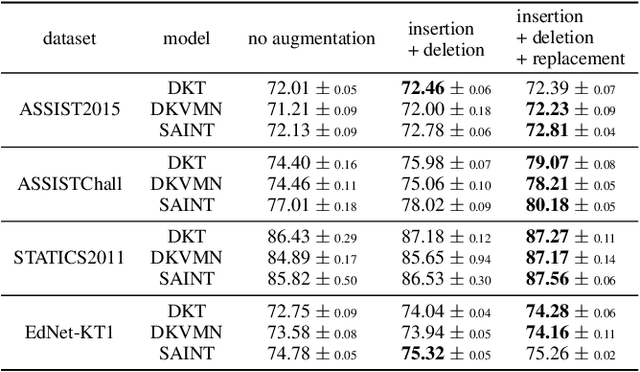

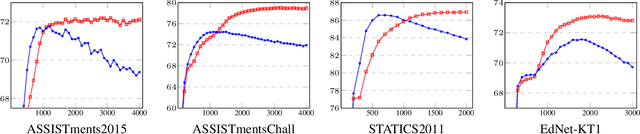
Knowledge Tracing (KT), tracking a human's knowledge acquisition, is a central component in online learning and AI in Education. In this paper, we present a simple, yet effective strategy to improve the generalization ability of KT models: we propose three types of novel data augmentation, coined replacement, insertion, and deletion, along with corresponding regularization losses that impose certain consistency or monotonicity biases on the model's predictions for the original and augmented sequence. Extensive experiments on various KT benchmarks show that our regularization scheme consistently improves the model performances, under 3 widely-used neural networks and 4 public benchmarks, e.g., it yields 6.3% improvement in AUC under the DKT model and the ASSISTmentsChall dataset.
Random Features for the Neural Tangent Kernel
Apr 03, 2021
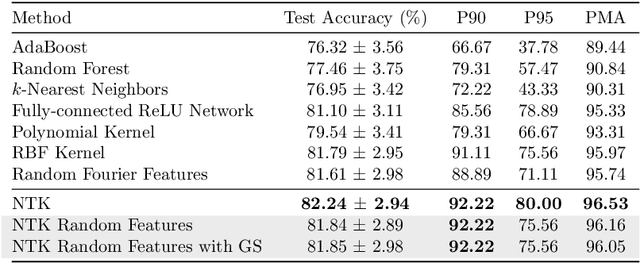
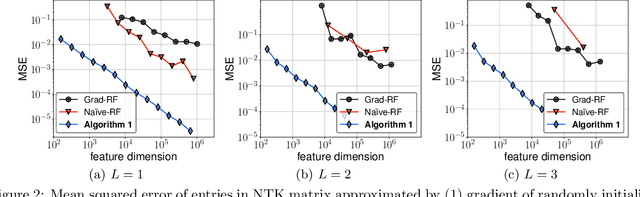
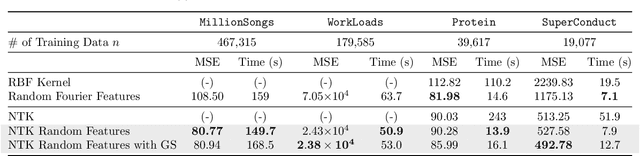
The Neural Tangent Kernel (NTK) has discovered connections between deep neural networks and kernel methods with insights of optimization and generalization. Motivated by this, recent works report that NTK can achieve better performances compared to training neural networks on small-scale datasets. However, results under large-scale settings are hardly studied due to the computational limitation of kernel methods. In this work, we propose an efficient feature map construction of the NTK of fully-connected ReLU network which enables us to apply it to large-scale datasets. We combine random features of the arc-cosine kernels with a sketching-based algorithm which can run in linear with respect to both the number of data points and input dimension. We show that dimension of the resulting features is much smaller than other baseline feature map constructions to achieve comparable error bounds both in theory and practice. We additionally utilize the leverage score based sampling for improved bounds of arc-cosine random features and prove a spectral approximation guarantee of the proposed feature map to the NTK matrix of two-layer neural network. We benchmark a variety of machine learning tasks to demonstrate the superiority of the proposed scheme. In particular, our algorithm can run tens of magnitude faster than the exact kernel methods for large-scale settings without performance loss.
Training GANs with Stronger Augmentations via Contrastive Discriminator
Mar 17, 2021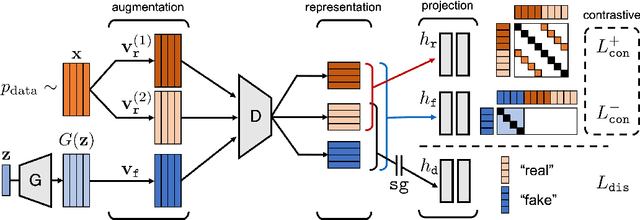
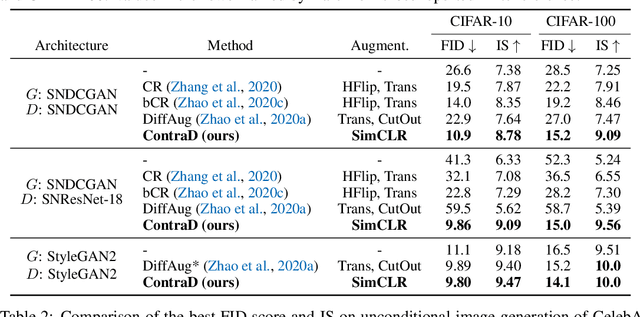


Recent works in Generative Adversarial Networks (GANs) are actively revisiting various data augmentation techniques as an effective way to prevent discriminator overfitting. It is still unclear, however, that which augmentations could actually improve GANs, and in particular, how to apply a wider range of augmentations in training. In this paper, we propose a novel way to address these questions by incorporating a recent contrastive representation learning scheme into the GAN discriminator, coined ContraD. This "fusion" enables the discriminators to work with much stronger augmentations without increasing their training instability, thereby preventing the discriminator overfitting issue in GANs more effectively. Even better, we observe that the contrastive learning itself also benefits from our GAN training, i.e., by maintaining discriminative features between real and fake samples, suggesting a strong coherence between the two worlds: good contrastive representations are also good for GAN discriminators, and vice versa. Our experimental results show that GANs with ContraD consistently improve FID and IS compared to other recent techniques incorporating data augmentations, still maintaining highly discriminative features in the discriminator in terms of the linear evaluation. Finally, as a byproduct, we also show that our GANs trained in an unsupervised manner (without labels) can induce many conditional generative models via a simple latent sampling, leveraging the learned features of ContraD. Code is available at https://github.com/jh-jeong/ContraD.
Consistency Regularization for Adversarial Robustness
Mar 08, 2021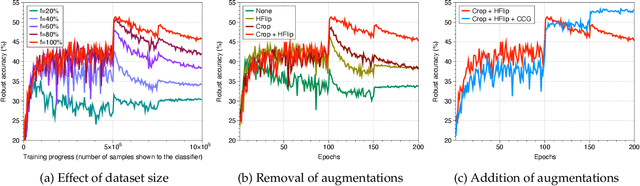
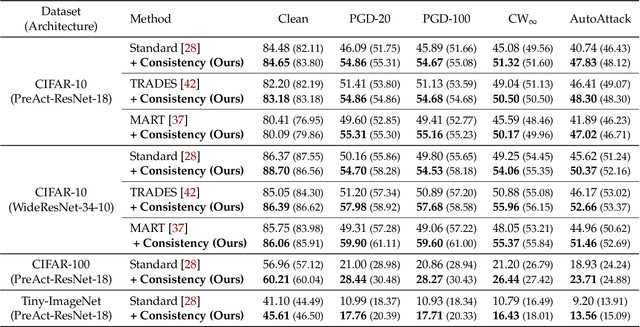

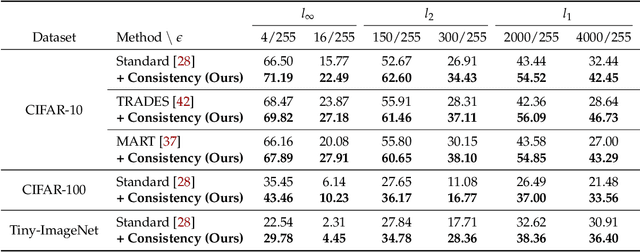
Adversarial training (AT) is currently one of the most successful methods to obtain the adversarial robustness of deep neural networks. However, a significant generalization gap in the robustness obtained from AT has been problematic, making practitioners to consider a bag of tricks for a successful training, e.g., early stopping. In this paper, we investigate data augmentation (DA) techniques to address the issue. In contrast to the previous reports in the literature that DA is not effective for regularizing AT, we discover that DA can mitigate overfitting in AT surprisingly well, but they should be chosen deliberately. To utilize the effect of DA further, we propose a simple yet effective auxiliary 'consistency' regularization loss to optimize, which forces predictive distributions after attacking from two different augmentations to be similar to each other. Our experimental results demonstrate that our simple regularization scheme is applicable for a wide range of AT methods, showing consistent yet significant improvements in the test robust accuracy. More remarkably, we also show that our method could significantly help the model to generalize its robustness against unseen adversaries, e.g., other types or larger perturbations compared to those used during training. Code is available at https://github.com/alinlab/consistency-adversarial.
State Entropy Maximization with Random Encoders for Efficient Exploration
Feb 18, 2021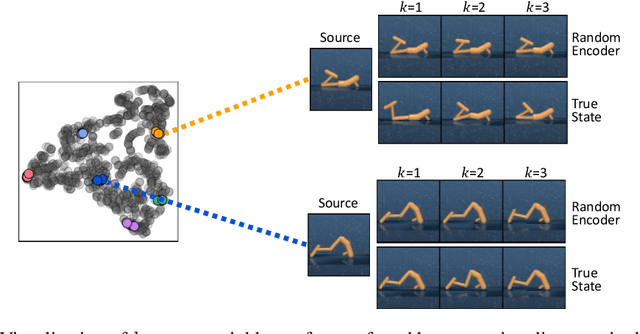
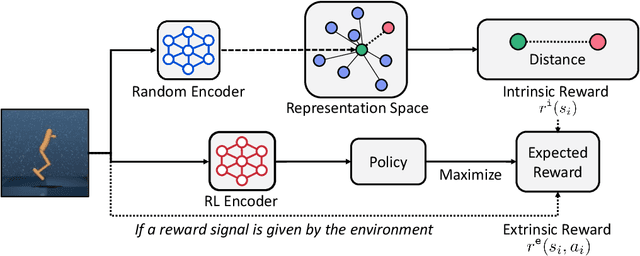

Recent exploration methods have proven to be a recipe for improving sample-efficiency in deep reinforcement learning (RL). However, efficient exploration in high-dimensional observation spaces still remains a challenge. This paper presents Random Encoders for Efficient Exploration (RE3), an exploration method that utilizes state entropy as an intrinsic reward. In order to estimate state entropy in environments with high-dimensional observations, we utilize a k-nearest neighbor entropy estimator in the low-dimensional representation space of a convolutional encoder. In particular, we find that the state entropy can be estimated in a stable and compute-efficient manner by utilizing a randomly initialized encoder, which is fixed throughout training. Our experiments show that RE3 significantly improves the sample-efficiency of both model-free and model-based RL methods on locomotion and navigation tasks from DeepMind Control Suite and MiniGrid benchmarks. We also show that RE3 allows learning diverse behaviors without extrinsic rewards, effectively improving sample-efficiency in downstream tasks. Source code and videos are available at https://sites.google.com/view/re3-rl.
Model-Augmented Q-learning
Feb 07, 2021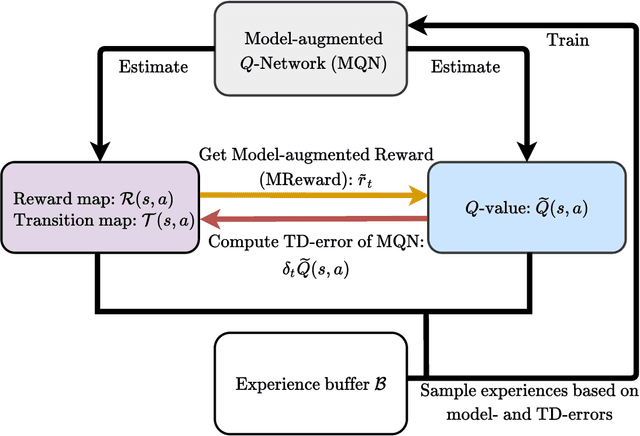
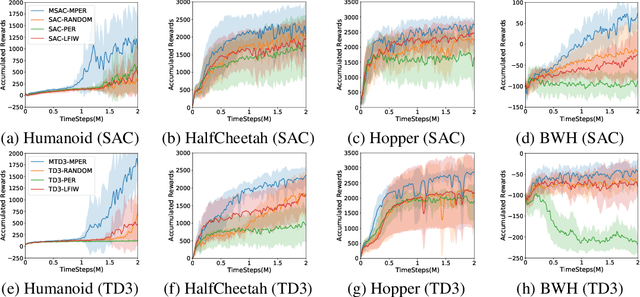
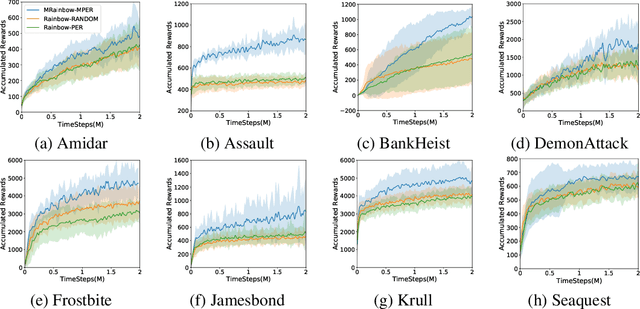
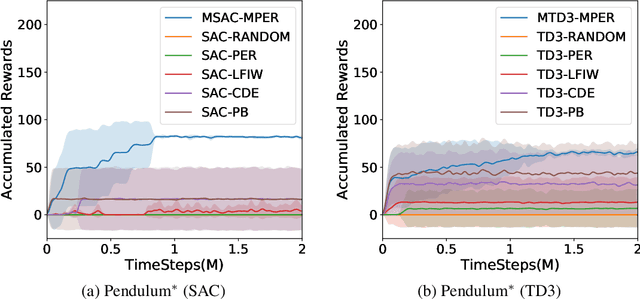
In recent years, $Q$-learning has become indispensable for model-free reinforcement learning (MFRL). However, it suffers from well-known problems such as under- and overestimation bias of the value, which may adversely affect the policy learning. To resolve this issue, we propose a MFRL framework that is augmented with the components of model-based RL. Specifically, we propose to estimate not only the $Q$-values but also both the transition and the reward with a shared network. We further utilize the estimated reward from the model estimators for $Q$-learning, which promotes interaction between the estimators. We show that the proposed scheme, called Model-augmented $Q$-learning (MQL), obtains a policy-invariant solution which is identical to the solution obtained by learning with true reward. Finally, we also provide a trick to prioritize past experiences in the replay buffer by utilizing model-estimation errors. We experimentally validate MQL built upon state-of-the-art off-policy MFRL methods, and show that MQL largely improves their performance and convergence. The proposed scheme is simple to implement and does not require additional training cost.
MASKER: Masked Keyword Regularization for Reliable Text Classification
Dec 17, 2020
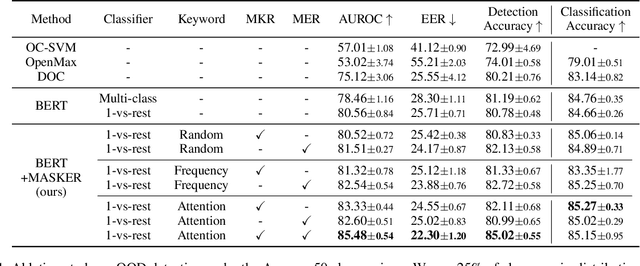
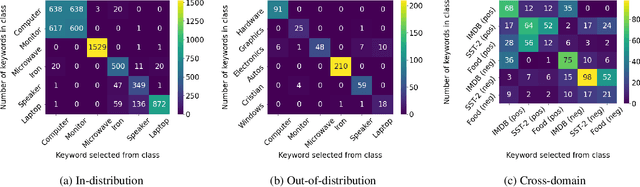
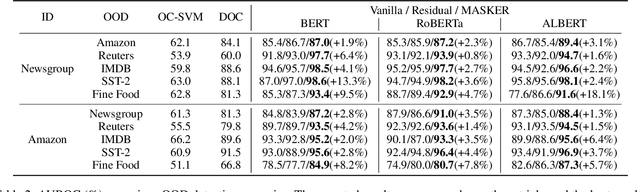
Pre-trained language models have achieved state-of-the-art accuracies on various text classification tasks, e.g., sentiment analysis, natural language inference, and semantic textual similarity. However, the reliability of the fine-tuned text classifiers is an often underlooked performance criterion. For instance, one may desire a model that can detect out-of-distribution (OOD) samples (drawn far from training distribution) or be robust against domain shifts. We claim that one central obstacle to the reliability is the over-reliance of the model on a limited number of keywords, instead of looking at the whole context. In particular, we find that (a) OOD samples often contain in-distribution keywords, while (b) cross-domain samples may not always contain keywords; over-relying on the keywords can be problematic for both cases. In light of this observation, we propose a simple yet effective fine-tuning method, coined masked keyword regularization (MASKER), that facilitates context-based prediction. MASKER regularizes the model to reconstruct the keywords from the rest of the words and make low-confidence predictions without enough context. When applied to various pre-trained language models (e.g., BERT, RoBERTa, and ALBERT), we demonstrate that MASKER improves OOD detection and cross-domain generalization without degrading classification accuracy. Code is available at https://github.com/alinlab/MASKER.
Provable Memorization via Deep Neural Networks using Sub-linear Parameters
Oct 26, 2020
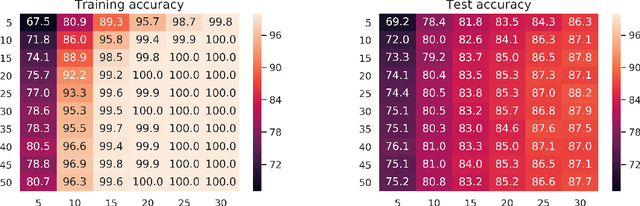
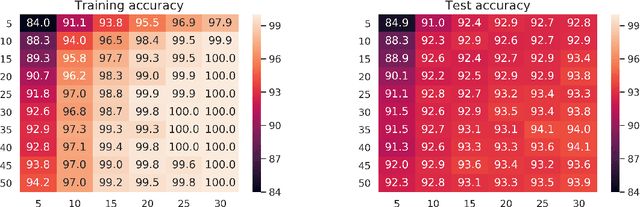
It is known that $\Theta(N)$ parameters are sufficient for neural networks to memorize arbitrary $N$ input-label pairs. By exploiting depth, we show that $\Theta(N^{2/3})$ parameters suffice to memorize $N$ pairs, under a mild condition on the separation of input points. In particular, deeper networks (even with width $3$) are shown to memorize more pairs than shallow networks, which also agrees with the recent line of works on the benefits of depth for function approximation. We also provide empirical results that support our theoretical findings.
Trajectory-wise Multiple Choice Learning for Dynamics Generalization in Reinforcement Learning
Oct 26, 2020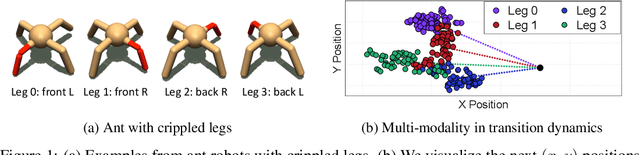
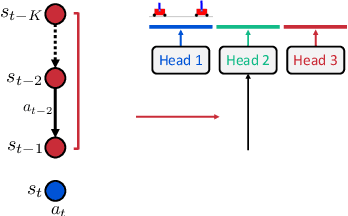
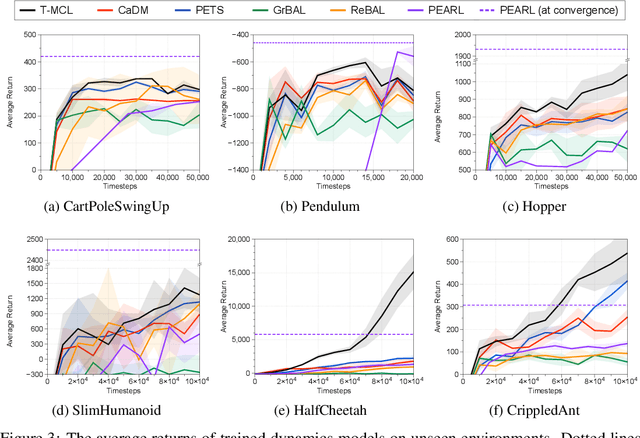

Model-based reinforcement learning (RL) has shown great potential in various control tasks in terms of both sample-efficiency and final performance. However, learning a generalizable dynamics model robust to changes in dynamics remains a challenge since the target transition dynamics follow a multi-modal distribution. In this paper, we present a new model-based RL algorithm, coined trajectory-wise multiple choice learning, that learns a multi-headed dynamics model for dynamics generalization. The main idea is updating the most accurate prediction head to specialize each head in certain environments with similar dynamics, i.e., clustering environments. Moreover, we incorporate context learning, which encodes dynamics-specific information from past experiences into the context latent vector, enabling the model to perform online adaptation to unseen environments. Finally, to utilize the specialized prediction heads more effectively, we propose an adaptive planning method, which selects the most accurate prediction head over a recent experience. Our method exhibits superior zero-shot generalization performance across a variety of control tasks, compared to state-of-the-art RL methods. Source code and videos are available at https://sites.google.com/view/trajectory-mcl.
i-Mix: A Strategy for Regularizing Contrastive Representation Learning
Oct 17, 2020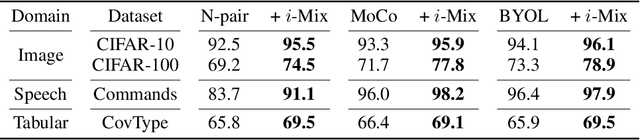
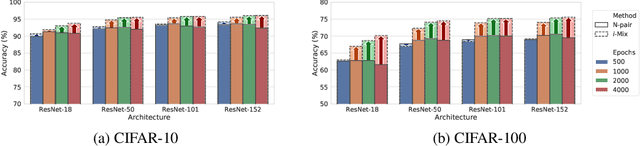
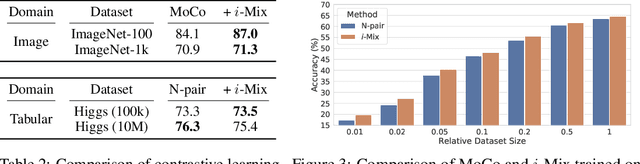

Contrastive representation learning has shown to be an effective way of learning representations from unlabeled data. However, much progress has been made in vision domains relying on data augmentations carefully designed using domain knowledge. In this work, we propose i-Mix, a simple yet effective regularization strategy for improving contrastive representation learning in both vision and non-vision domains. We cast contrastive learning as training a non-parametric classifier by assigning a unique virtual class to each data in a batch. Then, data instances are mixed in both the input and virtual label spaces, providing more augmented data during training. In experiments, we demonstrate that i-Mix consistently improves the quality of self-supervised representations across domains, resulting in significant performance gains on downstream tasks. Furthermore, we confirm its regularization effect via extensive ablation studies across model and dataset sizes.