 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuriosity-Driven Multi-Agent Exploration with Mixed Objectives
Oct 29, 2022



Intrinsic rewards have been increasingly used to mitigate the sparse reward problem in single-agent reinforcement learning. These intrinsic rewards encourage the agent to look for novel experiences, guiding the agent to explore the environment sufficiently despite the lack of extrinsic rewards. Curiosity-driven exploration is a simple yet efficient approach that quantifies this novelty as the prediction error of the agent's curiosity module, an internal neural network that is trained to predict the agent's next state given its current state and action. We show here, however, that naively using this curiosity-driven approach to guide exploration in sparse reward cooperative multi-agent environments does not consistently lead to improved results. Straightforward multi-agent extensions of curiosity-driven exploration take into consideration either individual or collective novelty only and thus, they do not provide a distinct but collaborative intrinsic reward signal that is essential for learning in cooperative multi-agent tasks. In this work, we propose a curiosity-driven multi-agent exploration method that has the mixed objective of motivating the agents to explore the environment in ways that are individually and collectively novel. First, we develop a two-headed curiosity module that is trained to predict the corresponding agent's next observation in the first head and the next joint observation in the second head. Second, we design the intrinsic reward formula to be the sum of the individual and joint prediction errors of this curiosity module. We empirically show that the combination of our curiosity module architecture and intrinsic reward formulation guides multi-agent exploration more efficiently than baseline approaches, thereby providing the best performance boost to MARL algorithms in cooperative navigation environments with sparse rewards.
QOPT: Optimistic Value Function Decentralization for Cooperative Multi-Agent Reinforcement Learning
Jun 22, 2020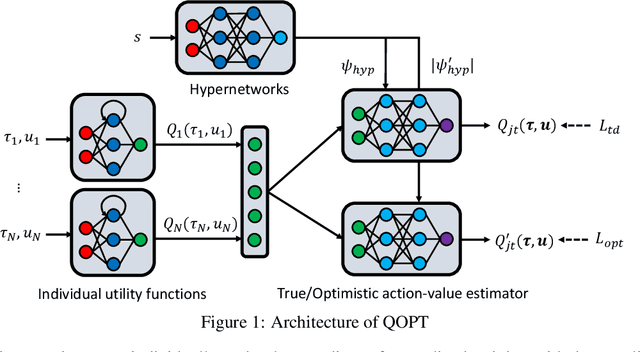

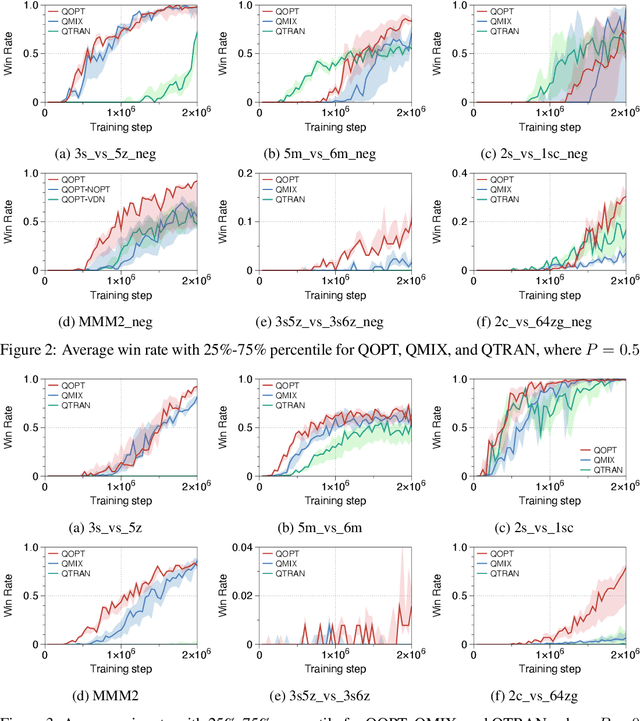
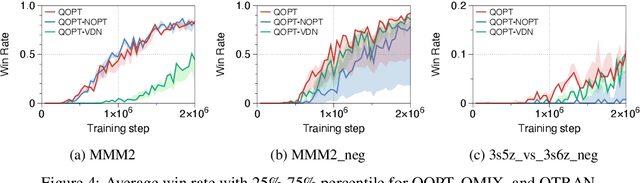
We propose a novel value-based algorithm for cooperative multi-agent reinforcement learning, under the paradigm of centralized training with decentralized execution. The proposed algorithm, coined QOPT, is based on the "optimistic" training scheme using two action-value estimators with separate roles: (i) true action-value estimation and (ii) decentralization of optimal action. By construction, our framework allows the latter action-value estimator to achieve (ii) while representing a richer class of joint action-value estimators than that of the state-of-the-art algorithm, i.e., QMIX. Our experiments demonstrate that QOPT newly achieves state-of-the-art performance in the StarCraft Multi-Agent Challenge environment. In particular, ours significantly outperform the baselines for the case where non-cooperative behaviors are penalized more aggressively.
Enlarging Discriminative Power by Adding an Extra Class in Unsupervised Domain Adaptation
Feb 19, 2020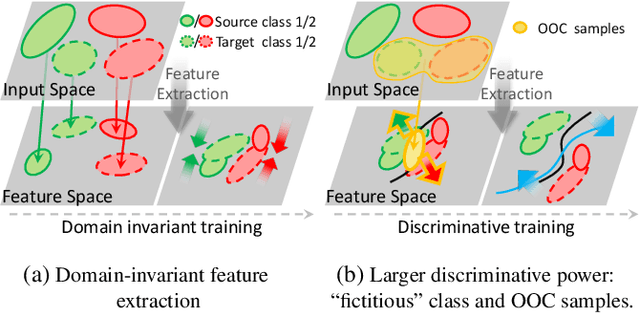
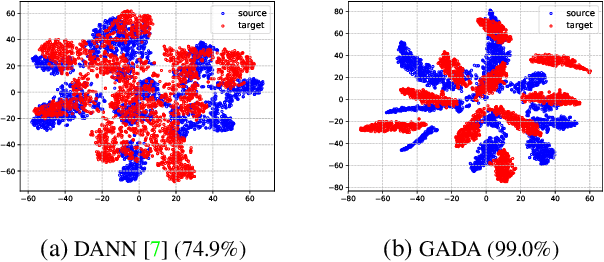
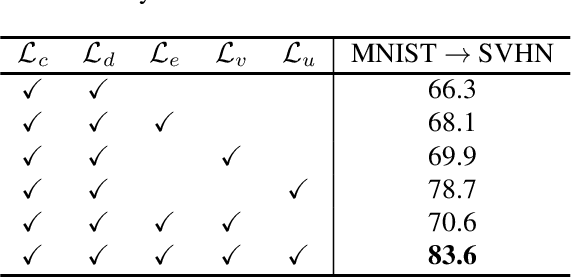
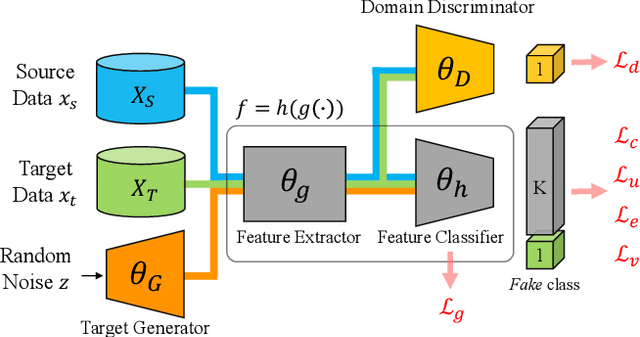
In this paper, we study the problem of unsupervised domain adaptation that aims at obtaining a prediction model for the target domain using labeled data from the source domain and unlabeled data from the target domain. There exists an array of recent research based on the idea of extracting features that are not only invariant for both domains but also provide high discriminative power for the target domain. In this paper, we propose an idea of empowering the discriminativeness: Adding a new, artificial class and training the model on the data together with the GAN-generated samples of the new class. The trained model based on the new class samples is capable of extracting the features that are more discriminative by repositioning data of current classes in the target domain and therefore drawing the decision boundaries more effectively. Our idea is highly generic so that it is compatible with many existing methods such as DANN, VADA, and DIRT-T. We conduct various experiments for the standard data commonly used for the evaluation of unsupervised domain adaptations and demonstrate that our algorithm achieves the SOTA performance for many scenarios.
How Much and When Do We Need Higher-order Information in Hypergraphs? A Case Study on Hyperedge Prediction
Jan 31, 2020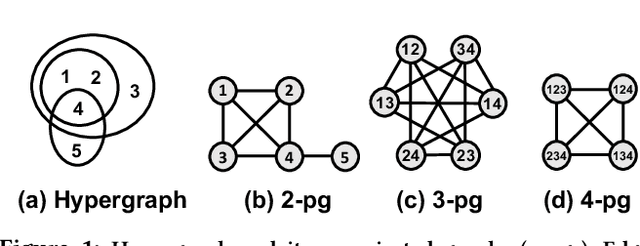
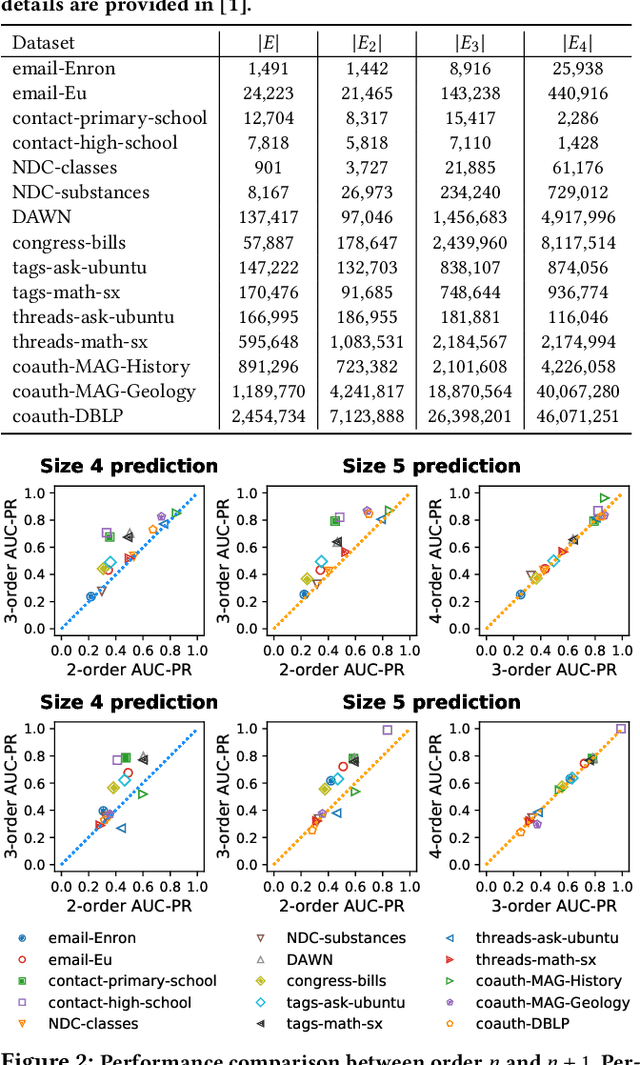
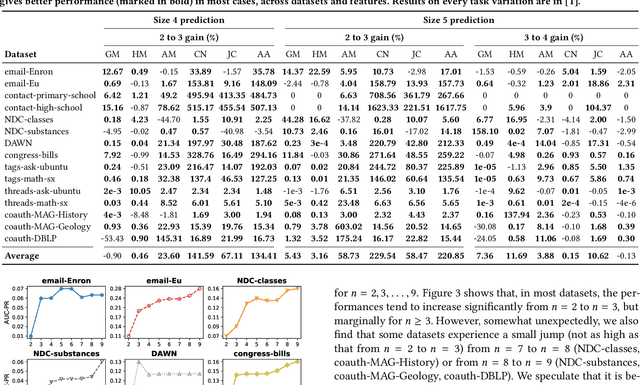
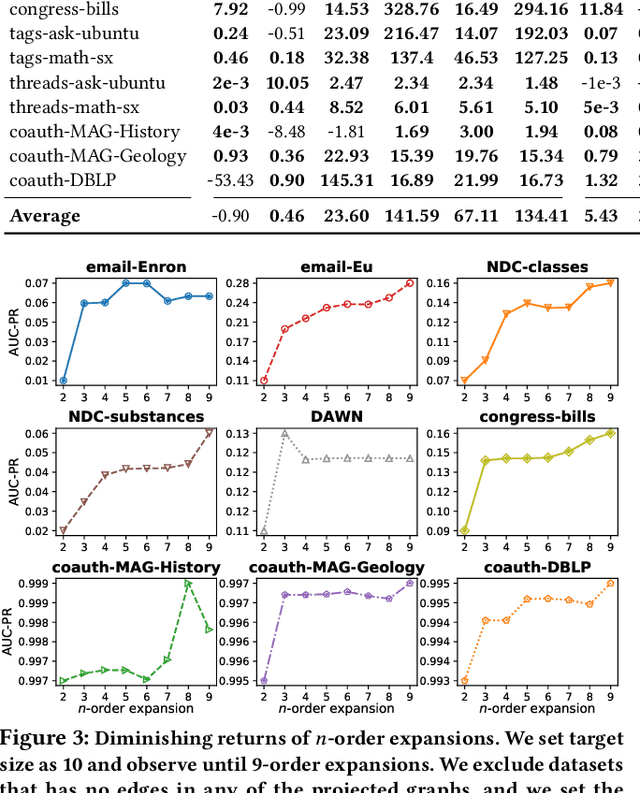
Hypergraphs provide a natural way of representing group relations, whose complexity motivates an extensive array of prior work to adopt some form of abstraction and simplification of higher-order interactions. However, the following question has yet to be addressed: How much abstraction of group interactions is sufficient in solving a hypergraph task, and how different such results become across datasets? This question, if properly answered, provides a useful engineering guideline on how to trade off between complexity and accuracy of solving a downstream task. To this end, we propose a method of incrementally representing group interactions using a notion of n-projected graph whose accumulation contains information on up to n-way interactions, and quantify the accuracy of solving a task as n grows for various datasets. As a downstream task, we consider hyperedge prediction, an extension of link prediction, which is a canonical task for evaluating graph models. Through experiments on 15 real-world datasets, we draw the following messages: (a) Diminishing returns: small n is enough to achieve accuracy comparable with near-perfect approximations, (b) Troubleshooter: as the task becomes more challenging, larger n brings more benefit, and (c) Irreducibility: datasets whose pairwise interactions do not tell much about higher-order interactions lose much accuracy when reduced to pairwise abstractions.
Solving Continual Combinatorial Selection via Deep Reinforcement Learning
Sep 09, 2019

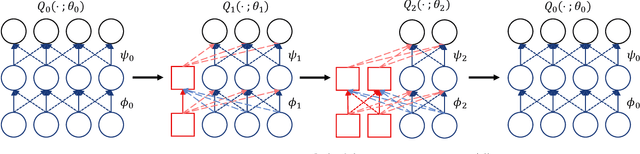
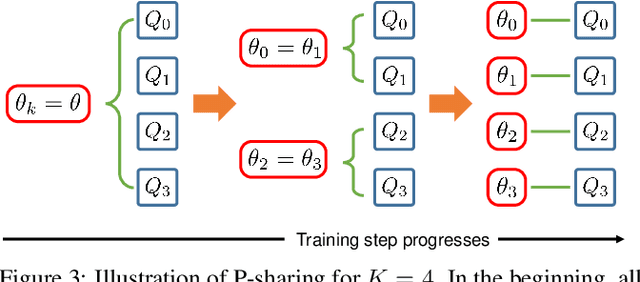
We consider the Markov Decision Process (MDP) of selecting a subset of items at each step, termed the Select-MDP (S-MDP). The large state and action spaces of S-MDPs make them intractable to solve with typical reinforcement learning (RL) algorithms especially when the number of items is huge. In this paper, we present a deep RL algorithm to solve this issue by adopting the following key ideas. First, we convert the original S-MDP into an Iterative Select-MDP (IS-MDP), which is equivalent to the S-MDP in terms of optimal actions. IS-MDP decomposes a joint action of selecting K items simultaneously into K iterative selections resulting in the decrease of actions at the expense of an exponential increase of states. Second, we overcome this state space explo-sion by exploiting a special symmetry in IS-MDPs with novel weight shared Q-networks, which prov-ably maintain sufficient expressive power. Various experiments demonstrate that our approach works well even when the item space is large and that it scales to environments with item spaces different from those used in training.
* Accepted to IJCAI 2019,14 pages,8 figures
QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement Learning
May 14, 2019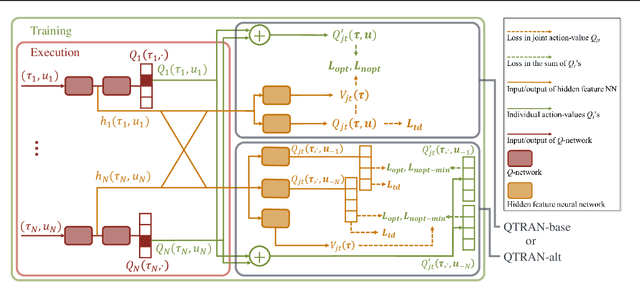
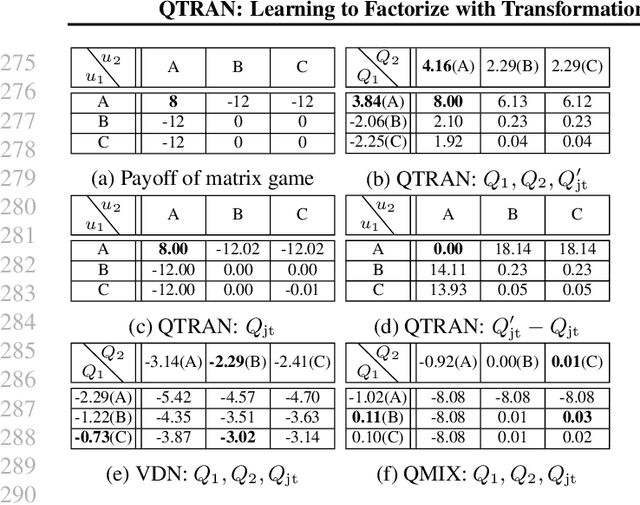
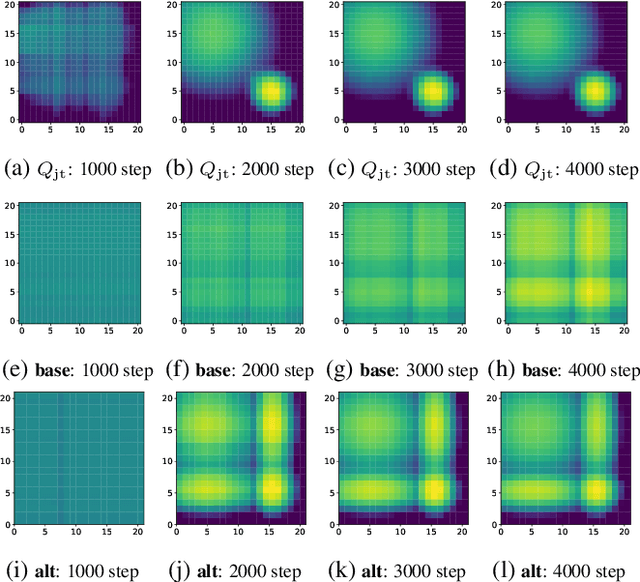
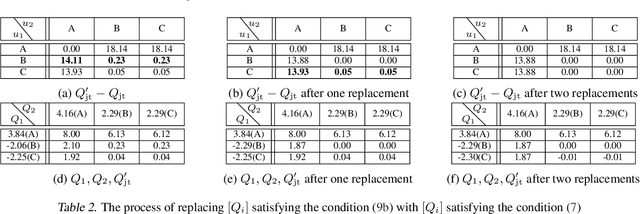
We explore value-based solutions for multi-agent reinforcement learning (MARL) tasks in the centralized training with decentralized execution (CTDE) regime popularized recently. However, VDN and QMIX are representative examples that use the idea of factorization of the joint action-value function into individual ones for decentralized execution. VDN and QMIX address only a fraction of factorizable MARL tasks due to their structural constraint in factorization such as additivity and monotonicity. In this paper, we propose a new factorization method for MARL, QTRAN, which is free from such structural constraints and takes on a new approach to transforming the original joint action-value function into an easily factorizable one, with the same optimal actions. QTRAN guarantees more general factorization than VDN or QMIX, thus covering a much wider class of MARL tasks than does previous methods. Our experiments for the tasks of multi-domain Gaussian-squeeze and modified predator-prey demonstrate QTRAN's superior performance with especially larger margins in games whose payoffs penalize non-cooperative behavior more aggressively.
Learning to Schedule Communication in Multi-agent Reinforcement Learning
Feb 05, 2019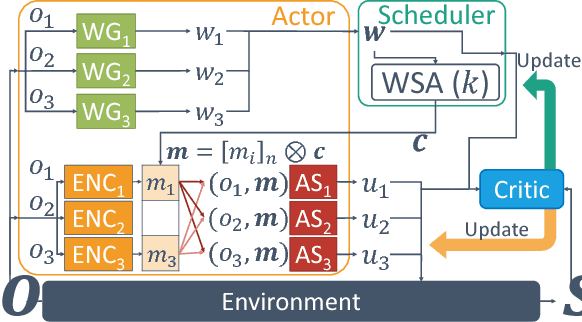

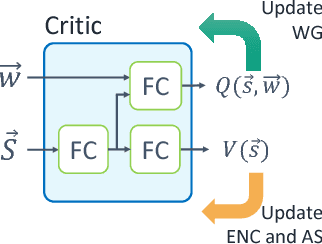

Many real-world reinforcement learning tasks require multiple agents to make sequential decisions under the agents' interaction, where well-coordinated actions among the agents are crucial to achieve the target goal better at these tasks. One way to accelerate the coordination effect is to enable multiple agents to communicate with each other in a distributed manner and behave as a group. In this paper, we study a practical scenario when (i) the communication bandwidth is limited and (ii) the agents share the communication medium so that only a restricted number of agents are able to simultaneously use the medium, as in the state-of-the-art wireless networking standards. This calls for a certain form of communication scheduling. In that regard, we propose a multi-agent deep reinforcement learning framework, called SchedNet, in which agents learn how to schedule themselves, how to encode the messages, and how to select actions based on received messages. SchedNet is capable of deciding which agents should be entitled to broadcasting their (encoded) messages, by learning the importance of each agent's partially observed information. We evaluate SchedNet against multiple baselines under two different applications, namely, cooperative communication and navigation, and predator-prey. Our experiments show a non-negligible performance gap between SchedNet and other mechanisms such as the ones without communication and with vanilla scheduling methods, e.g., round robin, ranging from 32% to 43%.
Iterative Bayesian Learning for Crowdsourced Regression
Oct 08, 2018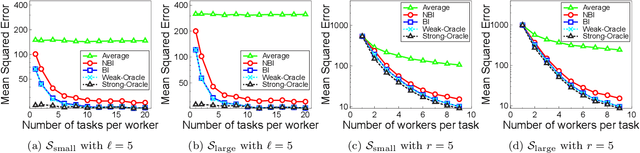

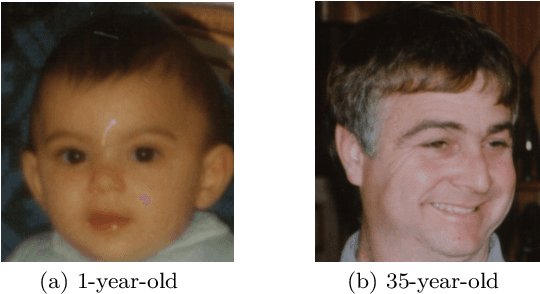
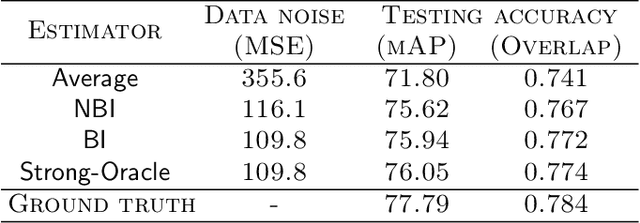
Crowdsourcing platforms emerged as popular venues for purchasing human intelligence at low cost for large volume of tasks. As many low-paid workers are prone to give noisy answers, a common practice is to add redundancy by assigning multiple workers to each task and then simply average out these answers. However, to fully harness the wisdom of the crowd, one needs to learn the heterogeneous quality of each worker. We resolve this fundamental challenge in crowdsourced regression tasks, i.e., the answer takes continuous labels, where identifying good or bad workers becomes much more non-trivial compared to a classification setting of discrete labels. In particular, we introduce a Bayesian iterative scheme and show that it provably achieves the optimal mean squared error. Our evaluations on synthetic and real-world datasets support our theoretical results and show the superiority of the proposed scheme.
Learning Data Dependency with Communication Cost
Apr 29, 2018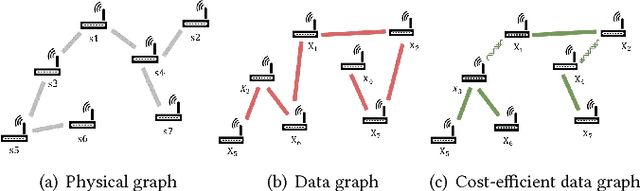
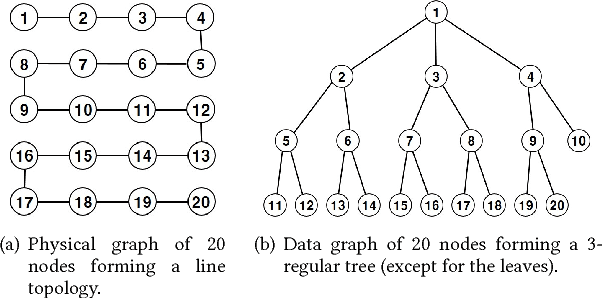
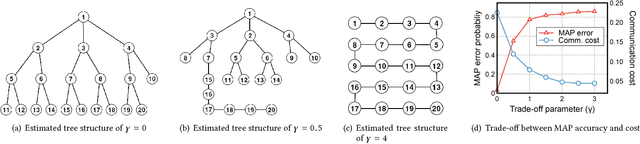
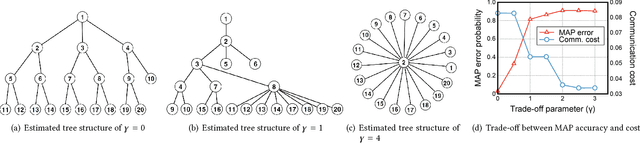
In this paper, we consider the problem of recovering a graph that represents the statistical data dependency among nodes for a set of data samples generated by nodes, which provides the basic structure to perform an inference task, such as MAP (maximum a posteriori). This problem is referred to as structure learning. When nodes are spatially separated in different locations, running an inference algorithm requires a non-negligible amount of message passing, incurring some communication cost. We inevitably have the trade-off between the accuracy of structure learning and the cost we need to pay to perform a given message-passing based inference task because the learnt edge structures of data dependency and physical connectivity graph are often highly different. In this paper, we formalize this trade-off in an optimization problem which outputs the data dependency graph that jointly considers learning accuracy and message-passing costs. We focus on a distributed MAP as the target inference task, and consider two different implementations, ASYNC-MAP and SYNC-MAP that have different message-passing mechanisms and thus different cost structures. In ASYNC- MAP, we propose a polynomial time learning algorithm that is optimal, motivated by the problem of finding a maximum weight spanning tree. In SYNC-MAP, we first prove that it is NP-hard and propose a greedy heuristic. For both implementations, we then quantify how the probability that the resulting data graphs from those learning algorithms differ from the ideal data graph decays as the number of data samples grows, using the large deviation principle, where the decaying rate is characterized by some topological structures of both original data dependency and physical connectivity graphs as well as the degree of the trade-off. We validate our theoretical findings through extensive simulations, which confirms that it has a good match.
Adiabatic Persistent Contrastive Divergence Learning
Feb 14, 2017
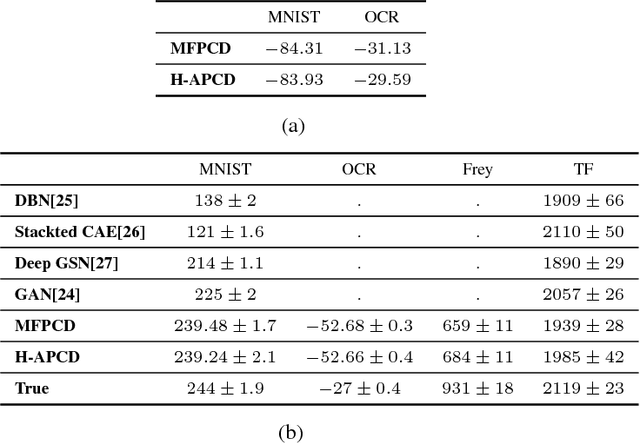
This paper studies the problem of parameter learning in probabilistic graphical models having latent variables, where the standard approach is the expectation maximization algorithm alternating expectation (E) and maximization (M) steps. However, both E and M steps are computationally intractable for high dimensional data, while the substitution of one step to a faster surrogate for combating against intractability can often cause failure in convergence. We propose a new learning algorithm which is computationally efficient and provably ensures convergence to a correct optimum. Its key idea is to run only a few cycles of Markov Chains (MC) in both E and M steps. Such an idea of running incomplete MC has been well studied only for M step in the literature, called Contrastive Divergence (CD) learning. While such known CD-based schemes find approximated gradients of the log-likelihood via the mean-field approach in E step, our proposed algorithm does exact ones via MC algorithms in both steps due to the multi-time-scale stochastic approximation theory. Despite its theoretical guarantee in convergence, the proposed scheme might suffer from the slow mixing of MC in E step. To tackle it, we also propose a hybrid approach applying both mean-field and MC approximation in E step, where the hybrid approach outperforms the bare mean-field CD scheme in our experiments on real-world datasets.