 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Task-Oriented Dialogue Datasets More Natural by Synthetically Generating Indirect User Requests
Jun 16, 2024



Indirect User Requests (IURs), such as "It's cold in here" instead of "Could you please increase the temperature?" are common in human-human task-oriented dialogue and require world knowledge and pragmatic reasoning from the listener. While large language models (LLMs) can handle these requests effectively, smaller models deployed on virtual assistants often struggle due to resource constraints. Moreover, existing task-oriented dialogue benchmarks lack sufficient examples of complex discourse phenomena such as indirectness. To address this, we propose a set of linguistic criteria along with an LLM-based pipeline for generating realistic IURs to test natural language understanding (NLU) and dialogue state tracking (DST) models before deployment in a new domain. We also release IndirectRequests, a dataset of IURs based on the Schema Guided Dialog (SGD) corpus, as a comparative testbed for evaluating the performance of smaller models in handling indirect requests.
IndirectRequests: Making Task-Oriented Dialogue Datasets More Natural by Synthetically Generating Indirect User Requests
Jun 12, 2024Existing benchmark corpora of task-oriented dialogue are collected either using a "machines talking to machines" approach or by giving template-based goal descriptions to crowdworkers. These methods, however, often produce utterances that are markedly different from natural human conversations in which people often convey their preferences in indirect ways, such as through small talk. We term such utterances as Indirect User Requests (IURs). Understanding such utterances demands considerable world knowledge and reasoning capabilities on the listener's part. Our study introduces an LLM-based pipeline to automatically generate realistic, high-quality IURs for a given domain, with the ultimate goal of supporting research in natural language understanding (NLU) and dialogue state tracking (DST) for task-oriented dialogue systems. Our findings show that while large LLMs such as GPT-3.5 and GPT-4 generate high-quality IURs, achieving similar quality with smaller models is more challenging. We release IndirectRequests, a dataset of IURs that advances beyond the initial Schema-Guided Dialog (SGD) dataset in that it provides a challenging testbed for testing the "in the wild" performance of NLU and DST models.
Scalable and Robust Self-Learning for Skill Routing in Large-Scale Conversational AI Systems
Apr 14, 2022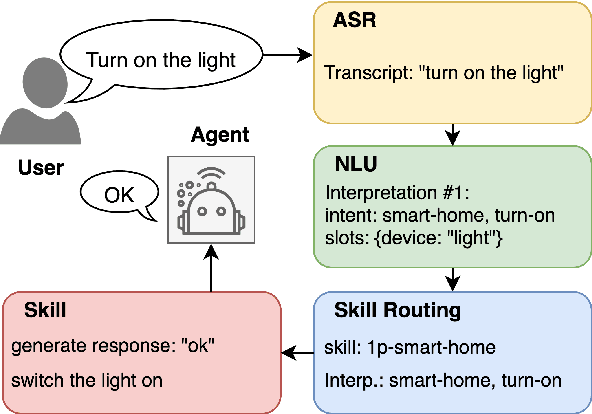
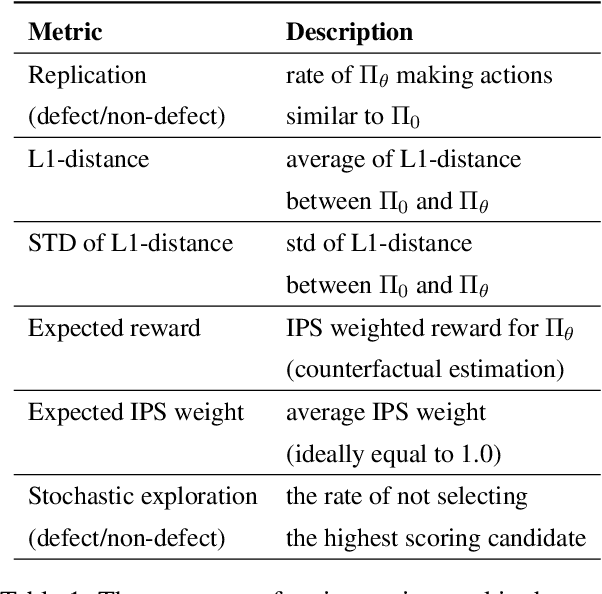
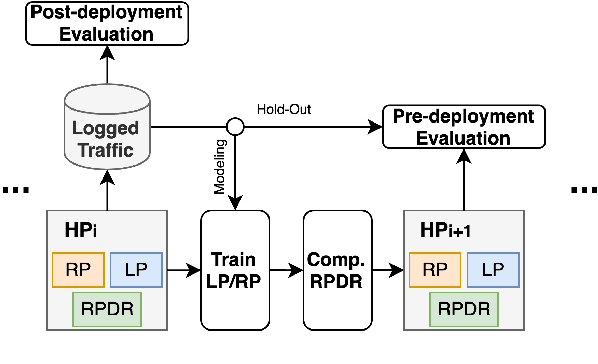
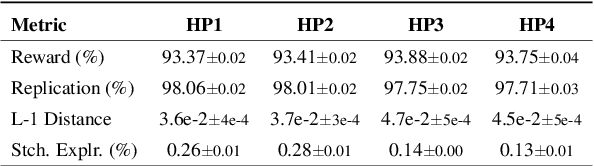
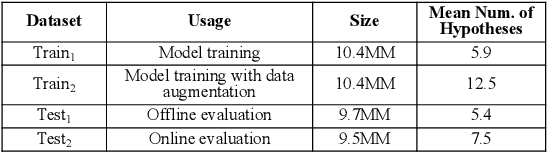
Skill routing is an important component in large-scale conversational systems. In contrast to traditional rule-based skill routing, state-of-the-art systems use a model-based approach to enable natural conversations. To provide supervision signal required to train such models, ideas such as human annotation, replication of a rule-based system, relabeling based on user paraphrases, and bandit-based learning were suggested. However, these approaches: (a) do not scale in terms of the number of skills and skill on-boarding, (b) require a very costly expert annotation/rule-design, (c) introduce risks in the user experience with each model update. In this paper, we present a scalable self-learning approach to explore routing alternatives without causing abrupt policy changes that break the user experience, learn from the user interaction, and incrementally improve the routing via frequent model refreshes. To enable such robust frequent model updates, we suggest a simple and effective approach that ensures controlled policy updates for individual domains, followed by an off-policy evaluation for making deployment decisions without any need for lengthy A/B experimentation. We conduct various offline and online A/B experiments on a commercial large-scale conversational system to demonstrate the effectiveness of the proposed method in real-world production settings.
Neural model robustness for skill routing in large-scale conversational AI systems: A design choice exploration
Mar 04, 2021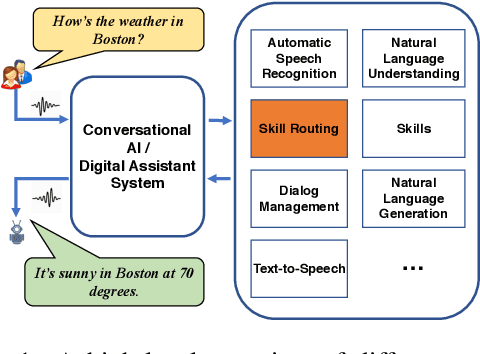
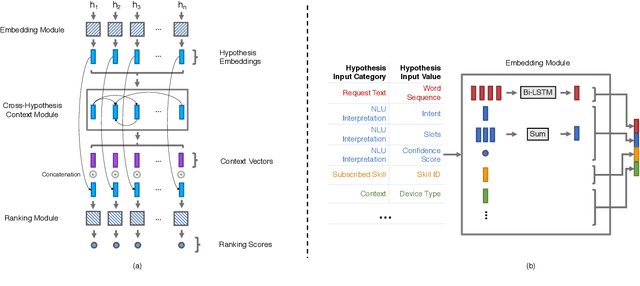
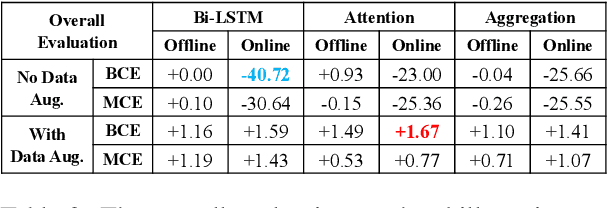
Current state-of-the-art large-scale conversational AI or intelligent digital assistant systems in industry comprises a set of components such as Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU). For some of these systems that leverage a shared NLU ontology (e.g., a centralized intent/slot schema), there exists a separate skill routing component to correctly route a request to an appropriate skill, which is either a first-party or third-party application that actually executes on a user request. The skill routing component is needed as there are thousands of skills that can either subscribe to the same intent and/or subscribe to an intent under specific contextual conditions (e.g., device has a screen). Ensuring model robustness or resilience in the skill routing component is an important problem since skills may dynamically change their subscription in the ontology after the skill routing model has been deployed to production. We show how different modeling design choices impact the model robustness in the context of skill routing on a state-of-the-art commercial conversational AI system, specifically on the choices around data augmentation, model architecture, and optimization method. We show that applying data augmentation can be a very effective and practical way to drastically improve model robustness.
On Learning Vector Representations in Hierarchical Label Spaces
Apr 16, 2015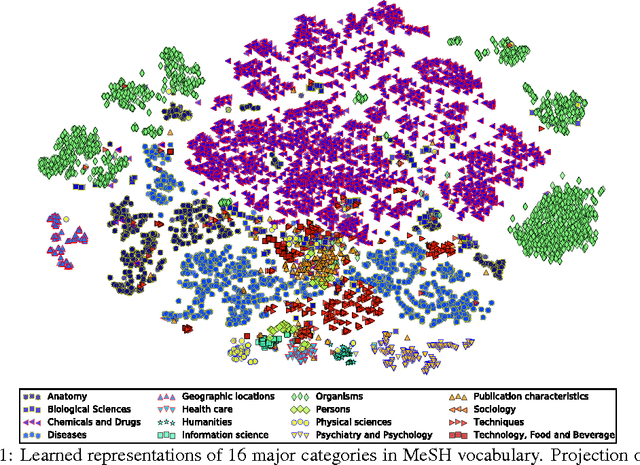
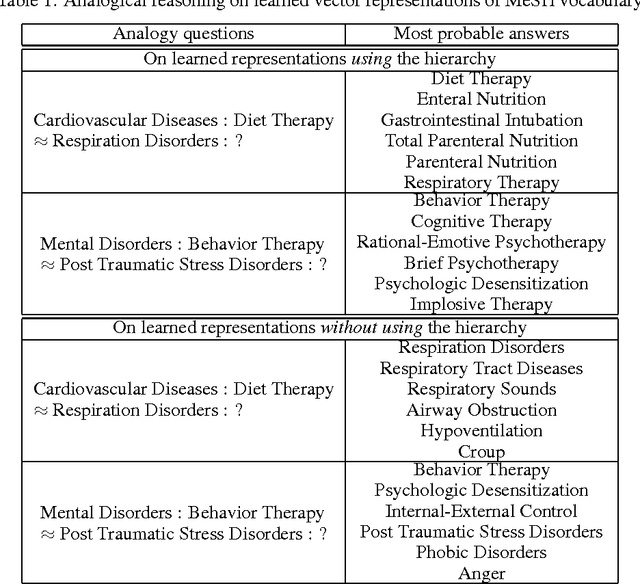
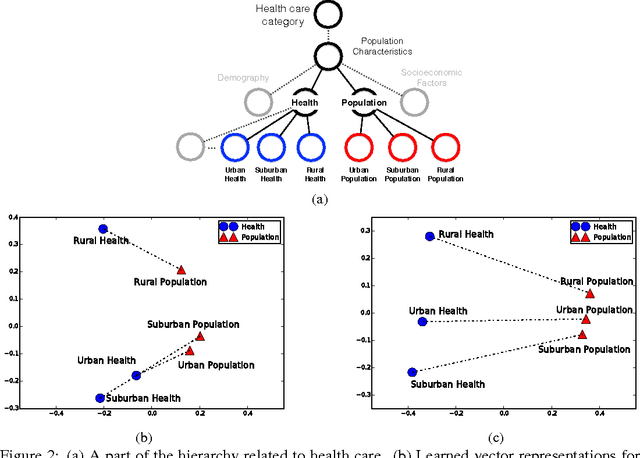
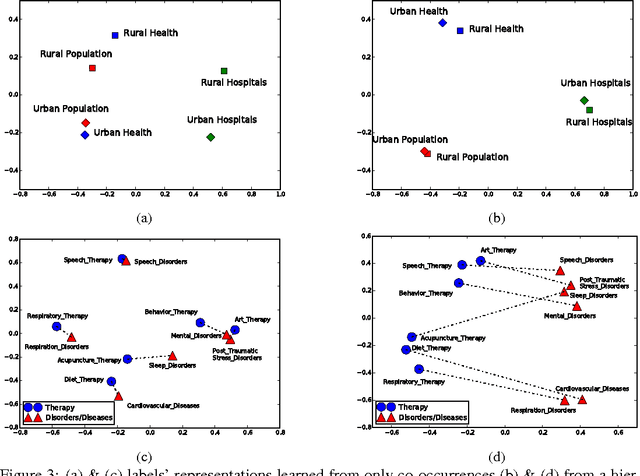
An important problem in multi-label classification is to capture label patterns or underlying structures that have an impact on such patterns. This paper addresses one such problem, namely how to exploit hierarchical structures over labels. We present a novel method to learn vector representations of a label space given a hierarchy of labels and label co-occurrence patterns. Our experimental results demonstrate qualitatively that the proposed method is able to learn regularities among labels by exploiting a label hierarchy as well as label co-occurrences. It highlights the importance of the hierarchical information in order to obtain regularities which facilitate analogical reasoning over a label space. We also experimentally illustrate the dependency of the learned representations on the label hierarchy.
Large-scale Multi-label Text Classification - Revisiting Neural Networks
May 15, 2014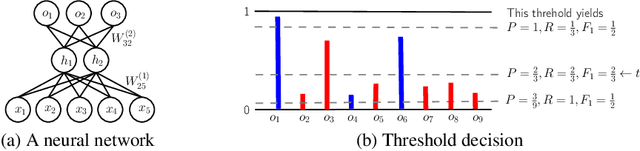

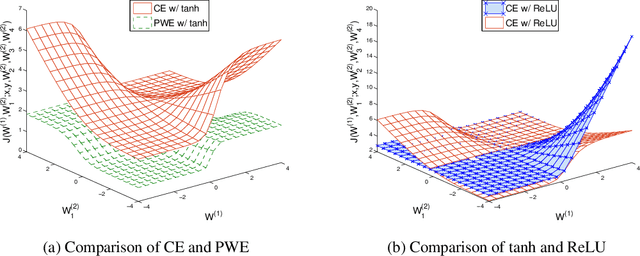
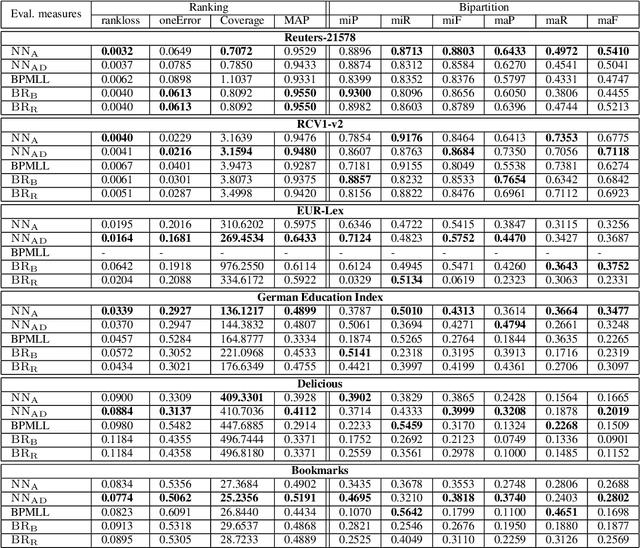
Neural networks have recently been proposed for multi-label classification because they are able to capture and model label dependencies in the output layer. In this work, we investigate limitations of BP-MLL, a neural network (NN) architecture that aims at minimizing pairwise ranking error. Instead, we propose to use a comparably simple NN approach with recently proposed learning techniques for large-scale multi-label text classification tasks. In particular, we show that BP-MLL's ranking loss minimization can be efficiently and effectively replaced with the commonly used cross entropy error function, and demonstrate that several advances in neural network training that have been developed in the realm of deep learning can be effectively employed in this setting. Our experimental results show that simple NN models equipped with advanced techniques such as rectified linear units, dropout, and AdaGrad perform as well as or even outperform state-of-the-art approaches on six large-scale textual datasets with diverse characteristics.