 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorize to Generalize: Retrieval-Guided Invariant-Dynamic Decomposition for Time Series Forecasting
May 24, 2026Time series foundation models (TSFMs) have recently achieved strong zero-shot forecasting performance through large-scale pretraining and retrieval-augmented prediction. However, our empirical analysis reveals a non-trivial limitation of retrieval-based forecasting: retrieval tends to induce more oscillatory predictions, improving performance on highly fluctuating series while degrading accuracy on smoother, trend-dominated ones. This suggests that retrieved information may be fused into prediction without explicitly distinguishing stable temporal structure from instance-specific variations, which can reduce robustness under distribution shifts. We propose a Retrieval-guided Invariant-Dynamic DEcomposition framework for time series forecasting. Rather than using retrieval as auxiliary predictive context, we leverage retrieved sequences as implicit samples from related environments to guide representation decomposition. Specifically, we first construct a retrieval-aware representation via attention-based aggregation, and then introduce a retrieval-guided routing mechanism to decompose it into an invariant component capturing stable shared structure and a dynamic component modeling context-dependent variations. These two components are forecast separately and fused for final prediction, enabling the model to preserve transferable patterns while remaining adaptive to evolving dynamics. We further design training objectives that encourage invariant learning and disentanglement, and provide theoretical insight showing that retrieval aggregation reduces variance and approximates invariant representation learning without explicit environment supervision. Extensive experiments demonstrate that our method consistently improves robustness under distribution shifts and outperforms existing TSFMs and retrieval-based baselines in zero-shot forecasting settings.
Decomposing the Basic Abilities of Large Language Models: Mitigating Cross-Task Interference in Multi-Task Instruct-Tuning
May 07, 2026Recently, the prominent performance of large language models (LLMs) has been largely driven by multi-task instruct-tuning. Unfortunately, this training paradigm suffers from a key issue, named cross-task interference, due to conflicting gradients over shared parameters among different tasks. Some previous methods mitigate this issue by isolating task-specific parameters, e.g., task-specific neuron selection and mixture-of-experts. In this paper, we empirically reveal that the cross-task interference still exists for the existing solutions because of many parameters also shared by different tasks, and accordingly, we propose a novel solution, namely Basic Abilities Decomposition for multi-task Instruct-Tuning (BADIT). Specifically, we empirically find that certain parameters are consistently co-activated, and that co-activated parameters naturally organize into base groups. This motivates us to analogize that LLMs encode several orthogonal basic abilities, and that any task can be represented as a linear combination of these abilities. Accordingly, we propose BADIT that decomposes LLM parameters into orthogonal high-singular-value LoRA experts representing basic abilities, and dynamically enforces their orthogonality during training via spherical clustering of rank-1 components. We conduct extensive experiments on the SuperNI benchmark with 6 LLMs, and empirical results demonstrate that BADIT can outperform SOTA methods and mitigate the degree of cross-task interference.
Harmful Visual Content Manipulation Matters in Misinformation Detection Under Multimedia Scenarios
Mar 22, 2026Nowadays, the widespread dissemination of misinformation across numerous social media platforms has led to severe negative effects on society. To address this challenge, the automatic detection of misinformation, particularly under multimedia scenarios, has gained significant attention from both academic and industrial communities, leading to the emergence of a research task known as Multimodal Misinformation Detection (MMD). Typically, current MMD approaches focus on capturing the semantic relationships and inconsistency between various modalities but often overlook certain critical indicators within multimodal content. Recent research has shown that manipulated features within visual content in social media articles serve as valuable clues for MMD. Meanwhile, we argue that the potential intentions behind the manipulation, e.g., harmful and harmless, also matter in MMD. Therefore, in this study, we aim to identify such multimodal misinformation by capturing two types of features: manipulation features, which represent if visual content has been manipulated, and intention features, which assess the nature of these manipulations, distinguishing between harmful and harmless intentions. Unfortunately, the manipulation and intention labels that supervise these features to be discriminative are unknown. To address this, we introduce two weakly supervised indicators as substitutes by incorporating supplementary datasets focused on image manipulation detection and framing two different classification tasks as positive and unlabeled learning issues. With this framework, we introduce an innovative MMD approach, titled Harmful Visual Content Manipulation Matters in MMD (HAVC-M4 D). Comprehensive experiments conducted on four prevalent MMD datasets indicate that HAVC-M4 D significantly and consistently enhances the performance of existing MMD methods.
Disentangled Representation Learning via Flow Matching
Feb 05, 2026Disentangled representation learning aims to capture the underlying explanatory factors of observed data, enabling a principled understanding of the data-generating process. Recent advances in generative modeling have introduced new paradigms for learning such representations. However, existing diffusion-based methods encourage factor independence via inductive biases, yet frequently lack strong semantic alignment. In this work, we propose a flow matching-based framework for disentangled representation learning, which casts disentanglement as learning factor-conditioned flows in a compact latent space. To enforce explicit semantic alignment, we introduce a non-overlap (orthogonality) regularizer that suppresses cross-factor interference and reduces information leakage between factors. Extensive experiments across multiple datasets demonstrate consistent improvements over representative baselines, yielding higher disentanglement scores as well as improved controllability and sample fidelity.
Variational Wasserstein Barycenters with c-Cyclical Monotonicity
Oct 22, 2021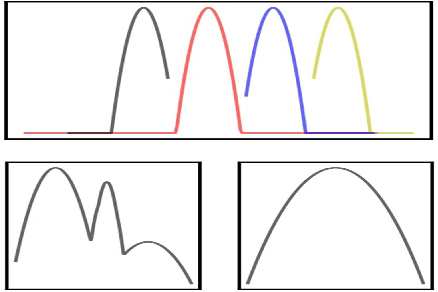

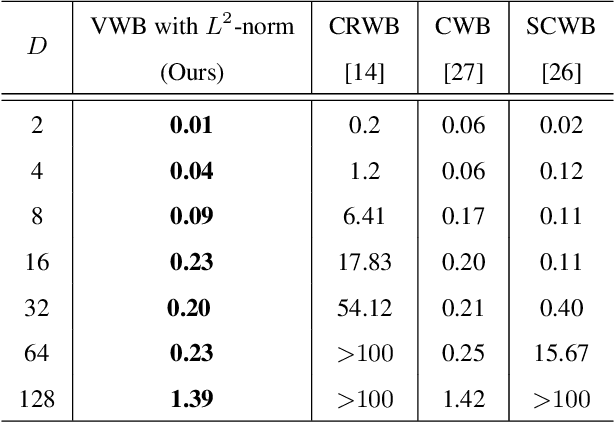
Wasserstein barycenter, built on the theory of optimal transport, provides a powerful framework to aggregate probability distributions, and it has increasingly attracted great attention within the machine learning community. However, it suffers from severe computational burden, especially for high dimensional and continuous settings. To this end, we develop a novel continuous approximation method for the Wasserstein barycenters problem given sample access to the input distributions. The basic idea is to introduce a variational distribution as the approximation of the true continuous barycenter, so as to frame the barycenters computation problem as an optimization problem, where parameters of the variational distribution adjust the proxy distribution to be similar to the barycenter. Leveraging the variational distribution, we construct a tractable dual formulation for the regularized Wasserstein barycenter problem with c-cyclical monotonicity, which can be efficiently solved by stochastic optimization. We provide theoretical analysis on convergence and demonstrate the practical effectiveness of our method on real applications of subset posterior aggregation and synthetic data.
Topic representation: finding more representative words in topic models
Oct 23, 2018
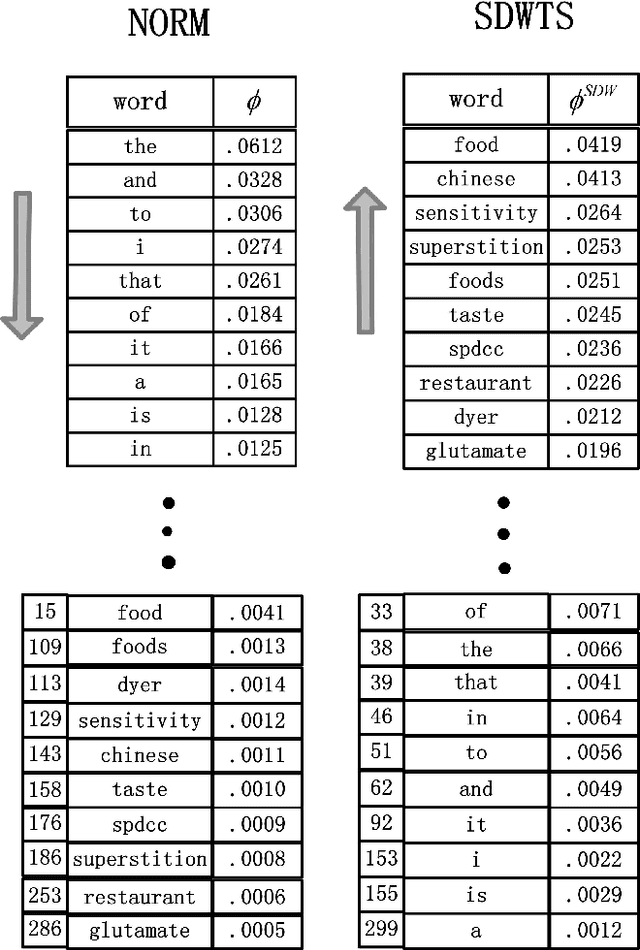

The top word list, i.e., the top-M words with highest marginal probability in a given topic, is the standard topic representation in topic models. Most of recent automatical topic labeling algorithms and popular topic quality metrics are based on it. However, we find, empirically, words in this type of top word list are not always representative. The objective of this paper is to find more representative top word lists for topics. To achieve this, we rerank the words in a given topic by further considering marginal probability on words over every other topic. The reranking list of top-M words is used to be a novel topic representation for topic models. We investigate three reranking methodologies, using (1) standard deviation weight, (2) standard deviation weight with topic size and (3) Chi Square \c{hi}2statistic selection. Experimental results on real world collections indicate that our representations can extract more representative words for topics, agreeing with human judgements.