 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Decoding for Neural NLG from Compositional Representations in Task-Oriented Dialogue
Jun 17, 2019

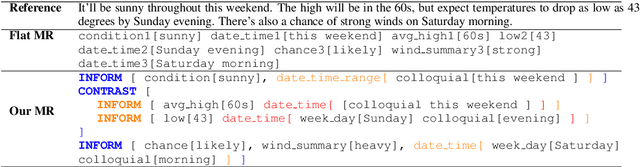
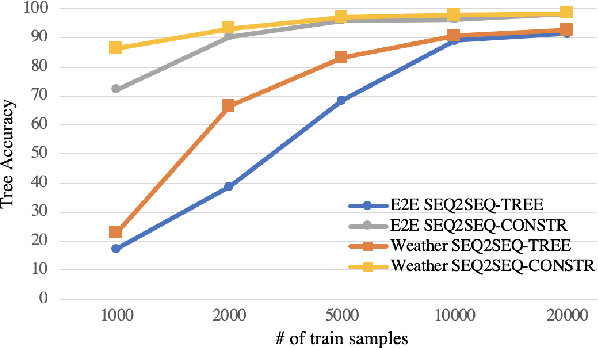
Generating fluent natural language responses from structured semantic representations is a critical step in task-oriented conversational systems. Avenues like the E2E NLG Challenge have encouraged the development of neural approaches, particularly sequence-to-sequence (Seq2Seq) models for this problem. The semantic representations used, however, are often underspecified, which places a higher burden on the generation model for sentence planning, and also limits the extent to which generated responses can be controlled in a live system. In this paper, we (1) propose using tree-structured semantic representations, like those used in traditional rule-based NLG systems, for better discourse-level structuring and sentence-level planning; (2) introduce a challenging dataset using this representation for the weather domain; (3) introduce a constrained decoding approach for Seq2Seq models that leverages this representation to improve semantic correctness; and (4) demonstrate promising results on our dataset and the E2E dataset.
Lightweight and Efficient Neural Natural Language Processing with Quaternion Networks
Jun 11, 2019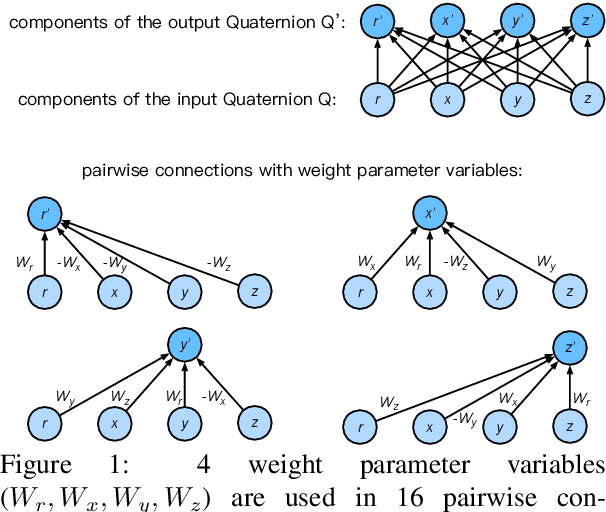



Many state-of-the-art neural models for NLP are heavily parameterized and thus memory inefficient. This paper proposes a series of lightweight and memory efficient neural architectures for a potpourri of natural language processing (NLP) tasks. To this end, our models exploit computation using Quaternion algebra and hypercomplex spaces, enabling not only expressive inter-component interactions but also significantly ($75\%$) reduced parameter size due to lesser degrees of freedom in the Hamilton product. We propose Quaternion variants of models, giving rise to new architectures such as the Quaternion attention Model and Quaternion Transformer. Extensive experiments on a battery of NLP tasks demonstrates the utility of proposed Quaternion-inspired models, enabling up to $75\%$ reduction in parameter size without significant loss in performance.
Simple and Effective Curriculum Pointer-Generator Networks for Reading Comprehension over Long Narratives
May 26, 2019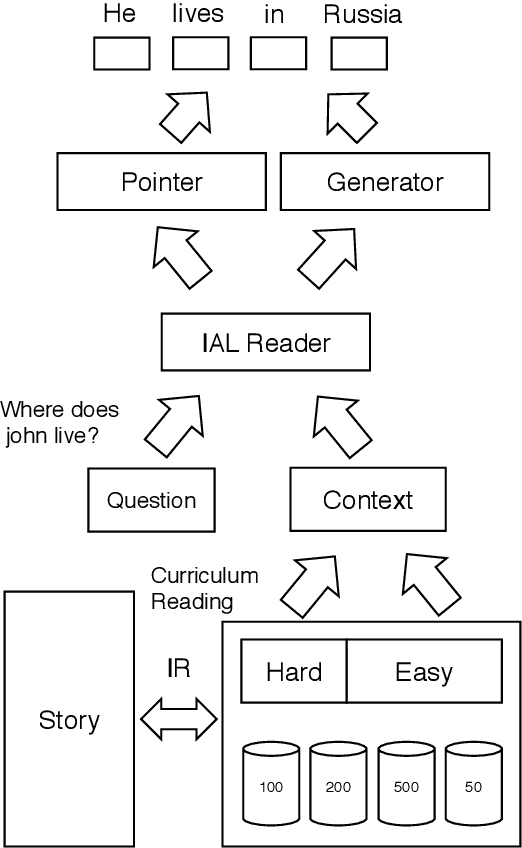
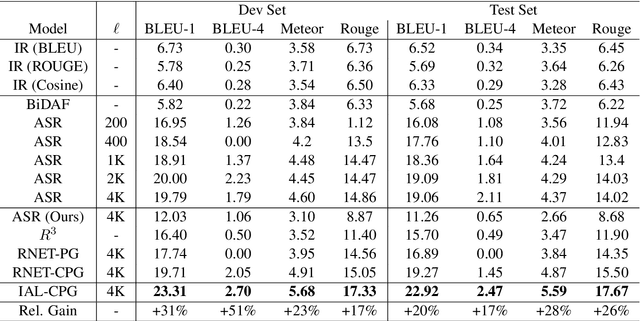
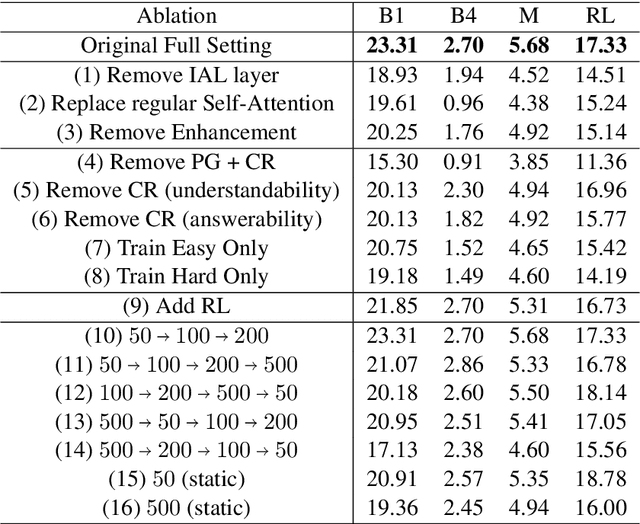

This paper tackles the problem of reading comprehension over long narratives where documents easily span over thousands of tokens. We propose a curriculum learning (CL) based Pointer-Generator framework for reading/sampling over large documents, enabling diverse training of the neural model based on the notion of alternating contextual difficulty. This can be interpreted as a form of domain randomization and/or generative pretraining during training. To this end, the usage of the Pointer-Generator softens the requirement of having the answer within the context, enabling us to construct diverse training samples for learning. Additionally, we propose a new Introspective Alignment Layer (IAL), which reasons over decomposed alignments using block-based self-attention. We evaluate our proposed method on the NarrativeQA reading comprehension benchmark, achieving state-of-the-art performance, improving existing baselines by $51\%$ relative improvement on BLEU-4 and $17\%$ relative improvement on Rouge-L. Extensive ablations confirm the effectiveness of our proposed IAL and CL components.
Simple Attention-Based Representation Learning for Ranking Short Social Media Posts
Nov 02, 2018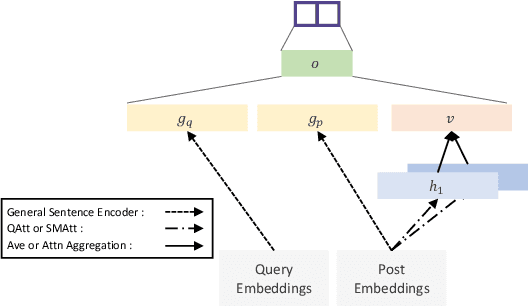
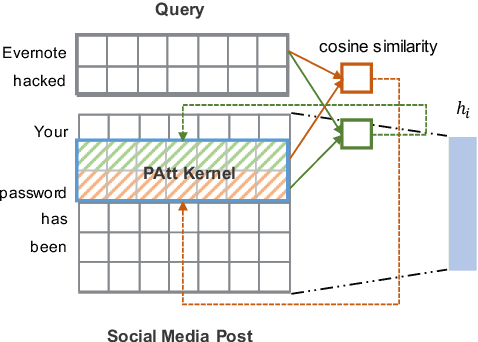
This paper explores the problem of ranking short social media posts with respect to user queries using neural networks. Instead of starting with a complex architecture, we proceed from the bottom up and examine the effectiveness of a simple, word-level Siamese architecture augmented with attention-based mechanisms for capturing semantic soft matches between query and post terms. Extensive experiments on datasets from the TREC Microblog Tracks show that our simple models not only demonstrate better effectiveness than existing approaches that are far more complex or exploit a more diverse set of relevance signals, but also achieve 4 times speedup in model training and inference.
Multi-Perspective Relevance Matching with Hierarchical ConvNets for Social Media Search
May 21, 2018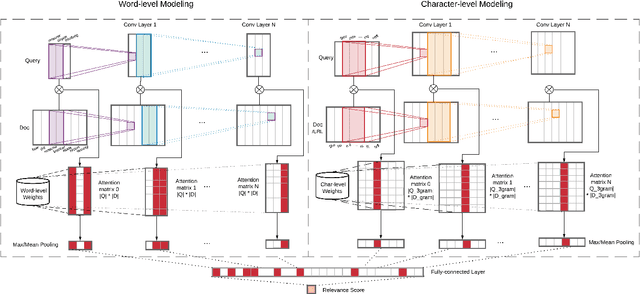

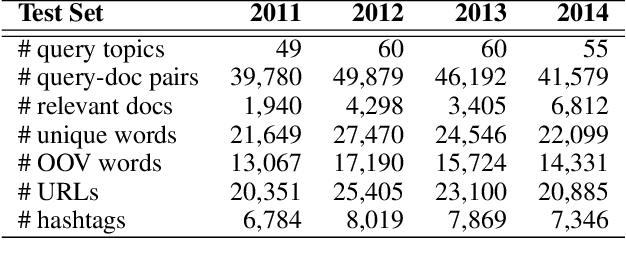
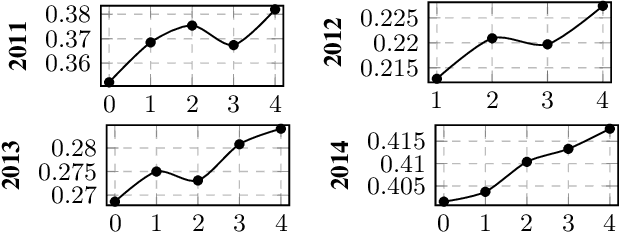
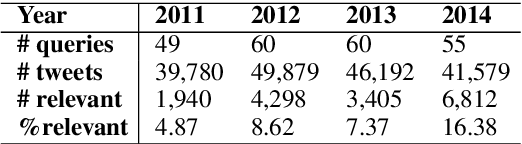
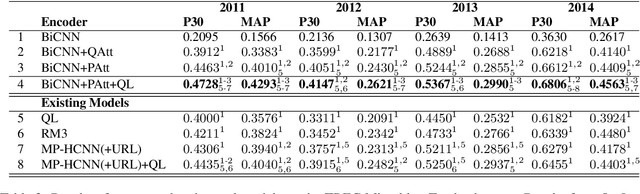
Despite substantial interest in applications of neural networks to information retrieval, neural ranking models have only been applied to standard ad hoc retrieval tasks over web pages and newswire documents. This paper proposes MP-HCNN (Multi-Perspective Hierarchical Convolutional Neural Network) a novel neural ranking model specifically designed for ranking short social media posts. We identify document length, informal language, and heterogeneous relevance signals as features that distinguish documents in our domain, and present a model specifically designed with these characteristics in mind. Our model uses hierarchical convolutional layers to learn latent semantic soft-match relevance signals at the character, word, and phrase levels. A pooling-based similarity measurement layer integrates evidence from multiple types of matches between the query, the social media post, as well as URLs contained in the post. Extensive experiments using Twitter data from the TREC Microblog Tracks 2011--2014 show that our model significantly outperforms prior feature-based as well and existing neural ranking models. To our best knowledge, this paper presents the first substantial work tackling search over social media posts using neural ranking models.
Exploring the Effectiveness of Convolutional Neural Networks for Answer Selection in End-to-End Question Answering
Jul 25, 2017
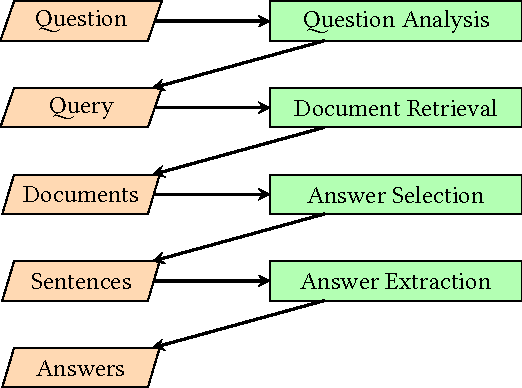
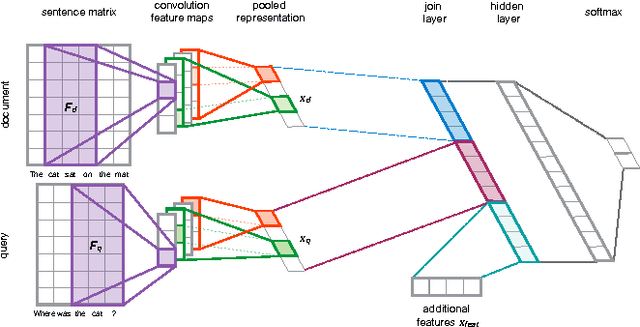
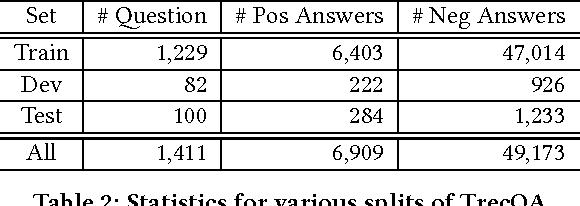
Most work on natural language question answering today focuses on answer selection: given a candidate list of sentences, determine which contains the answer. Although important, answer selection is only one stage in a standard end-to-end question answering pipeline. This paper explores the effectiveness of convolutional neural networks (CNNs) for answer selection in an end-to-end context using the standard TrecQA dataset. We observe that a simple idf-weighted word overlap algorithm forms a very strong baseline, and that despite substantial efforts by the community in applying deep learning to tackle answer selection, the gains are modest at best on this dataset. Furthermore, it is unclear if a CNN is more effective than the baseline in an end-to-end context based on standard retrieval metrics. To further explore this finding, we conducted a manual user evaluation, which confirms that answers from the CNN are detectably better than those from idf-weighted word overlap. This result suggests that users are sensitive to relatively small differences in answer selection quality.
Integrating Lexical and Temporal Signals in Neural Ranking Models for Searching Social Media Streams
Jul 25, 2017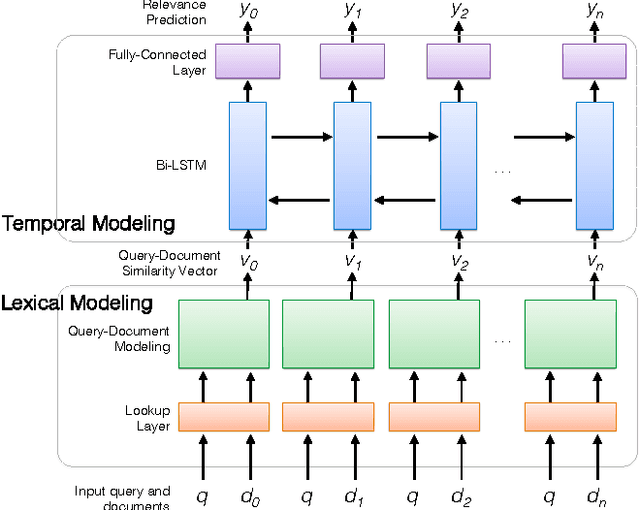
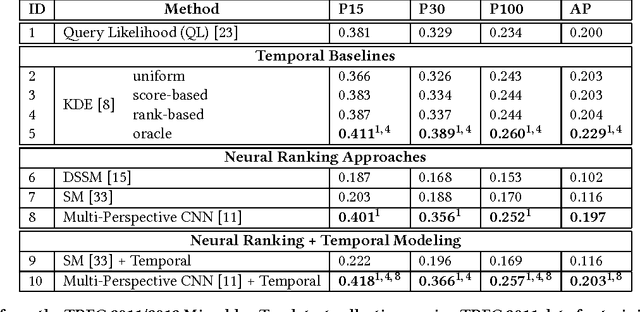
Time is an important relevance signal when searching streams of social media posts. The distribution of document timestamps from the results of an initial query can be leveraged to infer the distribution of relevant documents, which can then be used to rerank the initial results. Previous experiments have shown that kernel density estimation is a simple yet effective implementation of this idea. This paper explores an alternative approach to mining temporal signals with recurrent neural networks. Our intuition is that neural networks provide a more expressive framework to capture the temporal coherence of neighboring documents in time. To our knowledge, we are the first to integrate lexical and temporal signals in an end-to-end neural network architecture, in which existing neural ranking models are used to generate query-document similarity vectors that feed into a bidirectional LSTM layer for temporal modeling. Our results are mixed: existing neural models for document ranking alone yield limited improvements over simple baselines, but the integration of lexical and temporal signals yield significant improvements over competitive temporal baselines.