 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade Residual Learning: A Two-stage Convolutional Neural Network for Stereo Matching
Jul 30, 2018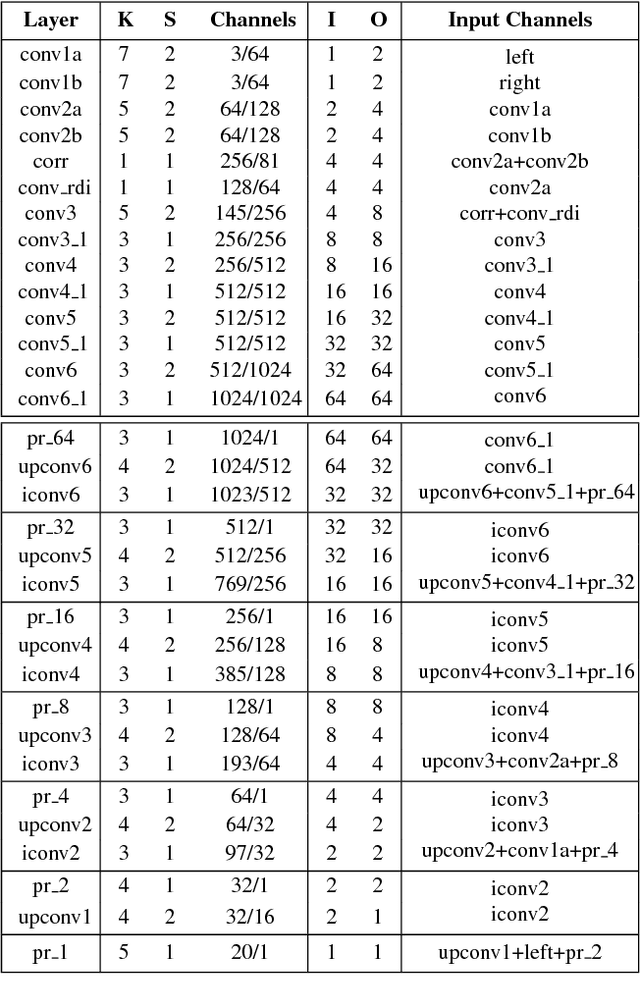


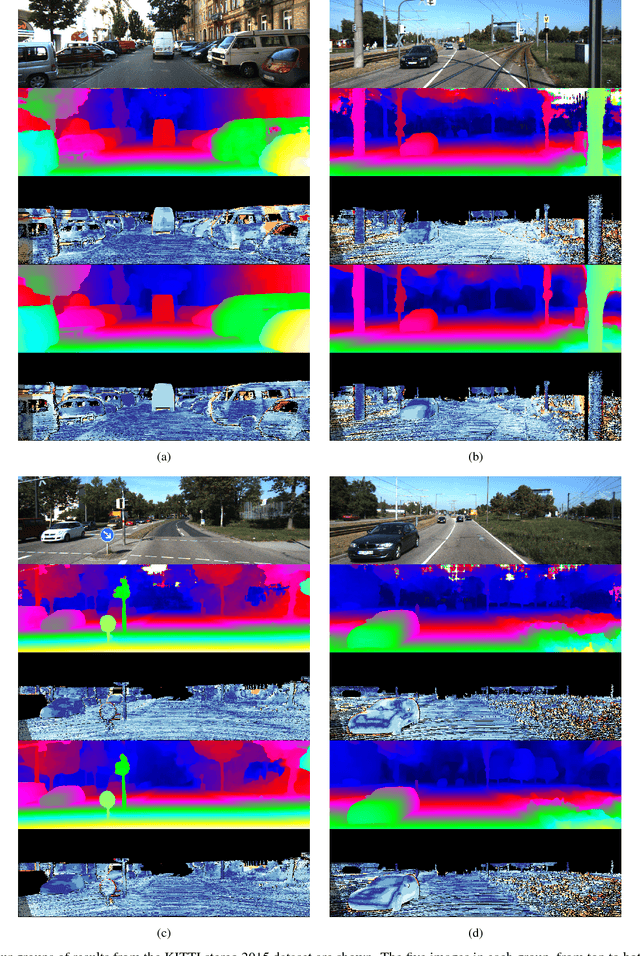
Leveraging on the recent developments in convolutional neural networks (CNNs), matching dense correspondence from a stereo pair has been cast as a learning problem, with performance exceeding traditional approaches. However, it remains challenging to generate high-quality disparities for the inherently ill-posed regions. To tackle this problem, we propose a novel cascade CNN architecture composing of two stages. The first stage advances the recently proposed DispNet by equipping it with extra up-convolution modules, leading to disparity images with more details. The second stage explicitly rectifies the disparity initialized by the first stage; it couples with the first-stage and generates residual signals across multiple scales. The summation of the outputs from the two stages gives the final disparity. As opposed to directly learning the disparity at the second stage, we show that residual learning provides more effective refinement. Moreover, it also benefits the training of the overall cascade network. Experimentation shows that our cascade residual learning scheme provides state-of-the-art performance for matching stereo correspondence. By the time of the submission of this paper, our method ranks first in the KITTI 2015 stereo benchmark, surpassing the prior works by a noteworthy margin.
On Vectorization of Deep Convolutional Neural Networks for Vision Tasks
Jan 29, 2015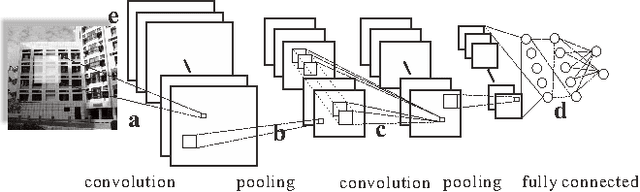
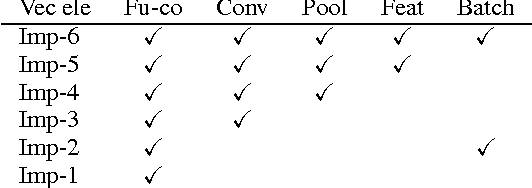
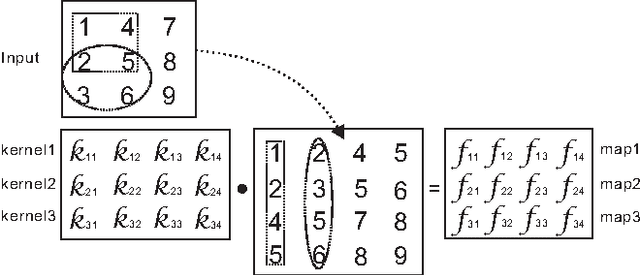
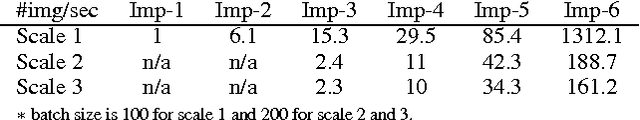
We recently have witnessed many ground-breaking results in machine learning and computer vision, generated by using deep convolutional neural networks (CNN). While the success mainly stems from the large volume of training data and the deep network architectures, the vector processing hardware (e.g. GPU) undisputedly plays a vital role in modern CNN implementations to support massive computation. Though much attention was paid in the extent literature to understand the algorithmic side of deep CNN, little research was dedicated to the vectorization for scaling up CNNs. In this paper, we studied the vectorization process of key building blocks in deep CNNs, in order to better understand and facilitate parallel implementation. Key steps in training and testing deep CNNs are abstracted as matrix and vector operators, upon which parallelism can be easily achieved. We developed and compared six implementations with various degrees of vectorization with which we illustrated the impact of vectorization on the speed of model training and testing. Besides, a unified CNN framework for both high-level and low-level vision tasks is provided, along with a vectorized Matlab implementation with state-of-the-art speed performance.
An Unsupervised Feature Learning Approach to Improve Automatic Incident Detection
Oct 29, 2013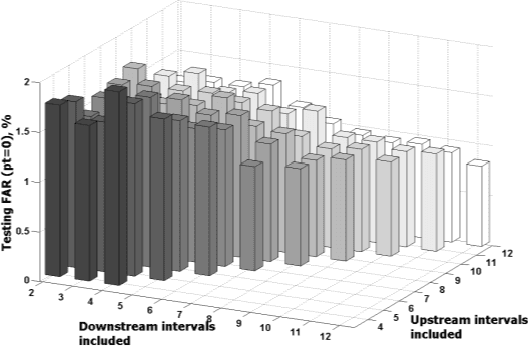
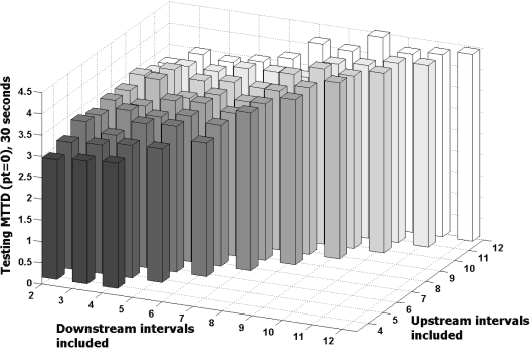
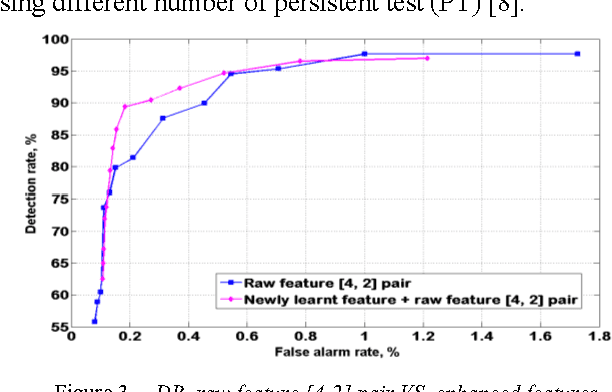
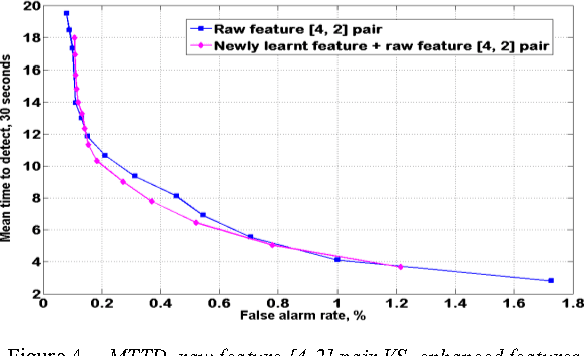
Sophisticated automatic incident detection (AID) technology plays a key role in contemporary transportation systems. Though many papers were devoted to study incident classification algorithms, few study investigated how to enhance feature representation of incidents to improve AID performance. In this paper, we propose to use an unsupervised feature learning algorithm to generate higher level features to represent incidents. We used real incident data in the experiments and found that effective feature mapping function can be learnt from the data crosses the test sites. With the enhanced features, detection rate (DR), false alarm rate (FAR) and mean time to detect (MTTD) are significantly improved in all of the three representative cases. This approach also provides an alternative way to reduce the amount of labeled data, which is expensive to obtain, required in training better incident classifiers since the feature learning is unsupervised.
Exploring The Contribution of Unlabeled Data in Financial Sentiment Analysis
Aug 03, 2013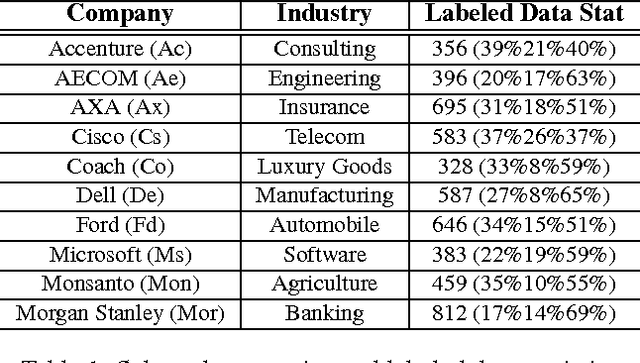
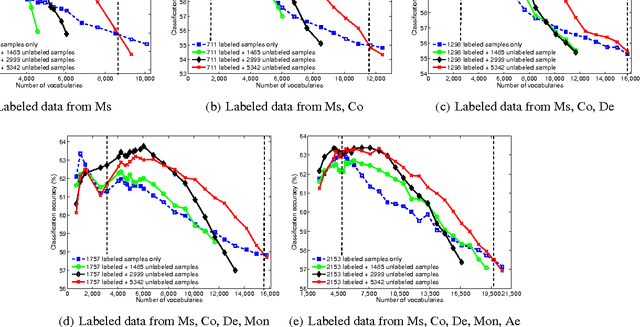
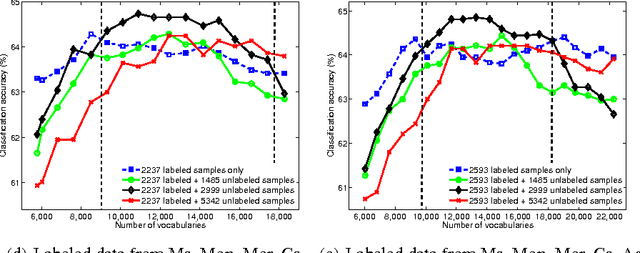
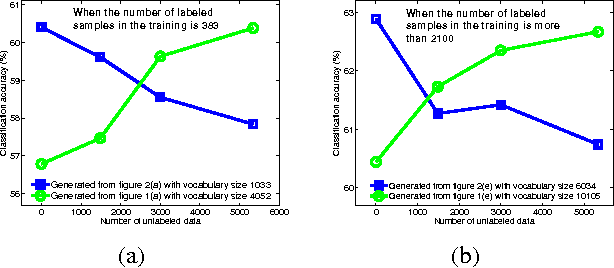
With the proliferation of its applications in various industries, sentiment analysis by using publicly available web data has become an active research area in text classification during these years. It is argued by researchers that semi-supervised learning is an effective approach to this problem since it is capable to mitigate the manual labeling effort which is usually expensive and time-consuming. However, there was a long-term debate on the effectiveness of unlabeled data in text classification. This was partially caused by the fact that many assumptions in theoretic analysis often do not hold in practice. We argue that this problem may be further understood by adding an additional dimension in the experiment. This allows us to address this problem in the perspective of bias and variance in a broader view. We show that the well-known performance degradation issue caused by unlabeled data can be reproduced as a subset of the whole scenario. We argue that if the bias-variance trade-off is to be better balanced by a more effective feature selection method unlabeled data is very likely to boost the classification performance. We then propose a feature selection framework in which labeled and unlabeled training samples are both considered. We discuss its potential in achieving such a balance. Besides, the application in financial sentiment analysis is chosen because it not only exemplifies an important application, the data possesses better illustrative power as well. The implications of this study in text classification and financial sentiment analysis are both discussed.