 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoM: Mixtures of Scenario-Aware Document Memories for Retrieval-Augmented Generation Systems
Paper and Code
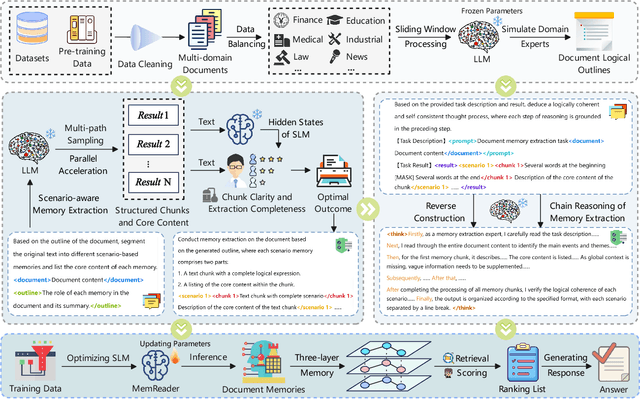
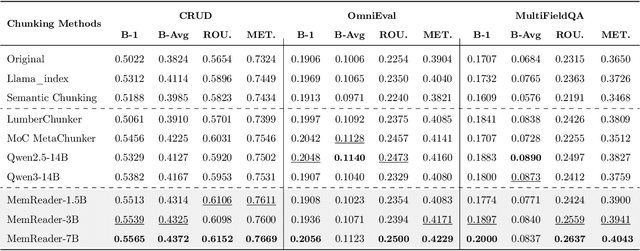
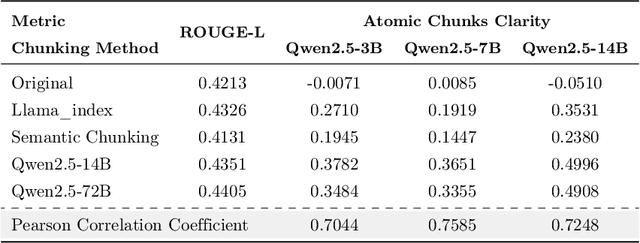
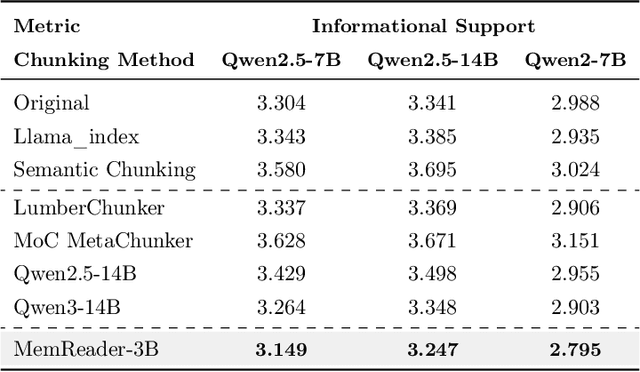
The traditional RAG paradigm, which typically engages in the comprehension of relevant text chunks in response to received queries, inherently restricts both the depth of knowledge internalization and reasoning capabilities. To address this limitation, our research transforms the text processing in RAG from passive chunking to proactive understanding, defining this process as document memory extraction with the objective of simulating human cognitive processes during reading. Building upon this, we propose the Mixtures of scenario-aware document Memories (MoM) framework, engineered to efficiently handle documents from multiple domains and train small language models (SLMs) to acquire the ability to proactively explore and construct document memories. The MoM initially instructs large language models (LLMs) to simulate domain experts in generating document logical outlines, thereby directing structured chunking and core content extraction. It employs a multi-path sampling and multi-perspective evaluation mechanism, specifically designing comprehensive metrics that represent chunk clarity and extraction completeness to select the optimal document memories. Additionally, to infuse deeper human-like reading abilities during the training of SLMs, we incorporate a reverse reasoning strategy, which deduces refined expert thinking paths from high-quality outcomes. Finally, leveraging diverse forms of content generated by MoM, we develop a three-layer document memory retrieval mechanism, which is grounded in our theoretical proof from the perspective of probabilistic modeling. Extensive experimental results across three distinct domains demonstrate that the MoM framework not only resolves text chunking challenges in existing RAG systems, providing LLMs with semantically complete document memories, but also paves the way for SLMs to achieve human-centric intelligent text processing.