 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcept-based Explanations for Out-Of-Distribution Detectors
Mar 04, 2022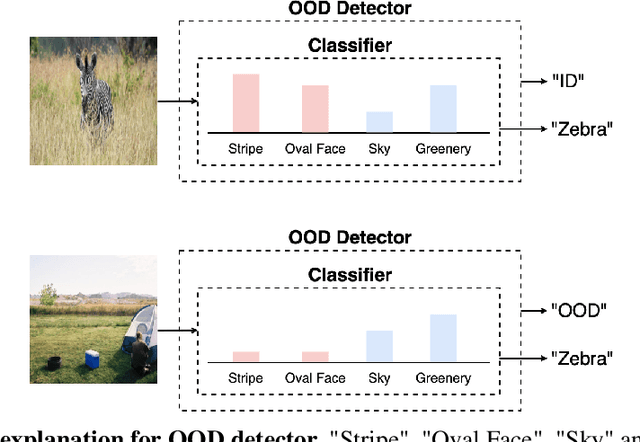
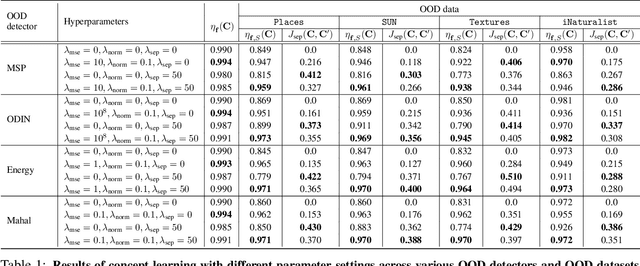
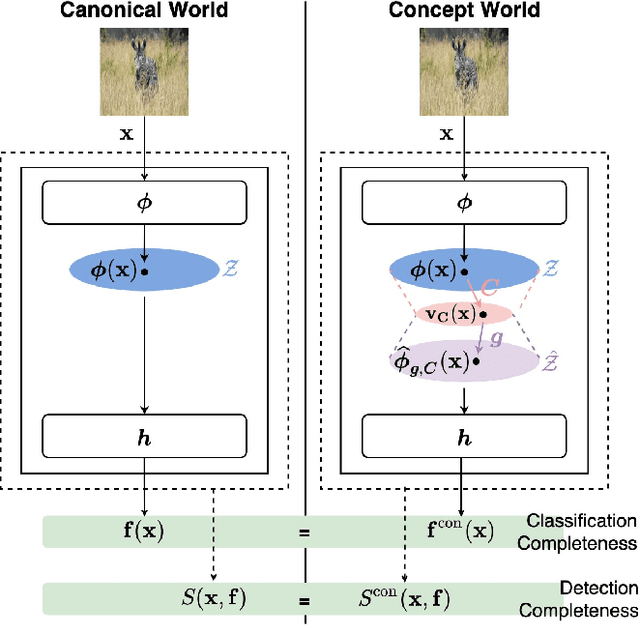
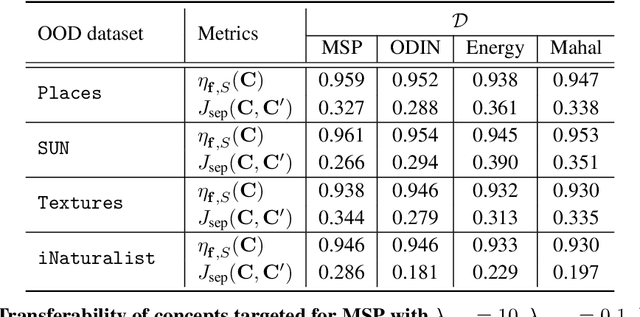
Out-of-distribution (OOD) detection plays a crucial role in ensuring the safe deployment of deep neural network (DNN) classifiers. While a myriad of methods have focused on improving the performance of OOD detectors, a critical gap remains in interpreting their decisions. We help bridge this gap by providing explanations for OOD detectors based on learned high-level concepts. We first propose two new metrics for assessing the effectiveness of a particular set of concepts for explaining OOD detectors: 1) detection completeness, which quantifies the sufficiency of concepts for explaining an OOD-detector's decisions, and 2) concept separability, which captures the distributional separation between in-distribution and OOD data in the concept space. Based on these metrics, we propose a framework for learning a set of concepts that satisfy the desired properties of detection completeness and concept separability and demonstrate the framework's effectiveness in providing concept-based explanations for diverse OOD techniques. We also show how to identify prominent concepts that contribute to the detection results via a modified Shapley value-based importance score.
Towards Efficiently Evaluating the Robustness of Deep Neural Networks in IoT Systems: A GAN-based Method
Nov 19, 2021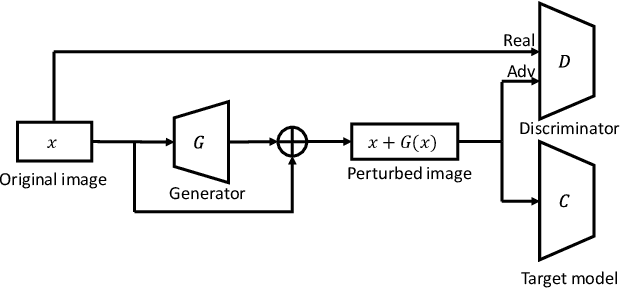
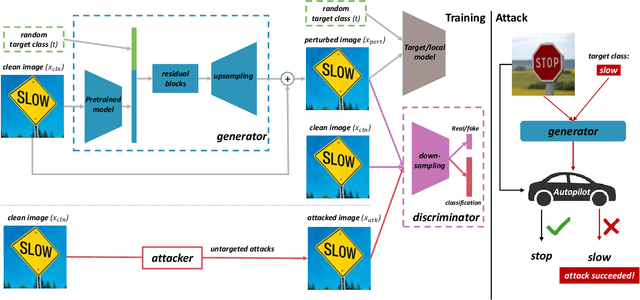

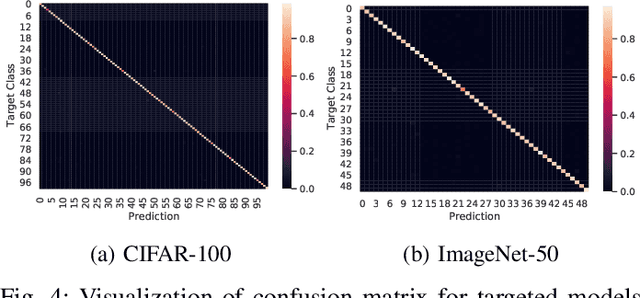
Intelligent Internet of Things (IoT) systems based on deep neural networks (DNNs) have been widely deployed in the real world. However, DNNs are found to be vulnerable to adversarial examples, which raises people's concerns about intelligent IoT systems' reliability and security. Testing and evaluating the robustness of IoT systems becomes necessary and essential. Recently various attacks and strategies have been proposed, but the efficiency problem remains unsolved properly. Existing methods are either computationally extensive or time-consuming, which is not applicable in practice. In this paper, we propose a novel framework called Attack-Inspired GAN (AI-GAN) to generate adversarial examples conditionally. Once trained, it can generate adversarial perturbations efficiently given input images and target classes. We apply AI-GAN on different datasets in white-box settings, black-box settings and targeted models protected by state-of-the-art defenses. Through extensive experiments, AI-GAN achieves high attack success rates, outperforming existing methods, and reduces generation time significantly. Moreover, for the first time, AI-GAN successfully scales to complex datasets e.g. CIFAR-100 and ImageNet, with about $90\%$ success rates among all classes.
Towards Evaluating the Robustness of Neural Networks Learned by Transduction
Oct 27, 2021
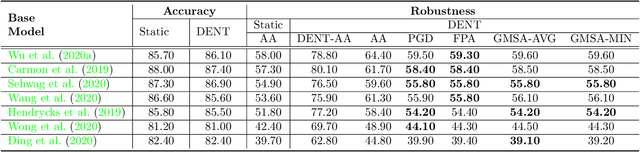

There has been emerging interest in using transductive learning for adversarial robustness (Goldwasser et al., NeurIPS 2020; Wu et al., ICML 2020; Wang et al., ArXiv 2021). Compared to traditional defenses, these defense mechanisms "dynamically learn" the model based on test-time input; and theoretically, attacking these defenses reduces to solving a bilevel optimization problem, which poses difficulty in crafting adaptive attacks. In this paper, we examine these defense mechanisms from a principled threat analysis perspective. We formulate and analyze threat models for transductive-learning based defenses, and point out important subtleties. We propose the principle of attacking model space for solving bilevel attack objectives, and present Greedy Model Space Attack (GMSA), an attack framework that can serve as a new baseline for evaluating transductive-learning based defenses. Through systematic evaluation, we show that GMSA, even with weak instantiations, can break previous transductive-learning based defenses, which were resilient to previous attacks, such as AutoAttack (Croce and Hein, ICML 2020). On the positive side, we report a somewhat surprising empirical result of "transductive adversarial training": Adversarially retraining the model using fresh randomness at the test time gives a significant increase in robustness against attacks we consider.
Detecting Errors and Estimating Accuracy on Unlabeled Data with Self-training Ensembles
Jun 29, 2021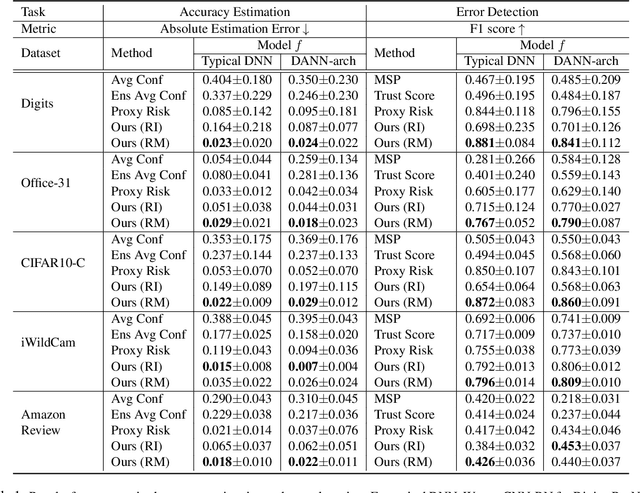
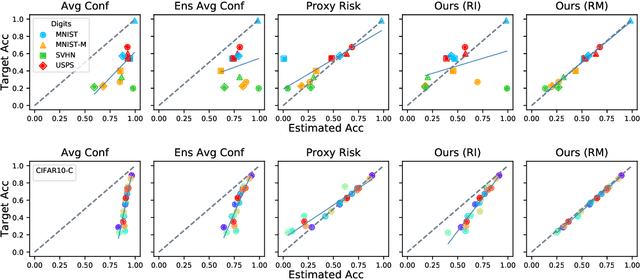
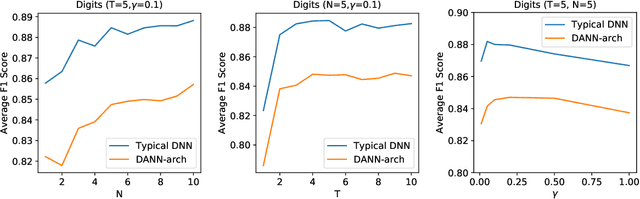
When a deep learning model is deployed in the wild, it can encounter test data drawn from distributions different from the training data distribution and suffer drop in performance. For safe deployment, it is essential to estimate the accuracy of the pre-trained model on the test data. However, the labels for the test inputs are usually not immediately available in practice, and obtaining them can be expensive. This observation leads to two challenging tasks: (1) unsupervised accuracy estimation, which aims to estimate the accuracy of a pre-trained classifier on a set of unlabeled test inputs; (2) error detection, which aims to identify mis-classified test inputs. In this paper, we propose a principled and practically effective framework that simultaneously addresses the two tasks. The proposed framework iteratively learns an ensemble of models to identify mis-classified data points and performs self-training to improve the ensemble with the identified points. Theoretical analysis demonstrates that our framework enjoys provable guarantees for both accuracy estimation and error detection under mild conditions readily satisfied by practical deep learning models. Along with the framework, we proposed and experimented with two instantiations and achieved state-of-the-art results on 59 tasks. For example, on iWildCam, one instantiation reduces the estimation error for unsupervised accuracy estimation by at least 70% and improves the F1 score for error detection by at least 4.7% compared to existing methods.
Towards Adversarial Robustness via Transductive Learning
Jun 15, 2021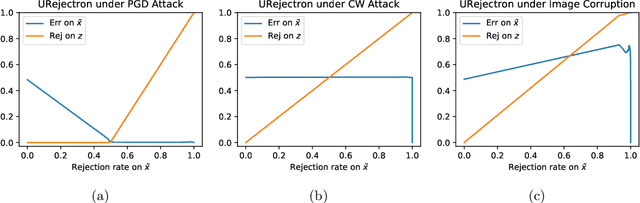
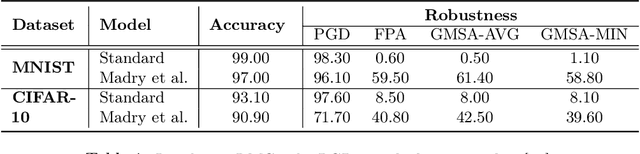
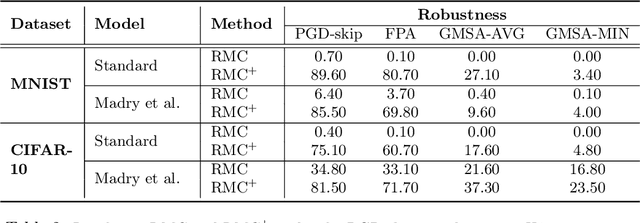
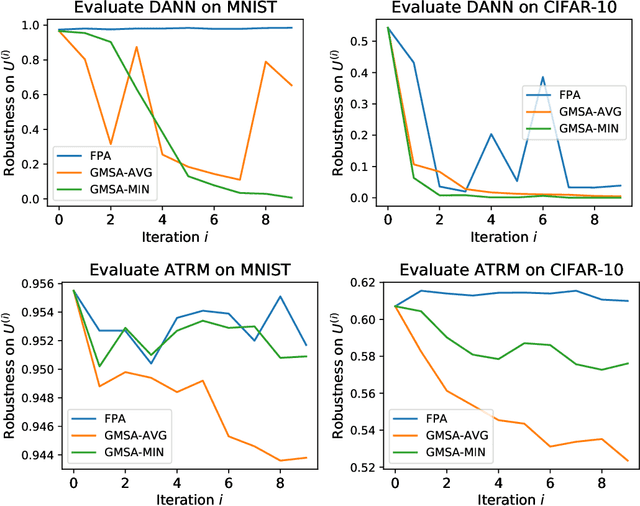
There has been emerging interest to use transductive learning for adversarial robustness (Goldwasser et al., NeurIPS 2020; Wu et al., ICML 2020). Compared to traditional "test-time" defenses, these defense mechanisms "dynamically retrain" the model based on test time input via transductive learning; and theoretically, attacking these defenses boils down to bilevel optimization, which seems to raise the difficulty for adaptive attacks. In this paper, we first formalize and analyze modeling aspects of transductive robustness. Then, we propose the principle of attacking model space for solving bilevel attack objectives, and present an instantiation of the principle which breaks previous transductive defenses. These attacks thus point to significant difficulties in the use of transductive learning to improve adversarial robustness. To this end, we present new theoretical and empirical evidence in support of the utility of transductive learning.
Robust Out-of-distribution Detection via Informative Outlier Mining
Jun 26, 2020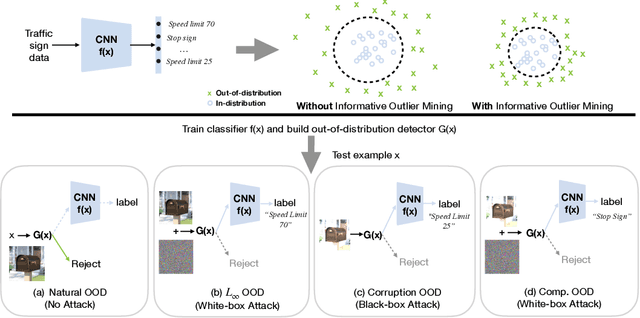


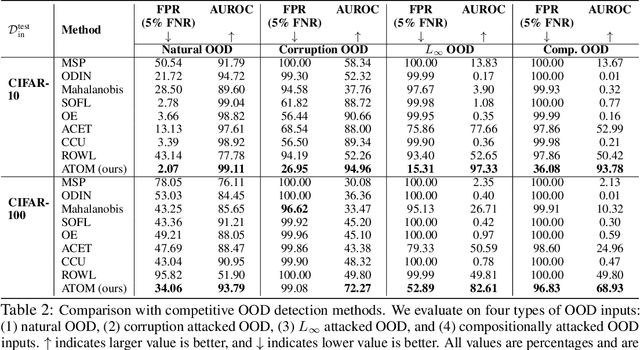
Detecting out-of-distribution (OOD) inputs is critical for safely deploying deep learning models in an open-world setting. However, existing OOD detection solutions can be brittle under small adversarial perturbations. In this paper, we propose a simple and effective method, Adversarial Training with informative Outlier Mining (ATOM), to robustify OOD detection. Our key observation is that while unlabeled data can be used as auxiliary OOD training data, the majority of these data points are not informative to improve the decision boundary of the OOD detector. We show that, by carefully choosing which outliers to train on, one can significantly improve the robustness of the OOD detector, and somewhat surprisingly, generalize to some adversarial attacks not seen during training. We provide additionally a unified evaluation framework that allows future research examining the robustness of OOD detection algorithms. ATOM achieves state-of-the-art performance under a broad family of natural and perturbed OOD evaluation tasks, surpassing previous methods by a large margin. Finally, we provide theoretical insights for the benefit of auxiliary unlabeled data and outlier mining.
Representation Bayesian Risk Decompositions and Multi-Source Domain Adaptation
Apr 22, 2020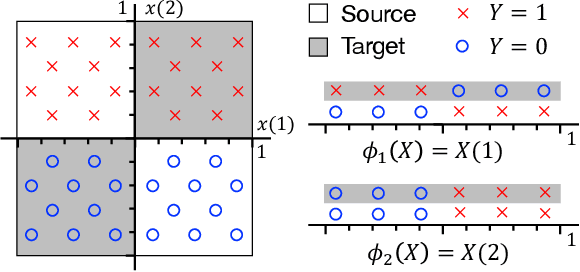
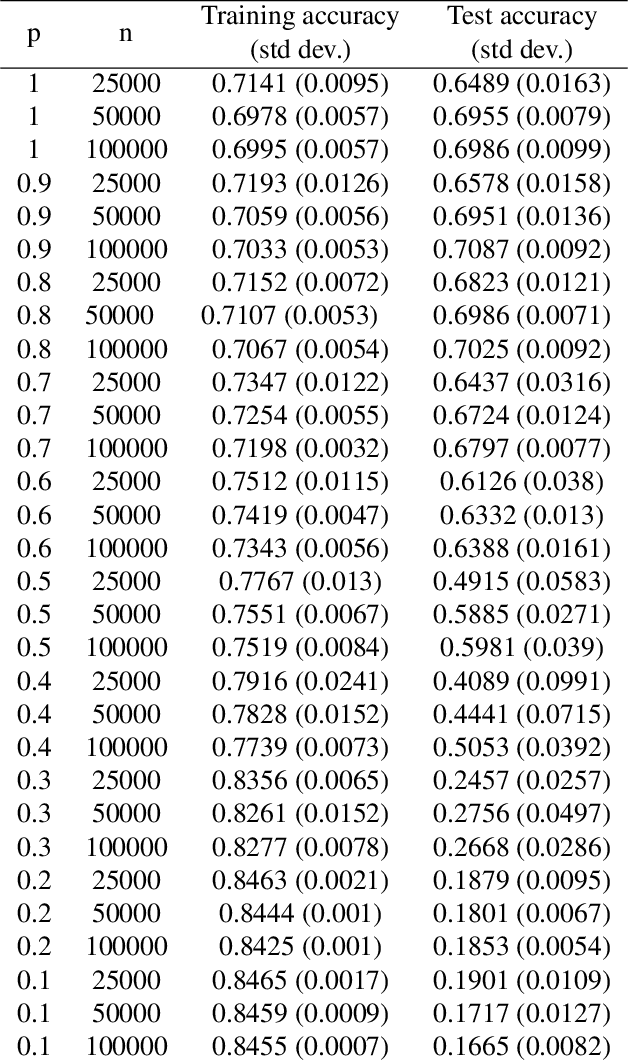
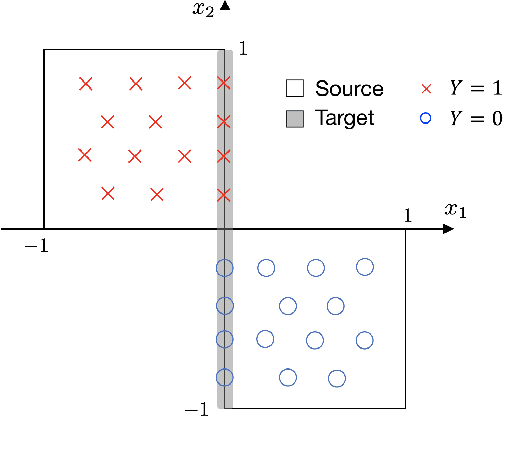
We consider representation learning (with hypothesis class $\mathcal{H} = \mathcal{F}\circ\mathcal{G}$) where training and test distributions can be different. Recent studies provide hints and failure examples for domain invariant representation learning, a common approach to this problem, but are inadequate for fully understanding the phenomena. In this paper, we provide new decompositions of risk which provide finer-grained explanations and clarify potential generalization issues. For Single-Source Domain Adaptation, we give an exact risk decomposition, an equality, where target risk is the sum of three factors: (1) source risk, (2) representation conditional label divergence, and (3) representation covariate shift. We derive a similar decomposition for the Multi-Source case. These decompositions reveal factors (2) and (3) as the precise reasons for failing to generalize. For example, we demonstrate that domain adversarial neural networks (DANN) attempt to regularize for (3) but miss (2), while a recent technique Invariant Risk Minimization (IRM) attempts to account for (2) but may suffer from not considering (3). We also verify these observations experimentally.
Robust Out-of-distribution Detection for Neural Networks
Apr 05, 2020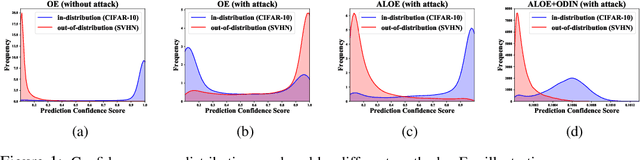
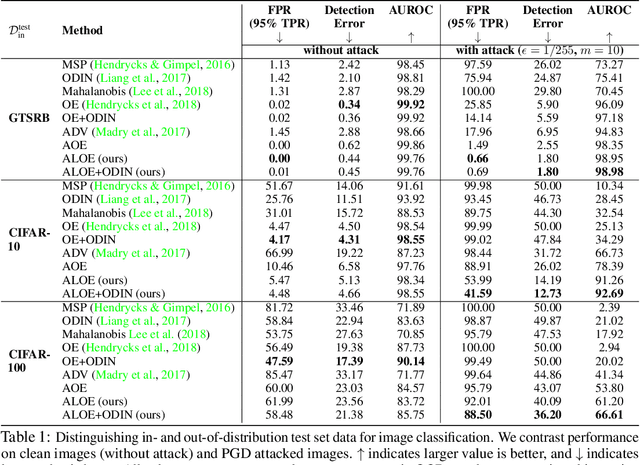
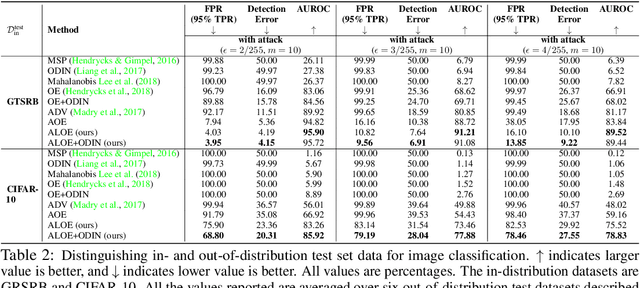
Detecting anomalous inputs is critical for safely deploying deep learning models in the real world. Existing approaches for detecting out-of-distribution (OOD) examples work well when evaluated on natural samples drawn from a sufficiently different distribution than the training data distribution. However, in this paper, we show that existing detection mechanisms can be extremely brittle when evaluating on inputs with minimal adversarial perturbations which don't change their semantics. Formally, we introduce a novel and challenging problem, Robust Out-of-Distribution Detection, and propose an algorithm that can fool existing OOD detectors by adding small perturbations to the inputs while preserving their semantics and thus the distributional membership. We take a first step to solve this challenge, and propose an effective algorithm called ALOE, which performs robust training by exposing the model to both adversarially crafted inlier and outlier examples. Our method can be flexibly combined with, and render existing methods robust. On common benchmark datasets, we show that ALOE substantially improves the robustness of state-of-the-art OOD detection, with 58.4% AUROC improvement on CIFAR-10 and 46.59% improvement on CIFAR-100. Finally, we provide theoretical analysis for our method, underpinning the empirical results above.
Query-Efficient Physical Hard-Label Attacks on Deep Learning Visual Classification
Feb 17, 2020
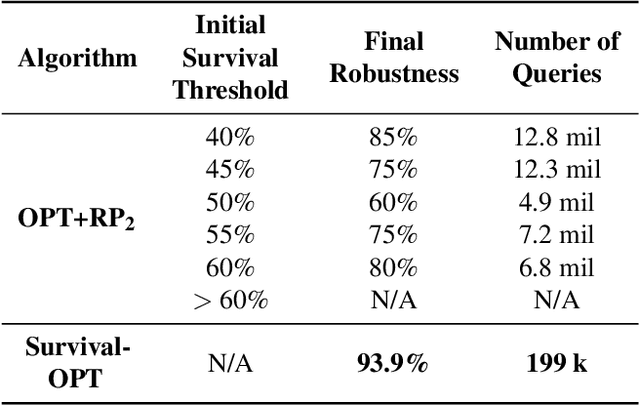

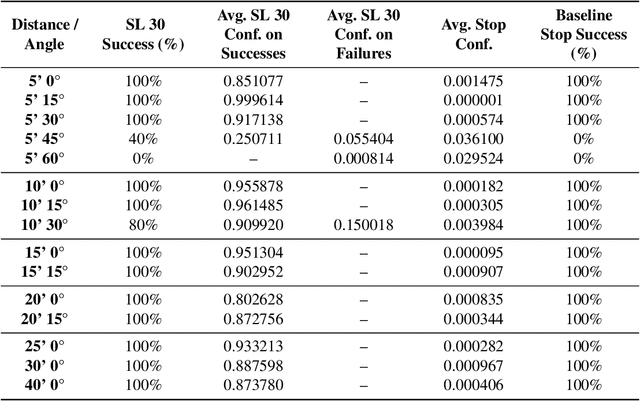
We present Survival-OPT, a physical adversarial example algorithm in the black-box hard-label setting where the attacker only has access to the model prediction class label. Assuming such limited access to the model is more relevant for settings such as proprietary cyber-physical and cloud systems than the whitebox setting assumed by prior work. By leveraging the properties of physical attacks, we create a novel approach based on the survivability of perturbations corresponding to physical transformations. Through simply querying the model for hard-label predictions, we optimize perturbations to survive in many different physical conditions and show that adversarial examples remain a security risk to cyber-physical systems (CPSs) even in the hard-label threat model. We show that Survival-OPT is query-efficient and robust: using fewer than 200K queries, we successfully attack a stop sign to be misclassified as a speed limit 30 km/hr sign in 98.5% of video frames in a drive-by setting. Survival-OPT also outperforms our baseline combination of existing hard-label and physical approaches, which required over 10x more queries for less robust results.
AI-GAN: Attack-Inspired Generation of Adversarial Examples
Feb 06, 2020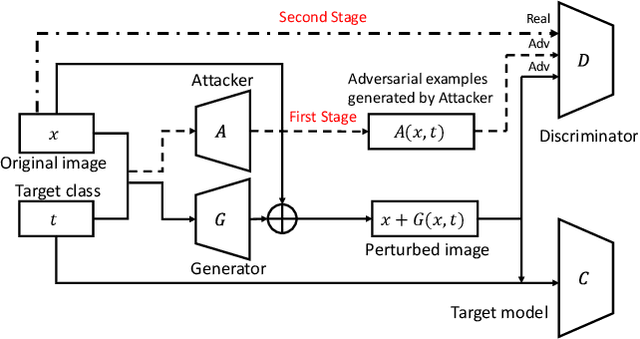

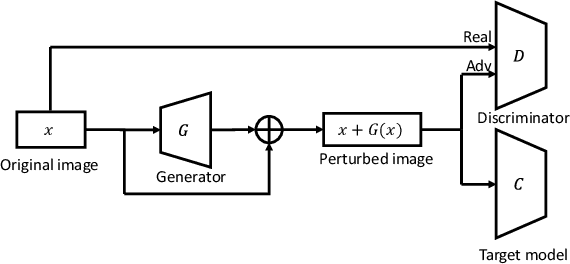
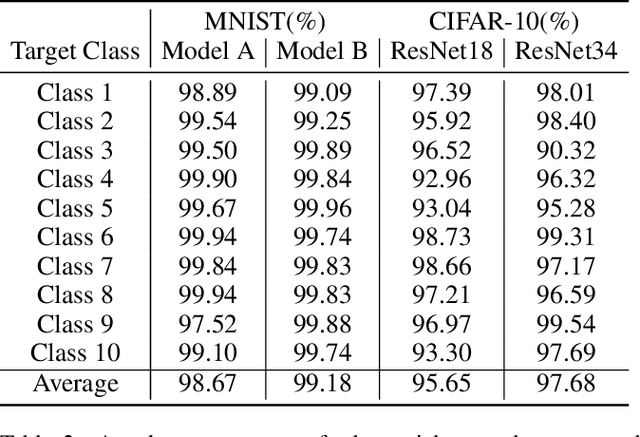
Adversarial examples that can fool deep models are mainly crafted by adding small perturbations imperceptible to human eyes. There are various optimization-based methods in the literature to generate adversarial perturbations, most of which are time-consuming. AdvGAN, a method proposed by Xiao~\emph{et al.}~in IJCAI~2018, employs Generative Adversarial Networks (GAN) to generate adversarial perturbation with original images as inputs, which is faster than optimization-based methods at inference time. AdvGAN, however, fixes the target classes in the training and we find it difficult to train AdvGAN when it is modified to take original images and target classes as inputs. In this paper, we propose \mbox{Attack-Inspired} GAN (\mbox{AI-GAN}) with a different training strategy to solve this problem. \mbox{AI-GAN} is a two-stage method, in which we use projected gradient descent (PGD) attack to inspire the training of GAN in the first stage and apply standard training of GAN in the second stage. Once trained, the Generator can approximate the conditional distribution of adversarial instances and generate \mbox{imperceptible} adversarial perturbations given different target classes. We conduct experiments and evaluate the performance of \mbox{AI-GAN} on MNIST and \mbox{CIFAR-10}. Compared with AdvGAN, \mbox{AI-GAN} achieves higher attack success rates with similar perturbation magnitudes.