 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIBR4D: Tracing-Guided Iterative Boundary Refinement for Efficient 4D Gaussian Segmentation
Feb 09, 2026Object-level segmentation in dynamic 4D Gaussian scenes remains challenging due to complex motion, occlusions, and ambiguous boundaries. In this paper, we present an efficient learning-free 4D Gaussian segmentation framework that lifts video segmentation masks to 4D spaces, whose core is a two-stage iterative boundary refinement, TIBR4D. The first stage is an Iterative Gaussian Instance Tracing (IGIT) at the temporal segment level. It progressively refines Gaussian-to-instance probabilities through iterative tracing, and extracts corresponding Gaussian point clouds that better handle occlusions and preserve completeness of object structures compared to existing one-shot threshold-based methods. The second stage is a frame-wise Gaussian Rendering Range Control (RCC) via suppressing highly uncertain Gaussians near object boundaries while retaining their core contributions for more accurate boundaries. Furthermore, a temporal segmentation merging strategy is proposed for IGIT to balance identity consistency and dynamic awareness. Longer segments enforce stronger multi-frame constraints for stable identities, while shorter segments allow identity changes to be captured promptly. Experiments on HyperNeRF and Neu3D demonstrate that our method produces accurate object Gaussian point clouds with clearer boundaries and higher efficiency compared to SOTA methods.
MMFL-Net: Multi-scale and Multi-granularity Feature Learning for Cross-domain Fashion Retrieval
Oct 27, 2022Instance-level image retrieval in fashion is a challenging issue owing to its increasing importance in real-scenario visual fashion search. Cross-domain fashion retrieval aims to match the unconstrained customer images as queries for photographs provided by retailers; however, it is a difficult task due to a wide range of consumer-to-shop (C2S) domain discrepancies and also considering that clothing image is vulnerable to various non-rigid deformations. To this end, we propose a novel multi-scale and multi-granularity feature learning network (MMFL-Net), which can jointly learn global-local aggregation feature representations of clothing images in a unified framework, aiming to train a cross-domain model for C2S fashion visual similarity. First, a new semantic-spatial feature fusion part is designed to bridge the semantic-spatial gap by applying top-down and bottom-up bidirectional multi-scale feature fusion. Next, a multi-branch deep network architecture is introduced to capture global salient, part-informed, and local detailed information, and extracting robust and discrimination feature embedding by integrating the similarity learning of coarse-to-fine embedding with the multiple granularities. Finally, the improved trihard loss, center loss, and multi-task classification loss are adopted for our MMFL-Net, which can jointly optimize intra-class and inter-class distance and thus explicitly improve intra-class compactness and inter-class discriminability between its visual representations for feature learning. Furthermore, our proposed model also combines the multi-task attribute recognition and classification module with multi-label semantic attributes and product ID labels. Experimental results demonstrate that our proposed MMFL-Net achieves significant improvement over the state-of-the-art methods on the two datasets, DeepFashion-C2S and Street2Shop.
* 27 pages, 12 figures, Published by <Multimedia Tools and Applications>
3D Instance Segmentation of MVS Buildings
Dec 18, 2021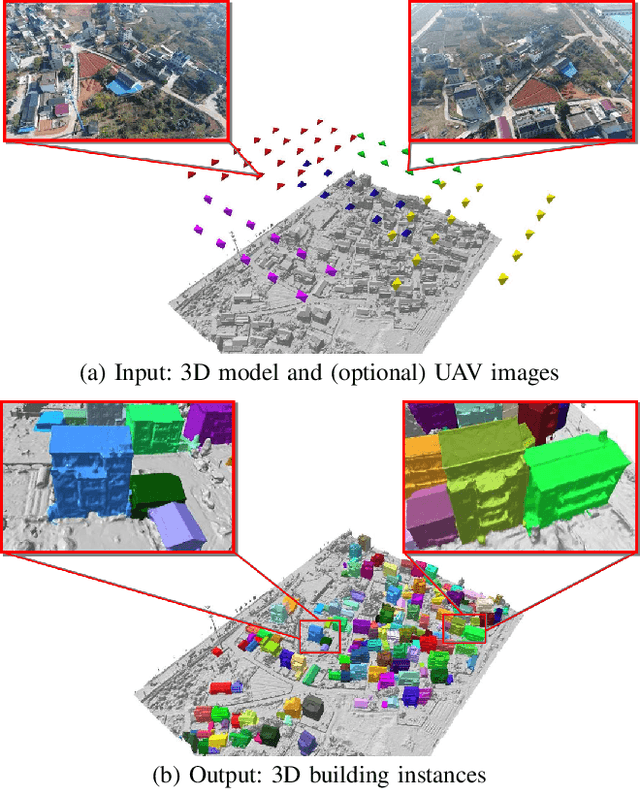
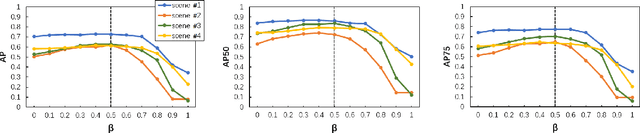
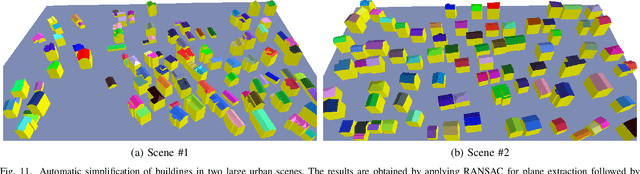

We present a novel framework for instance segmentation of 3D buildings from Multi-view Stereo (MVS) urban scenes. Unlike existing works focusing on semantic segmentation of an urban scene, the emphasis of this work lies in detecting and segmenting 3D building instances even if they are attached and embedded in a large and imprecise 3D surface model. Multi-view RGB images are first enhanced to RGBH images by adding a heightmap and are segmented to obtain all roof instances using a fine-tuned 2D instance segmentation neural network. Roof instance masks from different multi-view images are then clustered into global masks. Our mask clustering accounts for spatial occlusion and overlapping, which can eliminate segmentation ambiguities among multi-view images. Based on these global masks, 3D roof instances are segmented out by mask back-projections and extended to the entire building instances through a Markov random field (MRF) optimization. Quantitative evaluations and ablation studies have shown the effectiveness of all major steps of the method. A dataset for the evaluation of instance segmentation of 3D building models is provided as well. To the best of our knowledge, it is the first dataset for 3D urban buildings on the instance segmentation level.
Integrating Tensor Similarity to Enhance Clustering Performance
May 10, 2019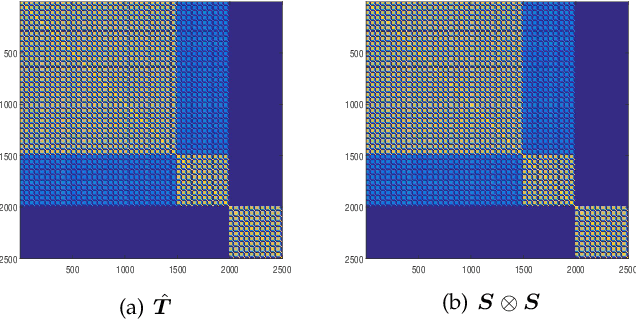
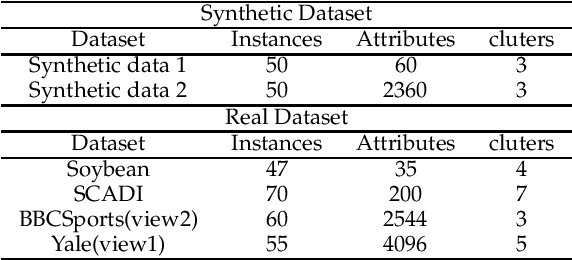
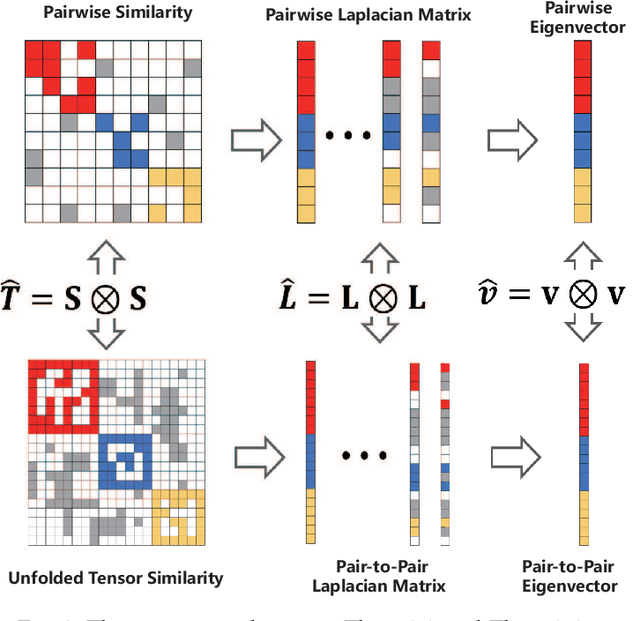

Clustering aims to separate observed data into different categories. The performance of popular clustering models relies on the sample-to-sample similarity. However, the pairwise similarity is prone to be corrupted by noise or outliers and thus deteriorates the subsequent clustering. A high-order relationship among samples-to-samples may elaborate the local manifold of the data and thus provide complementary information to guide the clustering. However, few studies have investigated the connection between high-order similarity and usual pairwise similarity. To fill this gap, we first define a high-order tensor similarity to exploit the samples-to-samples affinity relationship. We then establish the connection between tensor similarity and pairwise similarity, proving that the decomposable tensor similarity is the Kronecker product of the usual pairwise similarity and the non-decomposable tensor similarity is generalized to provide complementary information, which pairwise similarity fails to regard. Finally, the high-order tensor similarity and pairwise similarity (IPS2) were integrated collaboratively to enhance clustering performance by enjoying their merits. The proposed IPS2 is shown to perform superior or competitive to state-of-the-art methods on synthetic and real-world datasets. Extensive experiments demonstrated that tensor similarity is capable to boost the performance of the classical clustering method.