 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModulated binary cliquenet
Feb 27, 2019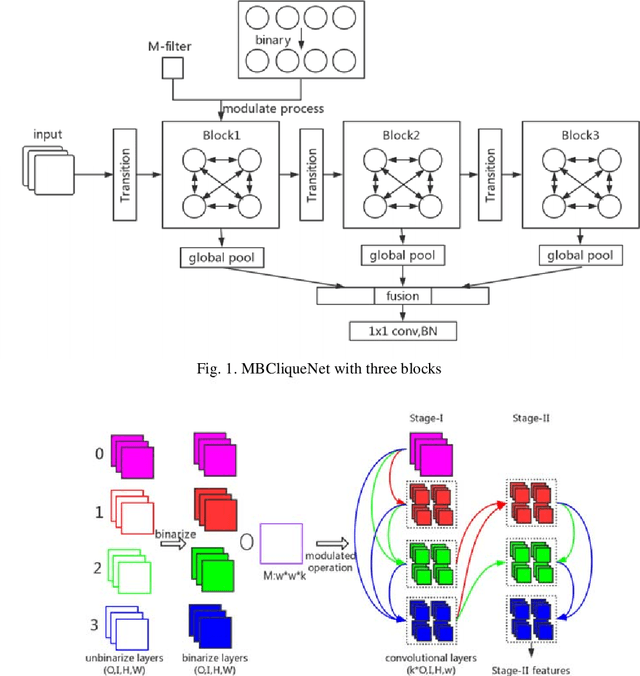

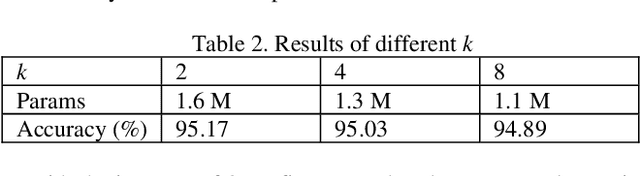
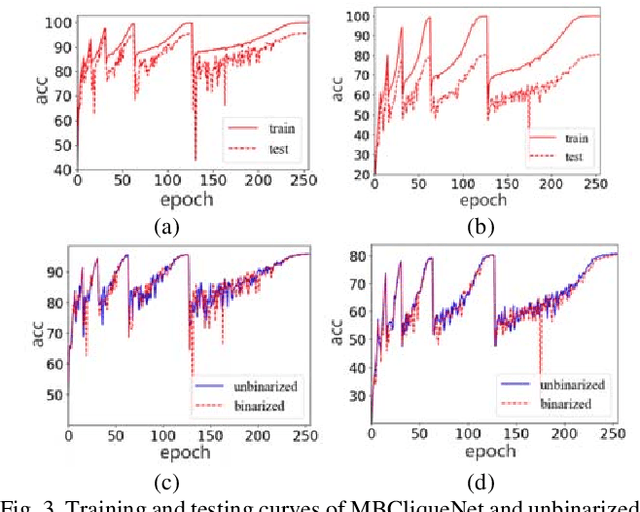
Although Convolutional Neural Networks (CNNs) achieve effectiveness in various computer vision tasks, the significant requirement of storage of such networks hinders the deployment on computationally limited devices. In this paper, we propose a new compact and portable deep learning network named Modulated Binary Cliquenet (MBCliqueNet) aiming to improve the portability of CNNs based on binarized filters while achieving comparable performance with the full-precision CNNs like Resnet. In MBCliqueNet, we introduce a novel modulated operation to approximate the unbinarized filters and gives an initialization method to speed up its convergence. We reduce the extra parameters caused by modulated operation with parameters sharing. As a result, the proposed MBCliqueNet can reduce the required storage space of convolutional filters by a factor of at least 32, in contrast to the full-precision model, and achieve better performance than other state-of-the-art binarized models. More importantly, our model compares even better with some full-precision models like Resnet on the dataset we used.
Fractional Wavelet Scattering Network and Applications
Jun 30, 2018
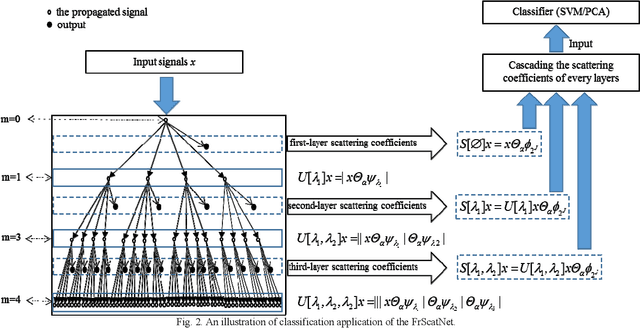
Objective: The present study introduces a fractional wavelet scattering network (FrScatNet), which is a generalized translation invariant version of the classical wavelet scattering network (ScatNet). Methods: In our approach, the FrScatNet is constructed based on the fractional wavelet transform (FRWT). The fractional scattering coefficients are iteratively computed using FRWTs and modulus operators. The feature vectors constructed by fractional scattering coefficients are usually used for signal classification. In this work, an application example of FrScatNet is provided in order to assess its performance on pathological images. Firstly, the FrScatNet extracts feature vectors from patches of the original histological images under different orders. Then we classify those patches into target (benign or malignant) and background groups. And the FrScatNet property is analyzed by comparing error rates computed from different fractional orders respectively. Based on the above pathological image classification, a gland segmentation algorithm is proposed by combining the boundary information and the gland location. Results: The error rates for different fractional orders of FrScatNet are examined and show that the classification accuracy is significantly improved in fractional scattering domain. We also compare the FrScatNet based gland segmentation method with those proposed in the 2015 MICCAI Gland Segmentation Challenge and our method achieves comparable results. Conclusion: The FrScatNet is shown to achieve accurate and robust results. More stable and discriminative fractional scattering coefficients are obtained by the FrScatNet in this work. Significance: The added fractional order parameter is able to analyze the image in the fractional scattering domain.
Demystifying AlphaGo Zero as AlphaGo GAN
Nov 24, 2017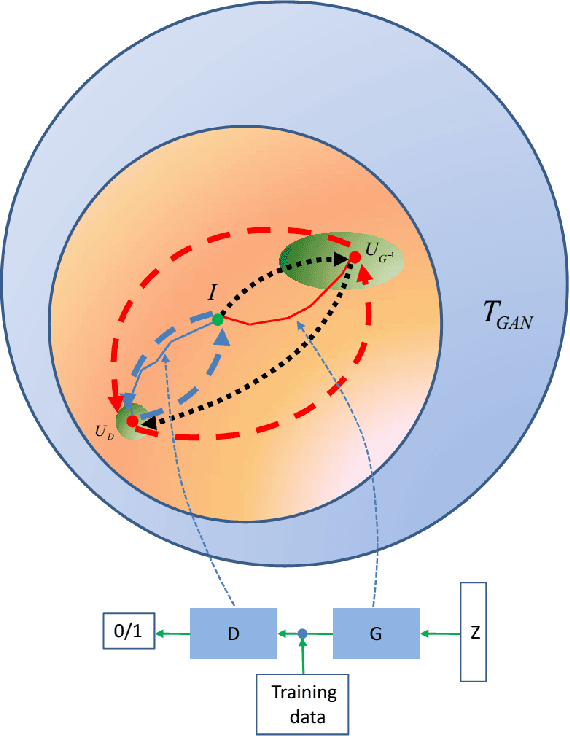
The astonishing success of AlphaGo Zero\cite{Silver_AlphaGo} invokes a worldwide discussion of the future of our human society with a mixed mood of hope, anxiousness, excitement and fear. We try to dymystify AlphaGo Zero by a qualitative analysis to indicate that AlphaGo Zero can be understood as a specially structured GAN system which is expected to possess an inherent good convergence property. Thus we deduct the success of AlphaGo Zero may not be a sign of a new generation of AI.
How deep learning works --The geometry of deep learning
Oct 30, 2017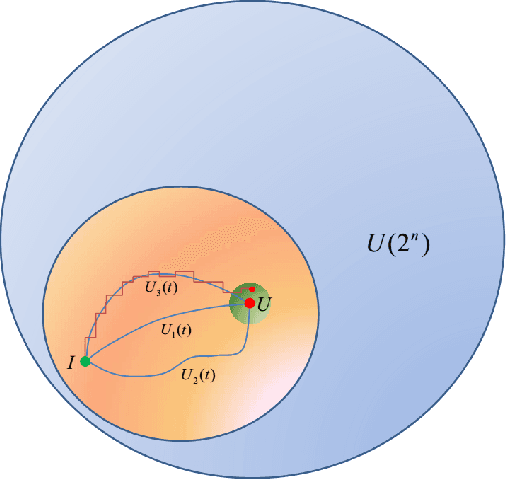
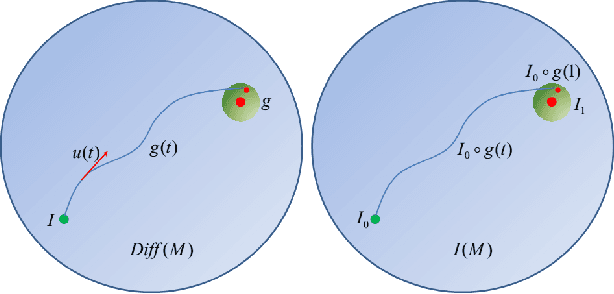
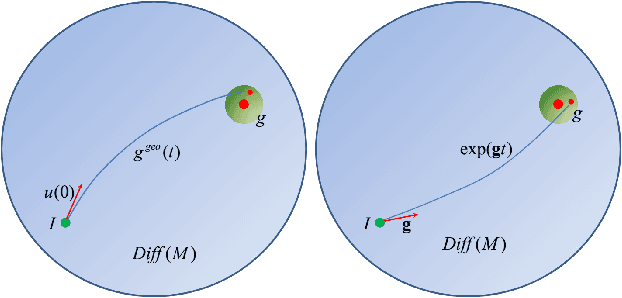
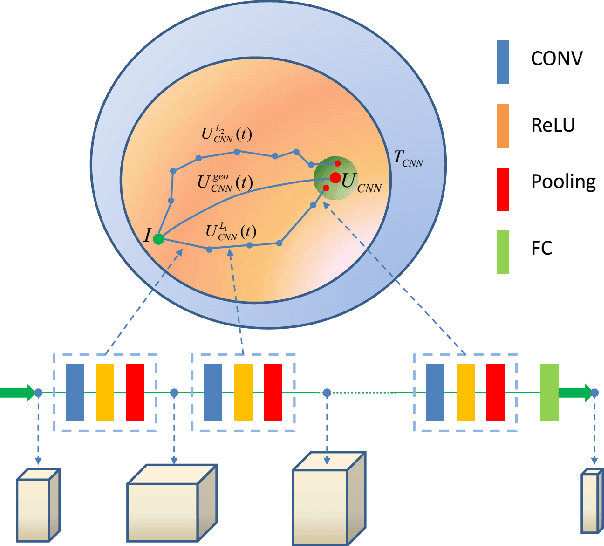
Why and how that deep learning works well on different tasks remains a mystery from a theoretical perspective. In this paper we draw a geometric picture of the deep learning system by finding its analogies with two existing geometric structures, the geometry of quantum computations and the geometry of the diffeomorphic template matching. In this framework, we give the geometric structures of different deep learning systems including convolutional neural networks, residual networks, recursive neural networks, recurrent neural networks and the equilibrium prapagation framework. We can also analysis the relationship between the geometrical structures and their performance of different networks in an algorithmic level so that the geometric framework may guide the design of the structures and algorithms of deep learning systems.
MomentsNet: a simple learning-free method for binary image recognition
Feb 22, 2017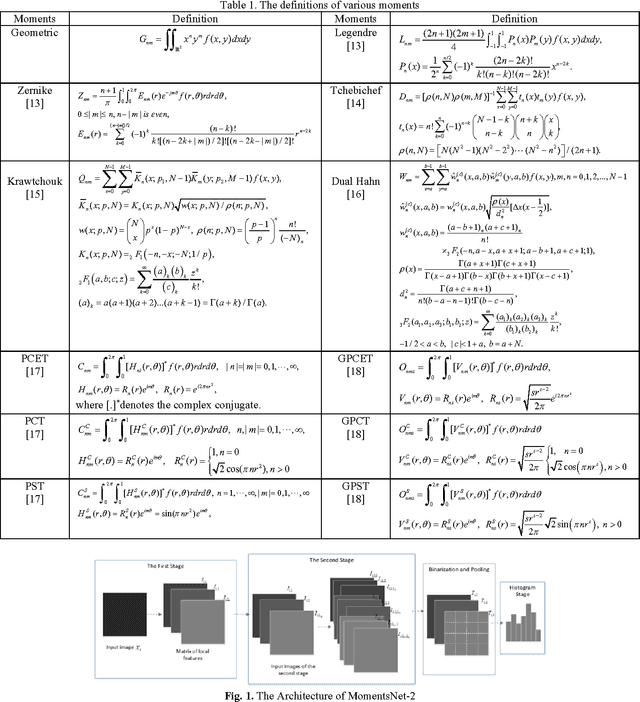

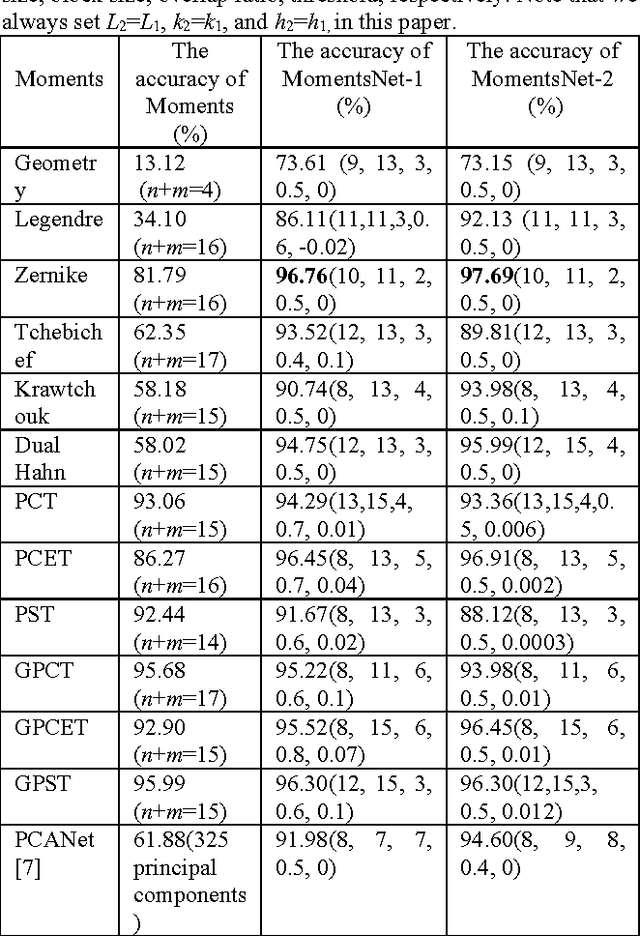
In this paper, we propose a new simple and learning-free deep learning network named MomentsNet, whose convolution layer, nonlinear processing layer and pooling layer are constructed by Moments kernels, binary hashing and block-wise histogram, respectively. Twelve typical moments (including geometrical moment, Zernike moment, Tchebichef moment, etc.) are used to construct the MomentsNet whose recognition performance for binary image is studied. The results reveal that MomentsNet has better recognition performance than its corresponding moments in almost all cases and ZernikeNet achieves the best recognition performance among MomentsNet constructed by twelve moments. ZernikeNet also shows better recognition performance on binary image database than that of PCANet, which is a learning-based deep learning network.
PCANet: An energy perspective
Mar 03, 2016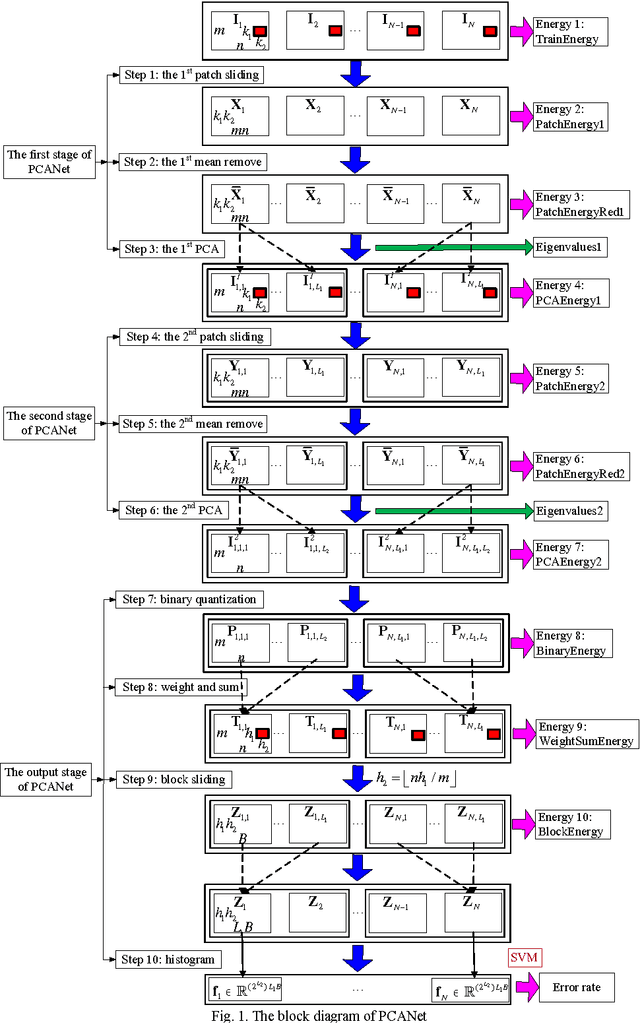
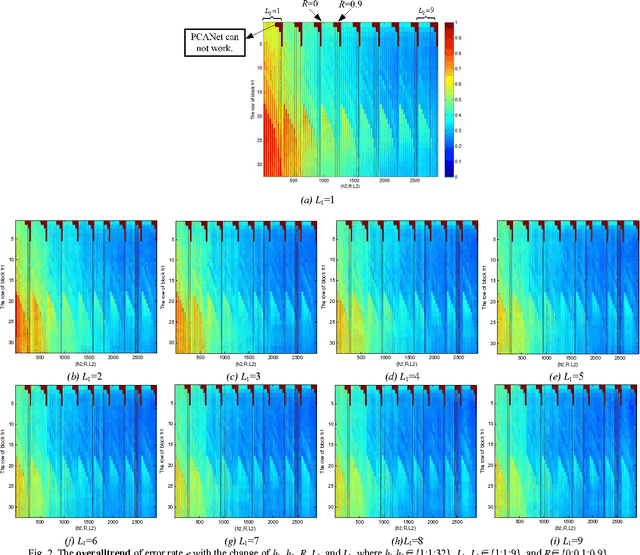
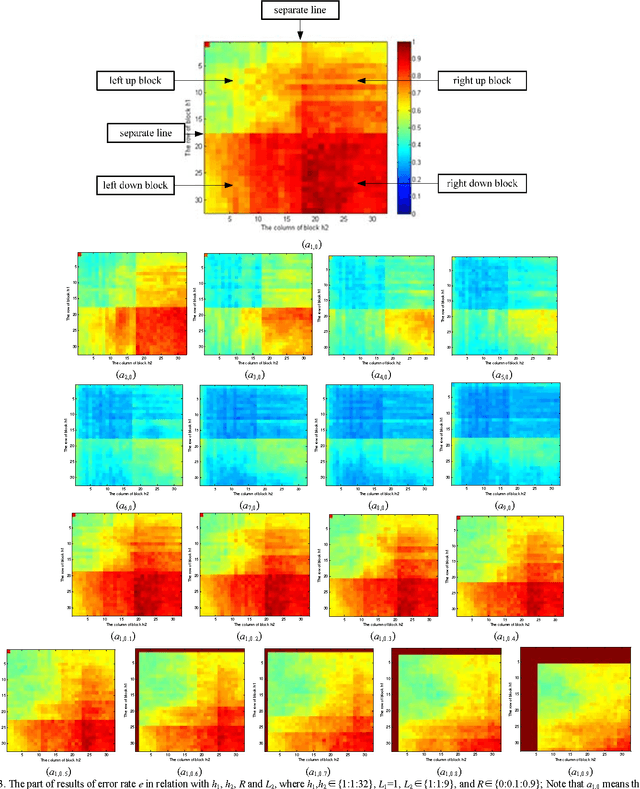
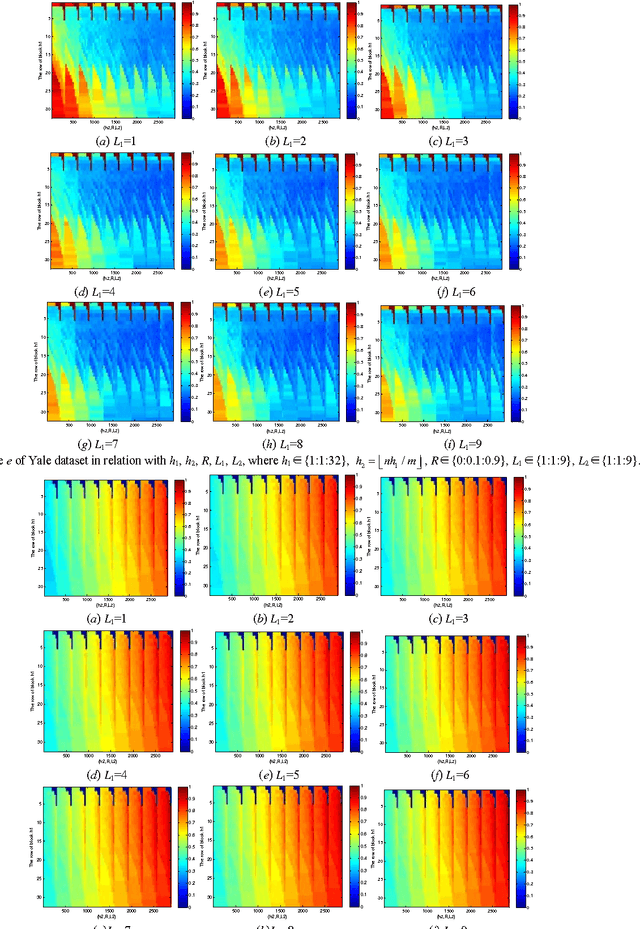
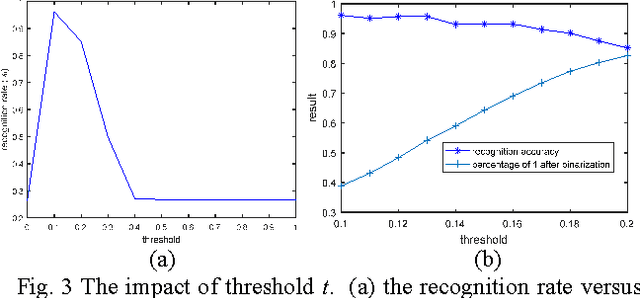
The principal component analysis network (PCANet), which is one of the recently proposed deep learning architectures, achieves the state-of-the-art classification accuracy in various databases. However, the explanation of the PCANet is lacked. In this paper, we try to explain why PCANet works well from energy perspective point of view based on a set of experiments. The impact of various parameters on the error rate of PCANet is analyzed in depth. It was found that this error rate is correlated with the logarithm of energy of image. The proposed energy explanation approach can be used as a testing method for checking if every step of the constructed networks is necessary.
Kernel principal component analysis network for image classification
Dec 20, 2015In order to classify the nonlinear feature with linear classifier and improve the classification accuracy, a deep learning network named kernel principal component analysis network (KPCANet) is proposed. First, mapping the data into higher space with kernel principal component analysis to make the data linearly separable. Then building a two-layer KPCANet to obtain the principal components of image. Finally, classifying the principal components with linearly classifier. Experimental results show that the proposed KPCANet is effective in face recognition, object recognition and hand-writing digits recognition, it also outperforms principal component analysis network (PCANet) generally as well. Besides, KPCANet is invariant to illumination and stable to occlusion and slight deformation.
Color Image Classification via Quaternion Principal Component Analysis Network
Mar 05, 2015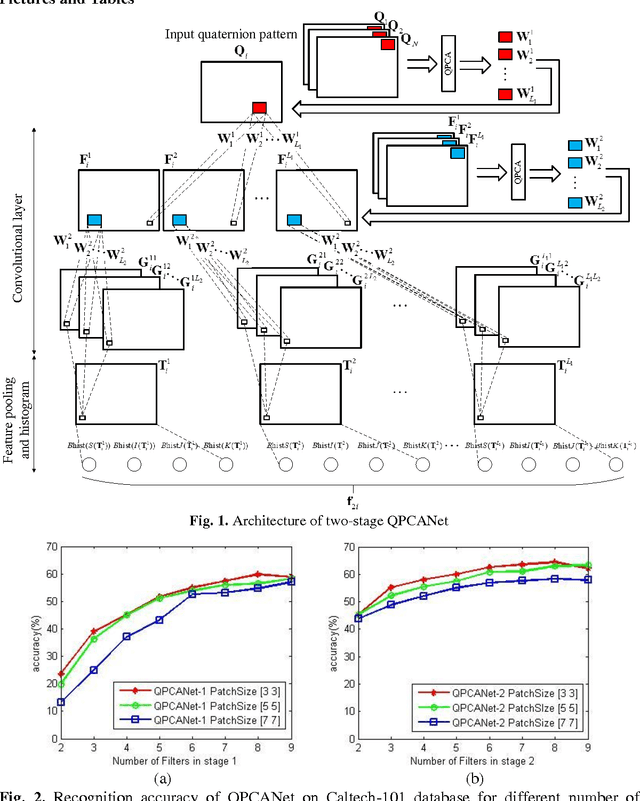

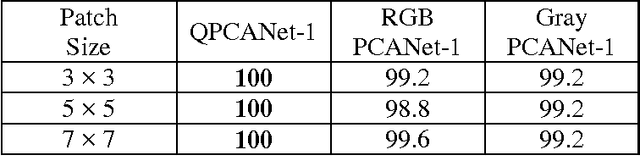

The Principal Component Analysis Network (PCANet), which is one of the recently proposed deep learning architectures, achieves the state-of-the-art classification accuracy in various databases. However, the performance of PCANet may be degraded when dealing with color images. In this paper, a Quaternion Principal Component Analysis Network (QPCANet), which is an extension of PCANet, is proposed for color images classification. Compared to PCANet, the proposed QPCANet takes into account the spatial distribution information of color images and ensures larger amount of intra-class invariance of color images. Experiments conducted on different color image datasets such as Caltech-101, UC Merced Land Use, Georgia Tech face and CURet have revealed that the proposed QPCANet achieves higher classification accuracy than PCANet.
Tensor object classification via multilinear discriminant analysis network
Nov 05, 2014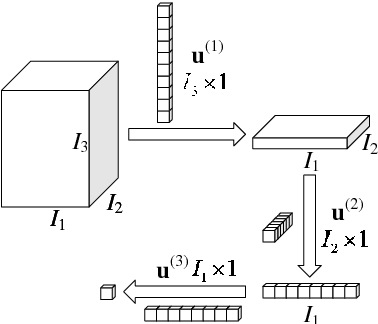
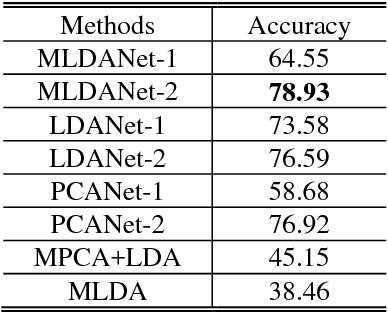
This paper proposes a multilinear discriminant analysis network (MLDANet) for the recognition of multidimensional objects, known as tensor objects. The MLDANet is a variation of linear discriminant analysis network (LDANet) and principal component analysis network (PCANet), both of which are the recently proposed deep learning algorithms. The MLDANet consists of three parts: 1) The encoder learned by MLDA from tensor data. 2) Features maps ob-tained from decoder. 3) The use of binary hashing and histogram for feature pooling. A learning algorithm for MLDANet is described. Evaluations on UCF11 database indicate that the proposed MLDANet outperforms the PCANet, LDANet, MPCA + LDA, and MLDA in terms of classification for tensor objects.
Multilinear Principal Component Analysis Network for Tensor Object Classification
Nov 05, 2014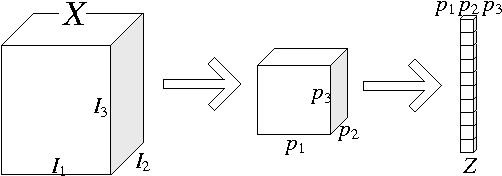
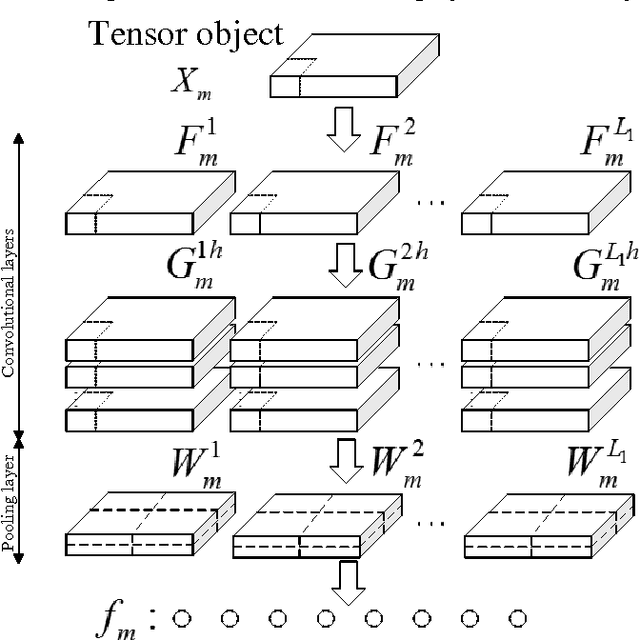
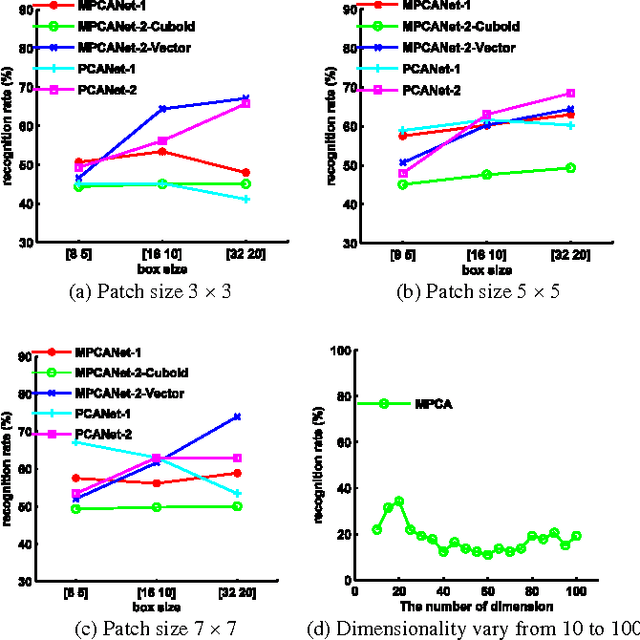

The recently proposed principal component analysis network (PCANet) has been proved high performance for visual content classification. In this letter, we develop a tensorial extension of PCANet, namely, multilinear principal analysis component network (MPCANet), for tensor object classification. Compared to PCANet, the proposed MPCANet uses the spatial structure and the relationship between each dimension of tensor objects much more efficiently. Experiments were conducted on different visual content datasets including UCF sports action video sequences database and UCF11 database. The experimental results have revealed that the proposed MPCANet achieves higher classification accuracy than PCANet for tensor object classification.