 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Reliable Social A/B Testing: Spillover-Contained Clustering with Robust Post-Experiment Analysis
Feb 09, 2026A/B testing is the foundation of decision-making in online platforms, yet social products often suffer from network interference: user interactions cause treatment effects to spill over into the control group. Such spillovers bias causal estimates and undermine experimental conclusions. Existing approaches face key limitations: user-level randomization ignores network structure, while cluster-based methods often rely on general-purpose clustering that is not tailored for spillover containment and has difficulty balancing unbiasedness and statistical power at scale. We propose a spillover-contained experimentation framework with two stages. In the pre-experiment stage, we build social interaction graphs and introduce a Balanced Louvain algorithm that produces stable, size-balanced clusters while minimizing cross-cluster edges, enabling reliable cluster-based randomization. In the post-experiment stage, we develop a tailored CUPAC estimator that leverages pre-experiment behavioral covariates to reduce the variance induced by cluster-level assignment, thereby improving statistical power. Together, these components provide both structural spillover containment and robust statistical inference. We validate our approach through large-scale social sharing experiments on Kuaishou, a platform serving hundreds of millions of users. Results show that our method substantially reduces spillover and yields more accurate assessments of social strategies than traditional user-level designs, establishing a reliable and scalable framework for networked A/B testing.
Multi-task Sentence Encoding Model for Semantic Retrieval in Question Answering Systems
Nov 18, 2019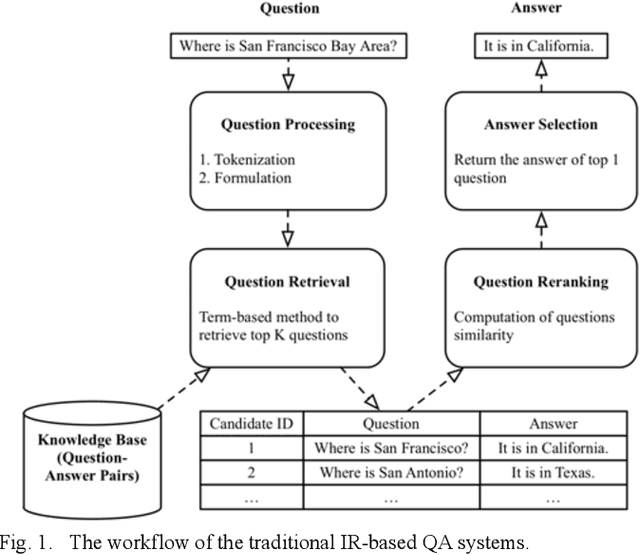
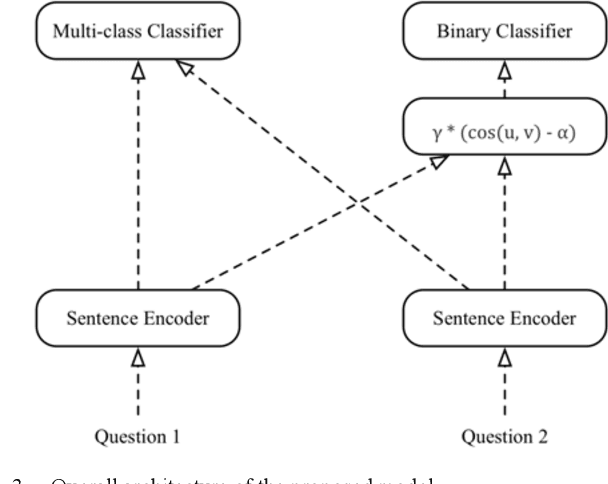
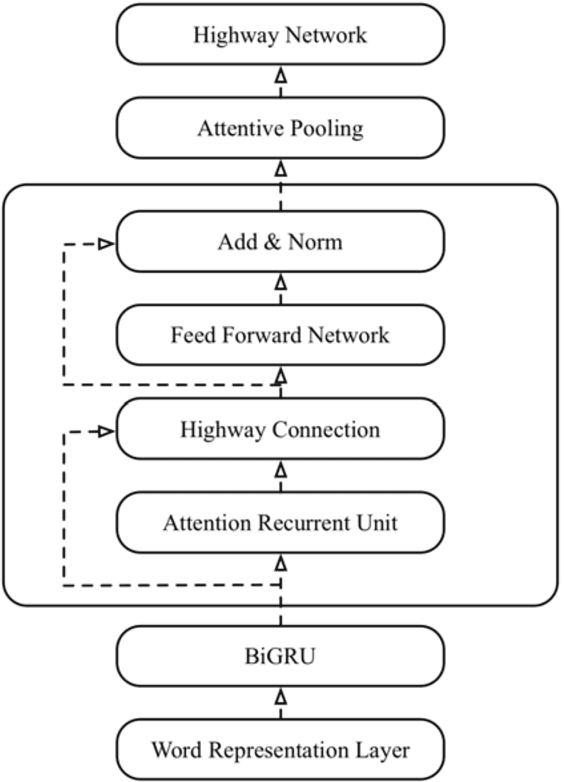
Question Answering (QA) systems are used to provide proper responses to users' questions automatically. Sentence matching is an essential task in the QA systems and is usually reformulated as a Paraphrase Identification (PI) problem. Given a question, the aim of the task is to find the most similar question from a QA knowledge base. In this paper, we propose a Multi-task Sentence Encoding Model (MSEM) for the PI problem, wherein a connected graph is employed to depict the relation between sentences, and a multi-task learning model is applied to address both the sentence matching and sentence intent classification problem. In addition, we implement a general semantic retrieval framework that combines our proposed model and the Approximate Nearest Neighbor (ANN) technology, which enables us to find the most similar question from all available candidates very quickly during online serving. The experiments show the superiority of our proposed method as compared with the existing sentence matching models.