 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a Dual-Stage Vision Transformer Model for Lung Disease Classification
Sep 26, 2024Lung diseases have become a prevalent problem throughout the United States, affecting over 34 million people. Accurate and timely diagnosis of the different types of lung diseases is critical, and Artificial Intelligence (AI) methods could speed up these processes. A dual-stage vision transformer is built throughout this research by integrating a Vision Transformer (ViT) and a Swin Transformer to classify 14 different lung diseases from X-ray scans of patients with these diseases. The proposed model achieved an accuracy of 92.06\% when making predictions on an unseen testing subset of the dataset after data preprocessing and training the neural network. The model showed promise for accurately classifying lung diseases and diagnosing patients who suffer from these harmful diseases.
Channel Modeling Framework for Both Communications and Bistatic Sensing Under 3GPP Standard
Aug 21, 2024



Integrated sensing and communications (ISAC) is considered a promising technology in the B5G/6G networks. The channel model is essential for an ISAC system to evaluate the communication and sensing performance. Most existing channel modeling studies focus on the monostatic ISAC channel. In this paper, the channel modeling framework for bistatic ISAC is considered. The proposed channel modeling framework extends the current 3GPP channel modeling framework and ensures the compatibility with the communication channel model. To support the bistatic sensing function, several key features for sensing are added. First, more clusters with weaker power are generated and retained to characterize the potential sensing targets. Second, the target model can be either deterministic or statistical, based on different sensing scenarios. Furthermore, for the statistical case, different reflection models are employed in the generation of rays, taking into account spatial coherence. The effectiveness of the proposed bistatic ISAC channel model framework is validated by both ray tracing simulations and experiment studies. The compatibility with the 3GPP communication channel model and how to use this framework for sensing evaluation are also demonstrated.
Leveraging Data Mining, Active Learning, and Domain Adaptation in a Multi-Stage, Machine Learning-Driven Approach for the Efficient Discovery of Advanced Acidic Oxygen Evolution Electrocatalysts
Jul 05, 2024



Developing advanced catalysts for acidic oxygen evolution reaction (OER) is crucial for sustainable hydrogen production. This study introduces a novel, multi-stage machine learning (ML) approach to streamline the discovery and optimization of complex multi-metallic catalysts. Our method integrates data mining, active learning, and domain adaptation throughout the materials discovery process. Unlike traditional trial-and-error methods, this approach systematically narrows the exploration space using domain knowledge with minimized reliance on subjective intuition. Then the active learning module efficiently refines element composition and synthesis conditions through iterative experimental feedback. The process culminated in the discovery of a promising Ru-Mn-Ca-Pr oxide catalyst. Our workflow also enhances theoretical simulations with domain adaptation strategy, providing deeper mechanistic insights aligned with experimental findings. By leveraging diverse data sources and multiple ML strategies, we establish an efficient pathway for electrocatalyst discovery and optimization. This comprehensive, data-driven approach represents a paradigm shift and potentially new benchmark in electrocatalysts research.
Learning nonparametric DAGs with incremental information via high-order HSIC
Aug 11, 2023



Score-based methods for learning Bayesain networks(BN) aim to maximizing the global score functions. However, if local variables have direct and indirect dependence simultaneously, the global optimization on score functions misses edges between variables with indirect dependent relationship, of which scores are smaller than those with direct dependent relationship. In this paper, we present an identifiability condition based on a determined subset of parents to identify the underlying DAG. By the identifiability condition, we develop a two-phase algorithm namely optimal-tuning (OT) algorithm to locally amend the global optimization. In the optimal phase, an optimization problem based on first-order Hilbert-Schmidt independence criterion (HSIC) gives an estimated skeleton as the initial determined parents subset. In the tuning phase, the skeleton is locally tuned by deletion, addition and DAG-formalization strategies using the theoretically proved incremental properties of high-order HSIC. Numerical experiments for different synthetic datasets and real-world datasets show that the OT algorithm outperforms existing methods. Especially in Sigmoid Mix model with the size of the graph being ${\rm\bf d=40}$, the structure intervention distance (SID) of the OT algorithm is 329.7 smaller than the one obtained by CAM, which indicates that the graph estimated by the OT algorithm misses fewer edges compared with CAM.
Information Cocoons in Online Navigation
Sep 14, 2021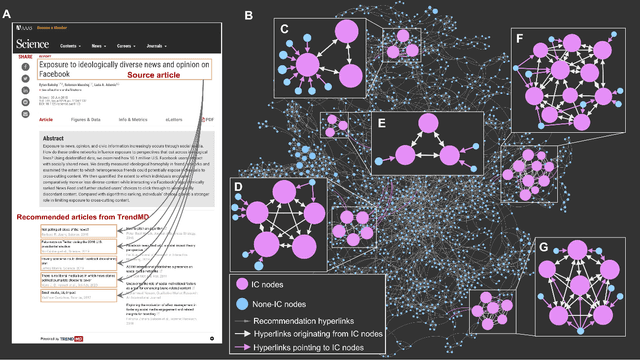
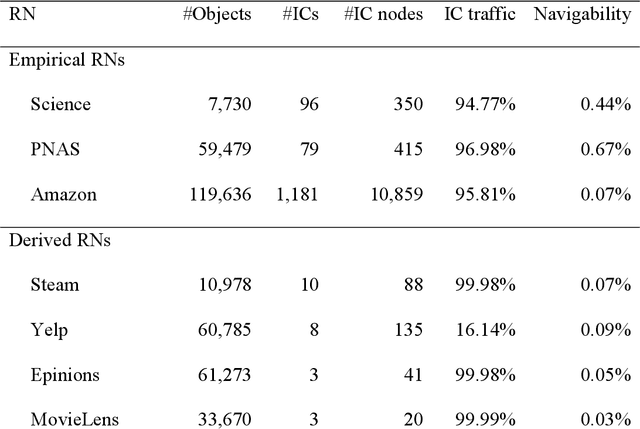
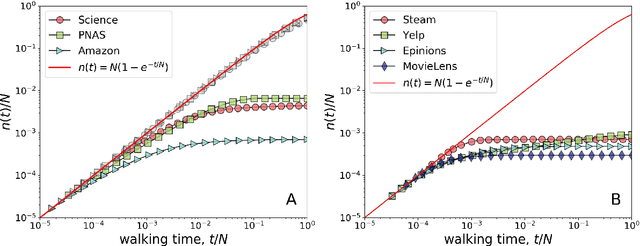
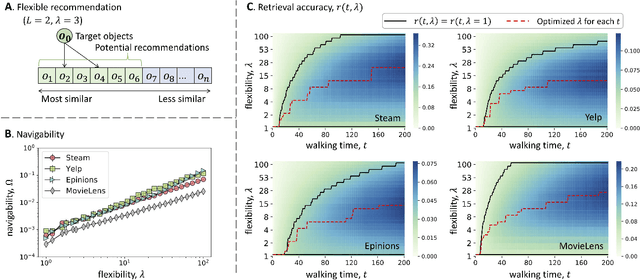
Social media and online navigation bring us enjoyable experience in accessing information, and simultaneously create information cocoons (ICs) in which we are unconsciously trapped with limited and biased information. We provide a formal definition of IC in the scenario of online navigation. Subsequently, by analyzing real recommendation networks extracted from Science, PNAS and Amazon websites, and testing mainstream algorithms in disparate recommender systems, we demonstrate that similarity-based recommendation techniques result in ICs, which suppress the system navigability by hundreds of times. We further propose a flexible recommendation strategy that solves the IC-induced problem and improves retrieval accuracy in navigation, demonstrated by simulations on real data and online experiments on the largest video website in China.
Superpixel Segmentation Using Gaussian Mixture Model
Feb 21, 2017
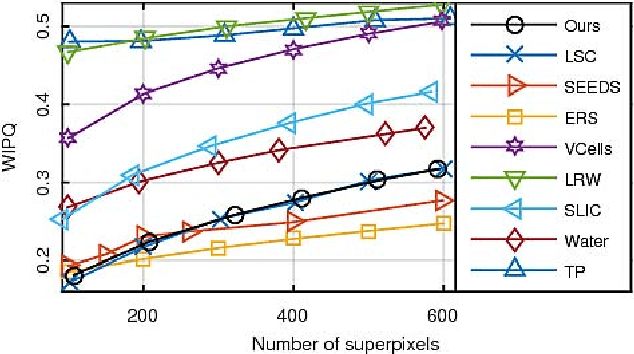
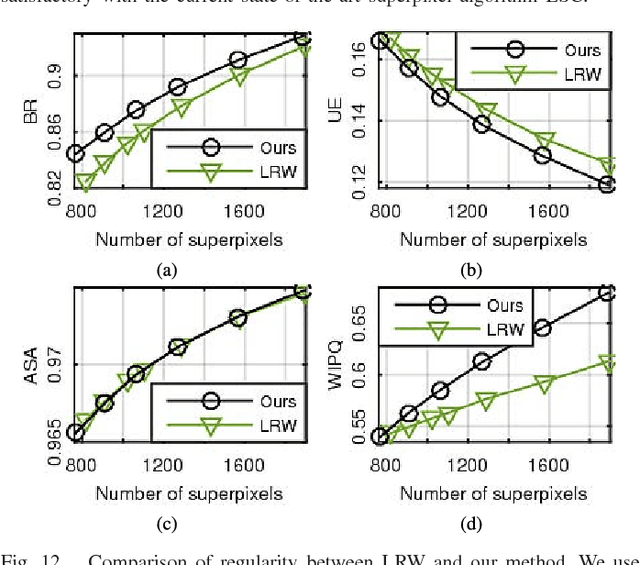
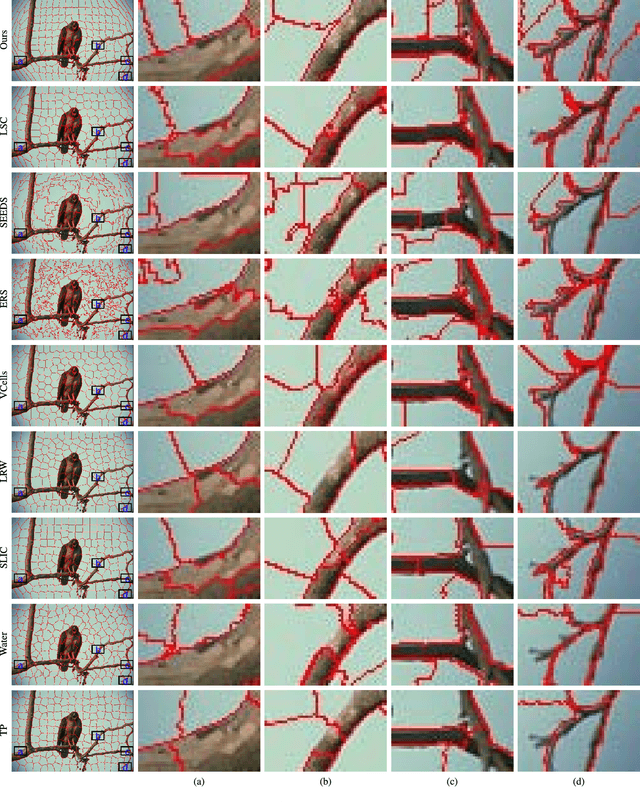
Superpixel segmentation algorithms are to partition an image into perceptually coherence atomic regions by assigning every pixel a superpixel label. Those algorithms have been wildly used as a preprocessing step in computer vision works, as they can enormously reduce the number of entries of subsequent algorithms. In this work, we propose an alternative superpixel segmentation method based on Gaussian mixture model (GMM) by assuming that each superpixel corresponds to a Gaussian distribution, and assuming that each pixel is generated by first randomly choosing one distribution from several Gaussian distributions which are defined to be related to that pixel, and then the pixel is drawn from the selected distribution. Based on this assumption, each pixel is supposed to be drawn from a mixture of Gaussian distributions with unknown parameters (GMM). An algorithm based on expectation-maximization method is applied to estimate the unknown parameters. Once the unknown parameters are obtained, the superpixel label of a pixel is determined by a posterior probability. The success of applying GMM to superpixel segmentation depends on the two major differences between the traditional GMM-based clustering and the proposed one: data points in our model may be non-identically distributed, and we present an approach to control the shape of the estimated Gaussian functions by adjusting their covariance matrices. Our method is of linear complexity with respect to the number of pixels. The proposed algorithm is inherently parallel and can get faster speed by adding simple OpenMP directives to our implementation. According to our experiments, our algorithm outperforms the state-of-the-art superpixel algorithms in accuracy and presents a competitive performance in computational efficiency.