 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Reasoning Fidelity in Visual Text Generation
Jun 03, 2026Recent text-to-image (T2I) models can render highly legible and well-structured text within images, enabling applications including document generation and slide generation. However, it remains unclear whether such systems faithfully preserve reasoning ability when complex solutions must be expressed directly through rendered text, or whether they merely imitate surface-level patterns. We investigate this question by evaluating reasoning fidelity in visual text generation, where models must express complete reasoning processes as images. Our evaluation includes long text rendering, factual knowledge probing, context understanding, and multi-step reasoning. Across these settings, we find that current T2I models frequently produce semantic errors, logical inconsistencies, and incorrect intermediate steps, even when the rendered text appears visually clear. These failures contrast with the strong reasoning performance of text-only models on the same tasks. Our findings reveal a substantial gap between visual text generation and procedural reasoning, motivating more reliable visual text reasoning.
From Behavioral Performance to Internal Competence: Interpreting Vision-Language Models with VLM-Lens
Oct 02, 2025We introduce VLM-Lens, a toolkit designed to enable systematic benchmarking, analysis, and interpretation of vision-language models (VLMs) by supporting the extraction of intermediate outputs from any layer during the forward pass of open-source VLMs. VLM-Lens provides a unified, YAML-configurable interface that abstracts away model-specific complexities and supports user-friendly operation across diverse VLMs. It currently supports 16 state-of-the-art base VLMs and their over 30 variants, and is extensible to accommodate new models without changing the core logic. The toolkit integrates easily with various interpretability and analysis methods. We demonstrate its usage with two simple analytical experiments, revealing systematic differences in the hidden representations of VLMs across layers and target concepts. VLM-Lens is released as an open-sourced project to accelerate community efforts in understanding and improving VLMs.
Mcity Data Collection for Automated Vehicles Study
Dec 12, 2019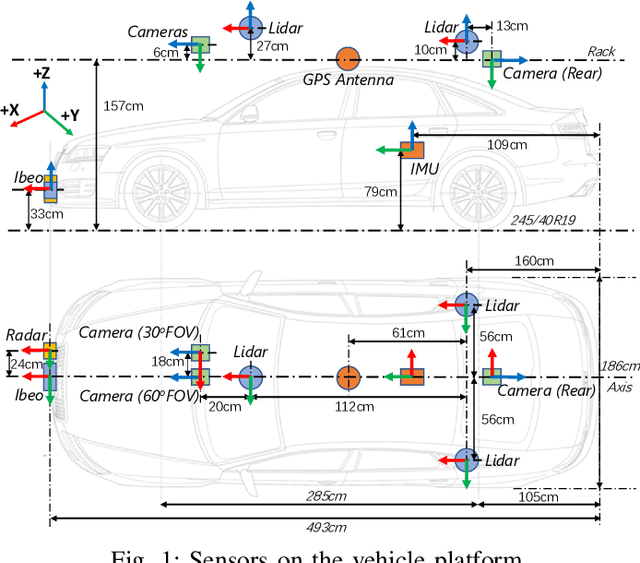
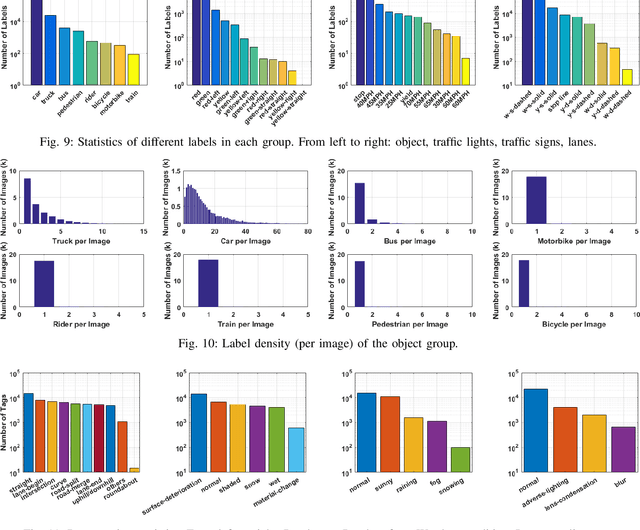
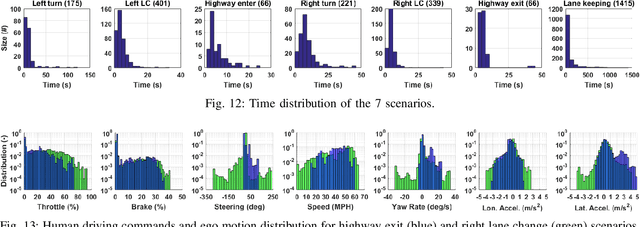
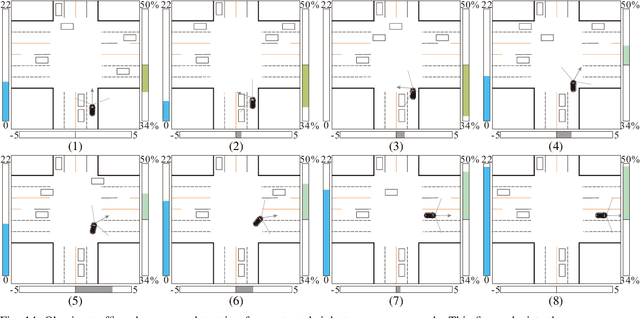
The main goal of this paper is to introduce the data collection effort at Mcity targeting automated vehicle development. We captured a comprehensive set of data from a set of perception sensors (Lidars, Radars, Cameras) as well as vehicle steering/brake/throttle inputs and an RTK unit. Two in-cabin cameras record the human driver's behaviors for possible future use. The naturalistic driving on selected open roads is recorded at different time of day and weather conditions. We also perform designed choreography data collection inside the Mcity test facility focusing on vehicle to vehicle, and vehicle to vulnerable road user interactions which is quite unique among existing open-source datasets. The vehicle platform, data content, tags/labels, and selected analysis results are shown in this paper.