 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIDI-DDSP: Detailed Control of Musical Performance via Hierarchical Modeling
Dec 17, 2021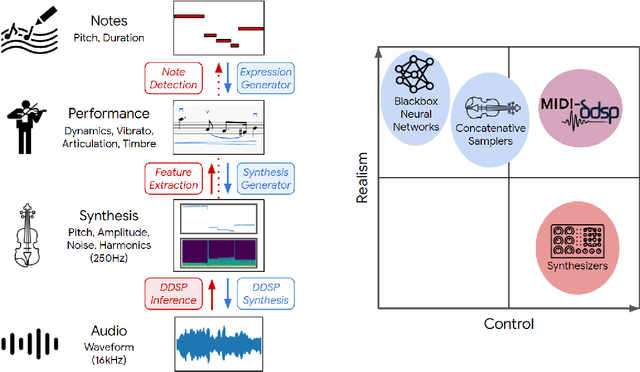
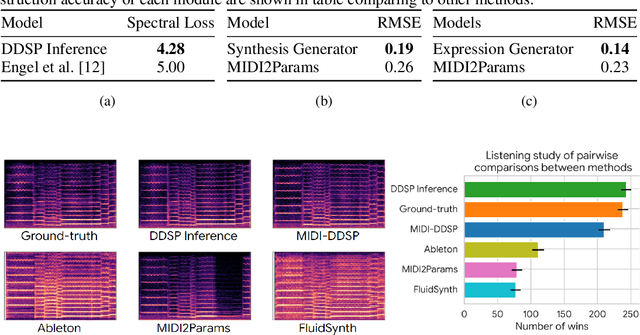
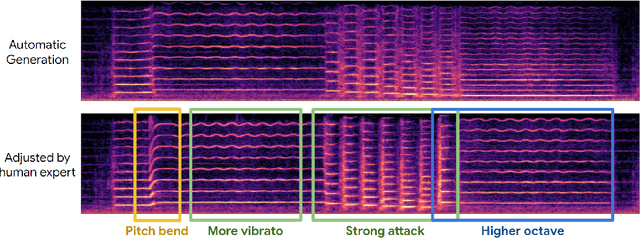
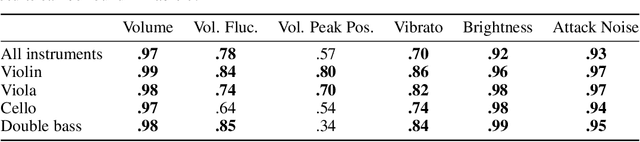
Musical expression requires control of both what notes are played, and how they are performed. Conventional audio synthesizers provide detailed expressive controls, but at the cost of realism. Black-box neural audio synthesis and concatenative samplers can produce realistic audio, but have few mechanisms for control. In this work, we introduce MIDI-DDSP a hierarchical model of musical instruments that enables both realistic neural audio synthesis and detailed user control. Starting from interpretable Differentiable Digital Signal Processing (DDSP) synthesis parameters, we infer musical notes and high-level properties of their expressive performance (such as timbre, vibrato, dynamics, and articulation). This creates a 3-level hierarchy (notes, performance, synthesis) that affords individuals the option to intervene at each level, or utilize trained priors (performance given notes, synthesis given performance) for creative assistance. Through quantitative experiments and listening tests, we demonstrate that this hierarchy can reconstruct high-fidelity audio, accurately predict performance attributes for a note sequence, independently manipulate the attributes of a given performance, and as a complete system, generate realistic audio from a novel note sequence. By utilizing an interpretable hierarchy, with multiple levels of granularity, MIDI-DDSP opens the door to assistive tools to empower individuals across a diverse range of musical experience.
Expressive Communication: A Common Framework for Evaluating Developments in Generative Models and Steering Interfaces
Nov 29, 2021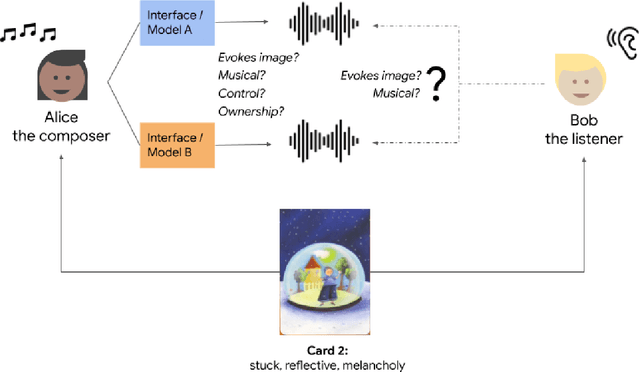
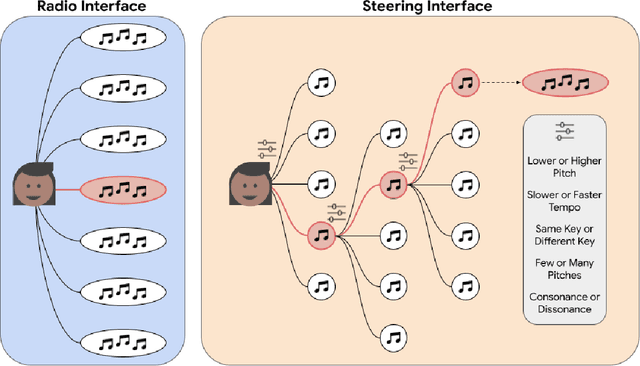

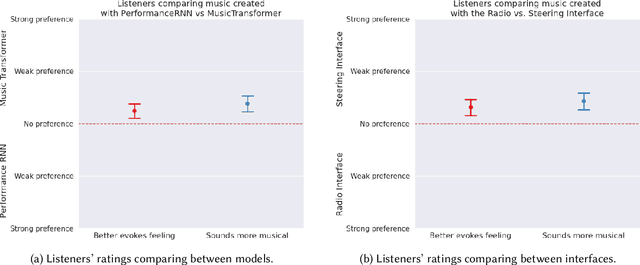
There is an increasing interest from ML and HCI communities in empowering creators with better generative models and more intuitive interfaces with which to control them. In music, ML researchers have focused on training models capable of generating pieces with increasing long-range structure and musical coherence, while HCI researchers have separately focused on designing steering interfaces that support user control and ownership. In this study, we investigate through a common framework how developments in both models and user interfaces are important for empowering co-creation where the goal is to create music that communicates particular imagery or ideas (e.g., as is common for other purposeful tasks in music creation like establishing mood or creating accompanying music for another media). Our study is distinguished in that it measures communication through both composer's self-reported experiences, and how listeners evaluate this communication through the music. In an evaluation study with 26 composers creating 100+ pieces of music and listeners providing 1000+ head-to-head comparisons, we find that more expressive models and more steerable interfaces are important and complementary ways to make a difference in composers communicating through music and supporting their creative empowerment.
MT3: Multi-Task Multitrack Music Transcription
Nov 10, 2021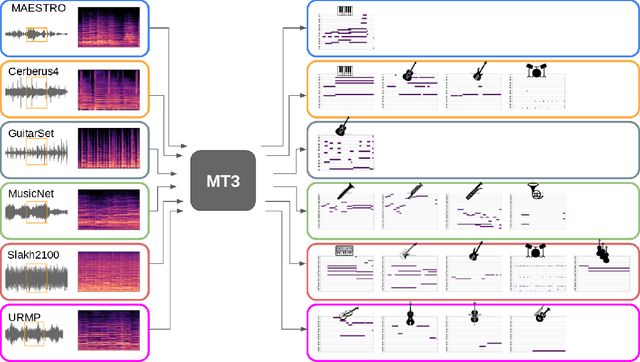

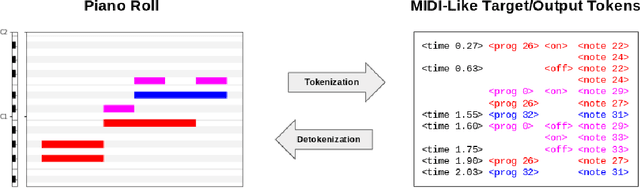
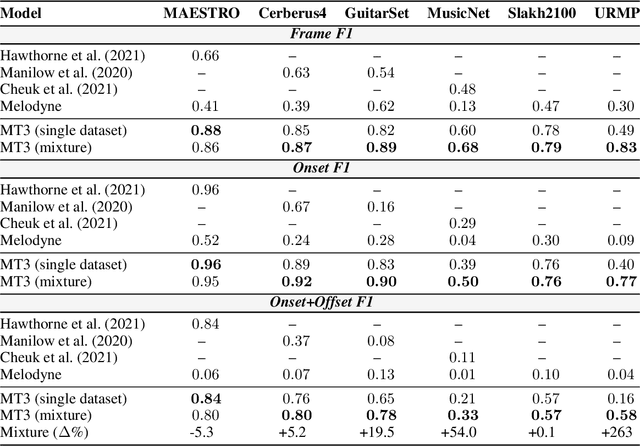
Automatic Music Transcription (AMT), inferring musical notes from raw audio, is a challenging task at the core of music understanding. Unlike Automatic Speech Recognition (ASR), which typically focuses on the words of a single speaker, AMT often requires transcribing multiple instruments simultaneously, all while preserving fine-scale pitch and timing information. Further, many AMT datasets are "low-resource", as even expert musicians find music transcription difficult and time-consuming. Thus, prior work has focused on task-specific architectures, tailored to the individual instruments of each task. In this work, motivated by the promising results of sequence-to-sequence transfer learning for low-resource Natural Language Processing (NLP), we demonstrate that a general-purpose Transformer model can perform multi-task AMT, jointly transcribing arbitrary combinations of musical instruments across several transcription datasets. We show this unified training framework achieves high-quality transcription results across a range of datasets, dramatically improving performance for low-resource instruments (such as guitar), while preserving strong performance for abundant instruments (such as piano). Finally, by expanding the scope of AMT, we expose the need for more consistent evaluation metrics and better dataset alignment, and provide a strong baseline for this new direction of multi-task AMT.
Sequence-to-Sequence Piano Transcription with Transformers
Jul 19, 2021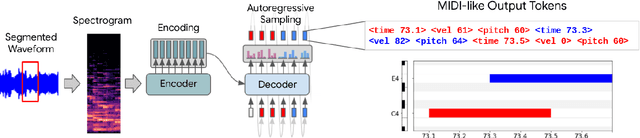
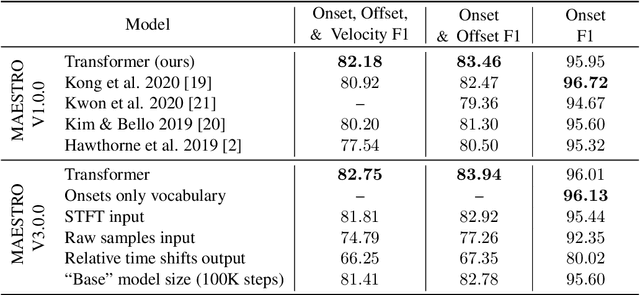

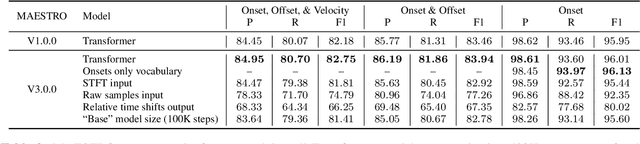
Automatic Music Transcription has seen significant progress in recent years by training custom deep neural networks on large datasets. However, these models have required extensive domain-specific design of network architectures, input/output representations, and complex decoding schemes. In this work, we show that equivalent performance can be achieved using a generic encoder-decoder Transformer with standard decoding methods. We demonstrate that the model can learn to translate spectrogram inputs directly to MIDI-like output events for several transcription tasks. This sequence-to-sequence approach simplifies transcription by jointly modeling audio features and language-like output dependencies, thus removing the need for task-specific architectures. These results point toward possibilities for creating new Music Information Retrieval models by focusing on dataset creation and labeling rather than custom model design.
Symbolic Music Generation with Diffusion Models
Mar 30, 2021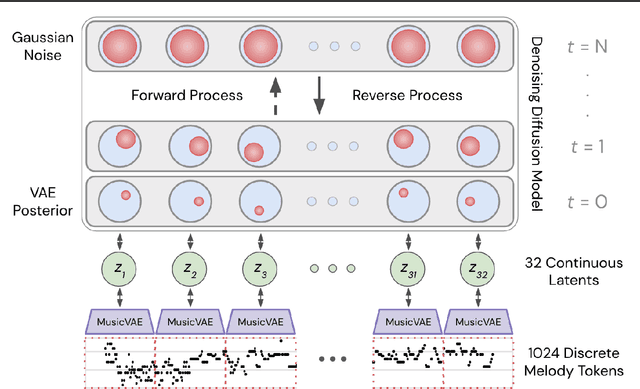
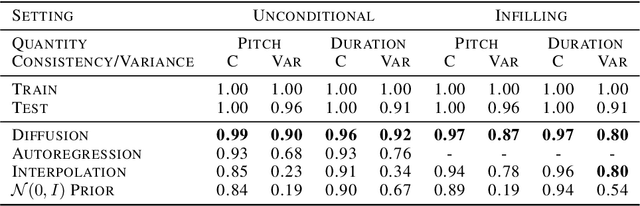
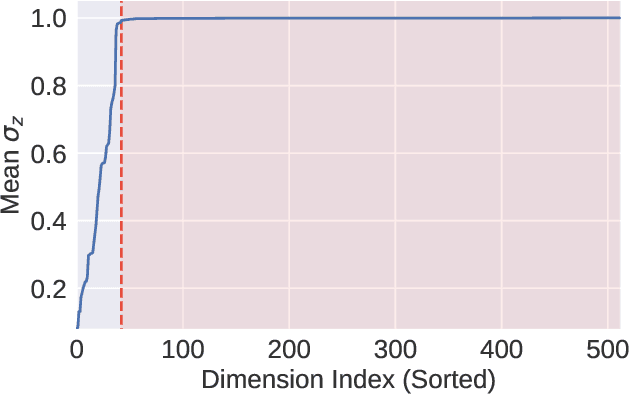
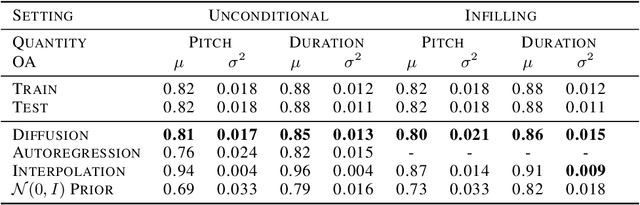
Score-based generative models and diffusion probabilistic models have been successful at generating high-quality samples in continuous domains such as images and audio. However, due to their Langevin-inspired sampling mechanisms, their application to discrete and sequential data has been limited. In this work, we present a technique for training diffusion models on sequential data by parameterizing the discrete domain in the continuous latent space of a pre-trained variational autoencoder. Our method is non-autoregressive and learns to generate sequences of latent embeddings through the reverse process and offers parallel generation with a constant number of iterative refinement steps. We apply this technique to modeling symbolic music and show strong unconditional generation and post-hoc conditional infilling results compared to autoregressive language models operating over the same continuous embeddings.
Variable-rate discrete representation learning
Mar 10, 2021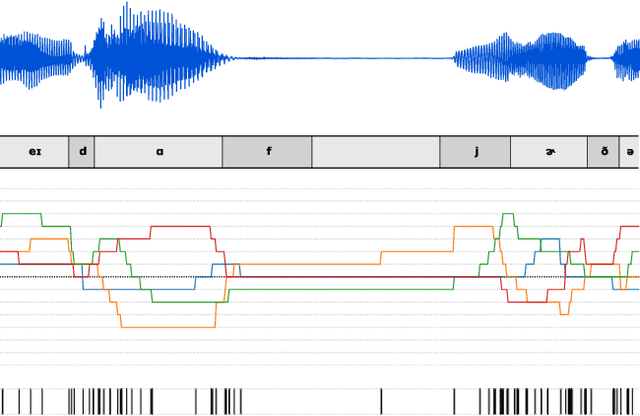

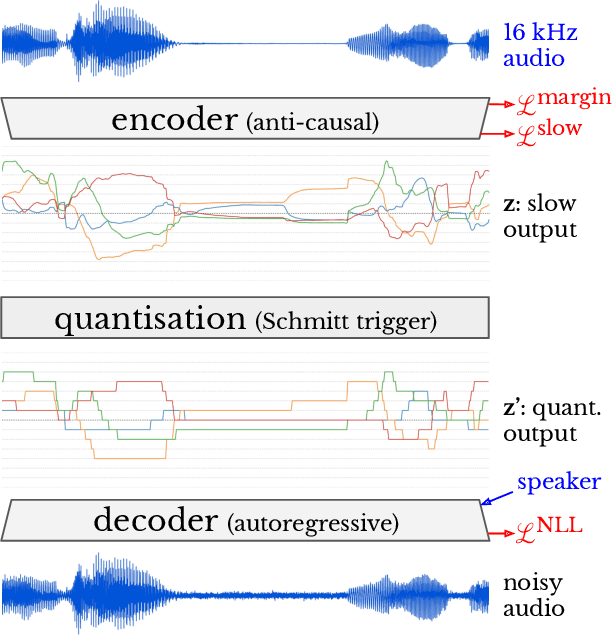

Semantically meaningful information content in perceptual signals is usually unevenly distributed. In speech signals for example, there are often many silences, and the speed of pronunciation can vary considerably. In this work, we propose slow autoencoders (SlowAEs) for unsupervised learning of high-level variable-rate discrete representations of sequences, and apply them to speech. We show that the resulting event-based representations automatically grow or shrink depending on the density of salient information in the input signals, while still allowing for faithful signal reconstruction. We develop run-length Transformers (RLTs) for event-based representation modelling and use them to construct language models in the speech domain, which are able to generate grammatical and semantically coherent utterances and continuations.
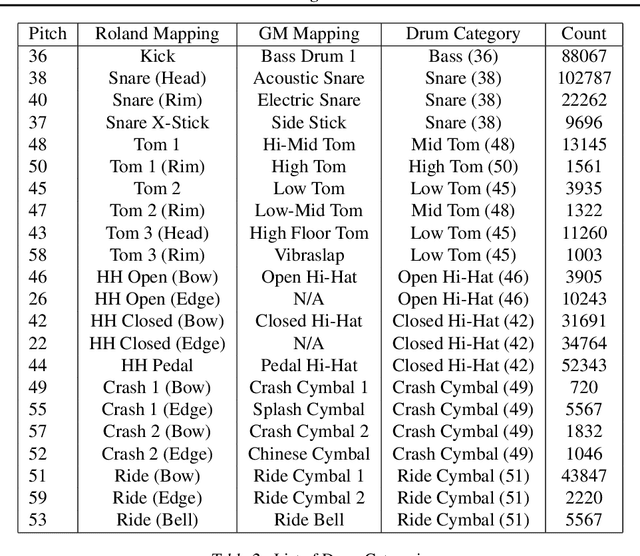
Improving Perceptual Quality of Drum Transcription with the Expanded Groove MIDI Dataset
Apr 08, 2020
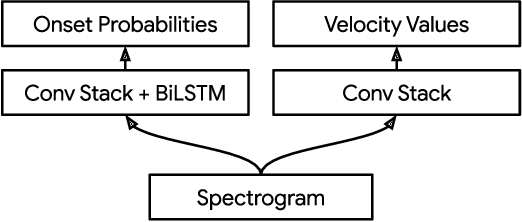
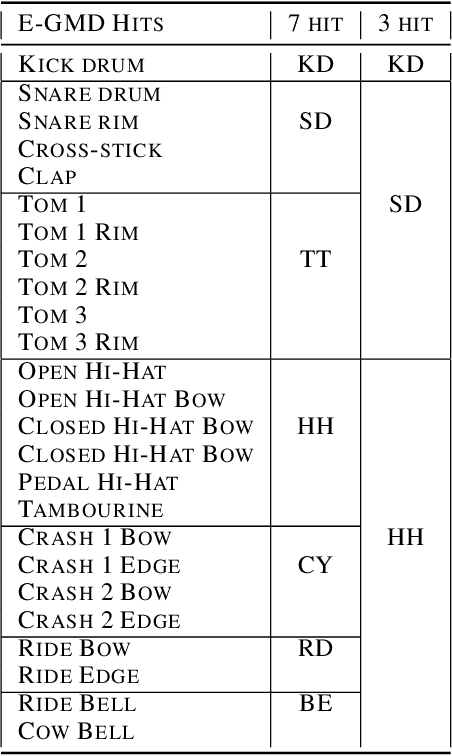
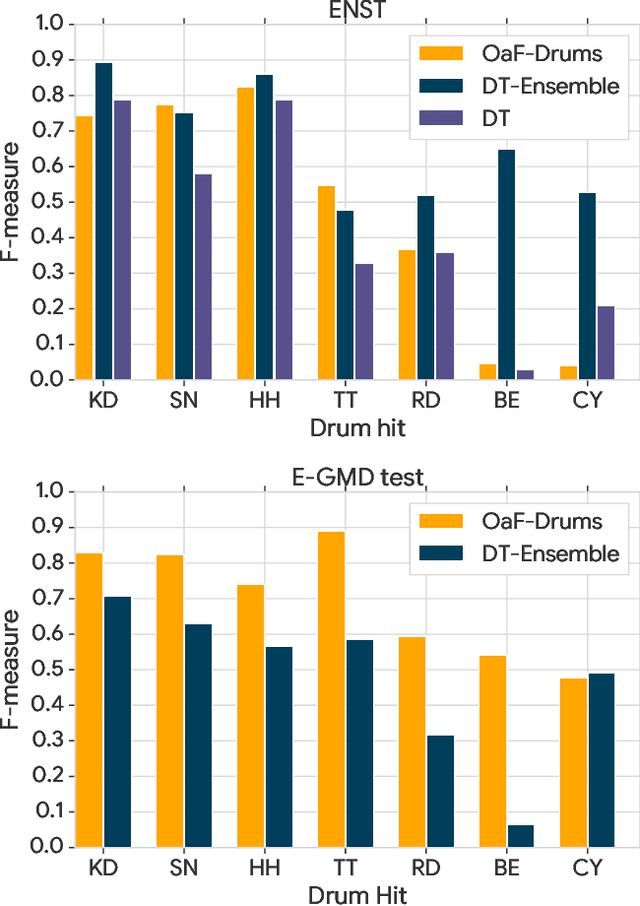
Classifier metrics, such as accuracy and F-measure score, often serve as proxies for performance in downstream tasks. For the case of generative systems that use predicted labels as inputs, accuracy is a good proxy only if it aligns with the perceptual quality of generated outputs. Here, we demonstrate this effect using the example of automatic drum transcription (ADT). We optimize classifiers for downstream generation by predicting expressive dynamics (velocity) and show with listening tests that they produce outputs with improved perceptual quality, despite achieving similar results on classification metrics. To train expressive ADT models, we introduce the Expanded Groove MIDI dataset (E-GMD), a large dataset of human drum performances, with audio recordings annotated in MIDI. E-GMD contains 444 hours of audio from 43 drum kits and is an order of magnitude larger than similar datasets. It is also the first human-performed drum dataset with annotations of velocity. We make this new dataset available under a Creative Commons license along with open source code for training and a pre-trained model for inference.
DDSP: Differentiable Digital Signal Processing
Jan 14, 2020
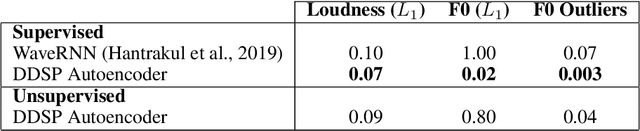
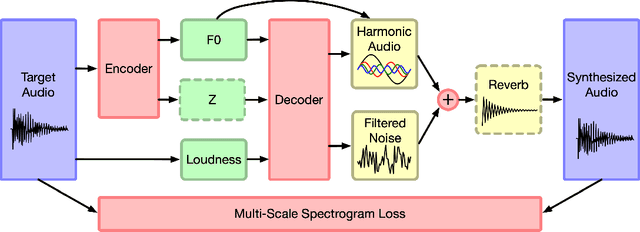
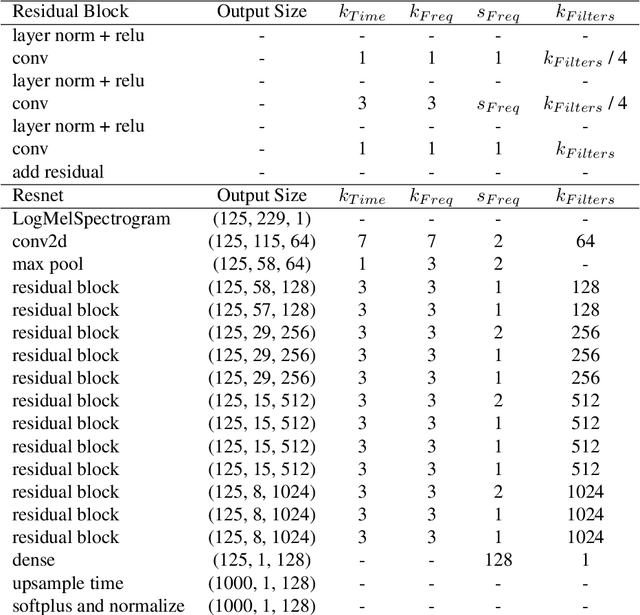
Most generative models of audio directly generate samples in one of two domains: time or frequency. While sufficient to express any signal, these representations are inefficient, as they do not utilize existing knowledge of how sound is generated and perceived. A third approach (vocoders/synthesizers) successfully incorporates strong domain knowledge of signal processing and perception, but has been less actively researched due to limited expressivity and difficulty integrating with modern auto-differentiation-based machine learning methods. In this paper, we introduce the Differentiable Digital Signal Processing (DDSP) library, which enables direct integration of classic signal processing elements with deep learning methods. Focusing on audio synthesis, we achieve high-fidelity generation without the need for large autoregressive models or adversarial losses, demonstrating that DDSP enables utilizing strong inductive biases without losing the expressive power of neural networks. Further, we show that combining interpretable modules permits manipulation of each separate model component, with applications such as independent control of pitch and loudness, realistic extrapolation to pitches not seen during training, blind dereverberation of room acoustics, transfer of extracted room acoustics to new environments, and transformation of timbre between disparate sources. In short, DDSP enables an interpretable and modular approach to generative modeling, without sacrificing the benefits of deep learning. The library is publicly available at https://github.com/magenta/ddsp and we welcome further contributions from the community and domain experts.
Encoding Musical Style with Transformer Autoencoders
Dec 10, 2019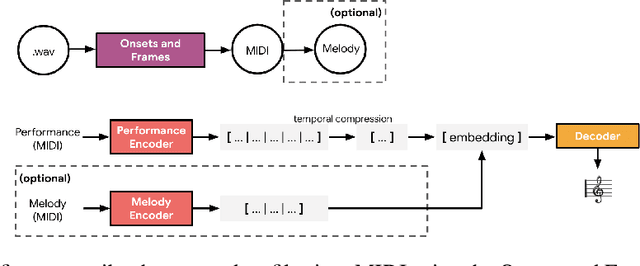


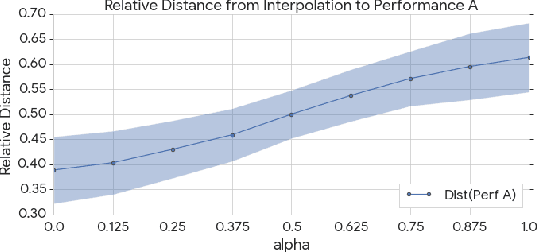
We consider the problem of learning high-level controls over the global structure of sequence generation, particularly in the context of symbolic music generation with complex language models. In this work, we present the Transformer autoencoder, which aggregates encodings of the input data across time to obtain a global representation of style from a given performance. We show it is possible to combine this global embedding with other temporally distributed embeddings, enabling improved control over the separate aspects of performance style and and melody. Empirically, we demonstrate the effectiveness of our method on a variety of music generation tasks on the MAESTRO dataset and a YouTube dataset with 10,000+ hours of piano performances, where we achieve improvements in terms of log-likelihood and mean listening scores as compared to relevant baselines.
Learning to Groove with Inverse Sequence Transformations
May 14, 2019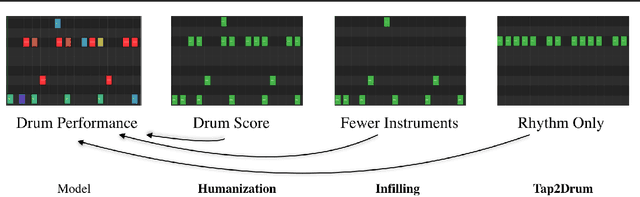
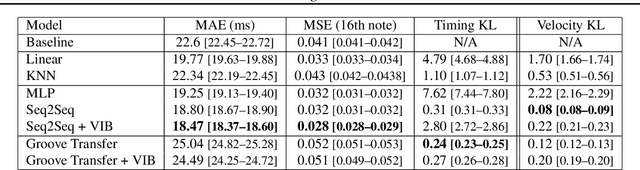
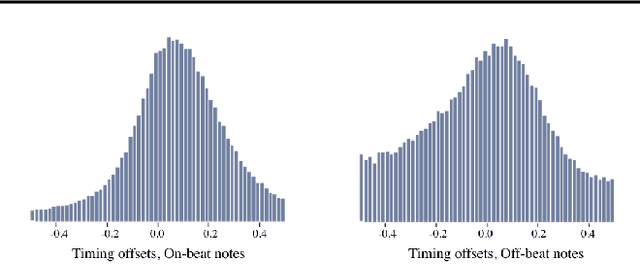
We explore models for translating abstract musical ideas (scores, rhythms) into expressive performances using Seq2Seq and recurrent Variational Information Bottleneck (VIB) models. Though Seq2Seq models usually require painstakingly aligned corpora, we show that it is possible to adapt an approach from the Generative Adversarial Network (GAN) literature (e.g. Pix2Pix (Isola et al., 2017) and Vid2Vid (Wang et al. 2018a)) to sequences, creating large volumes of paired data by performing simple transformations and training generative models to plausibly invert these transformations. Music, and drumming in particular, provides a strong test case for this approach because many common transformations (quantization, removing voices) have clear semantics, and models for learning to invert them have real-world applications. Focusing on the case of drum set players, we create and release a new dataset for this purpose, containing over 13 hours of recordings by professional drummers aligned with fine-grained timing and dynamics information. We also explore some of the creative potential of these models, including demonstrating improvements on state-of-the-art methods for Humanization (instantiating a performance from a musical score).