 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting Networks with Co-training for Continual Learning
Sep 09, 2020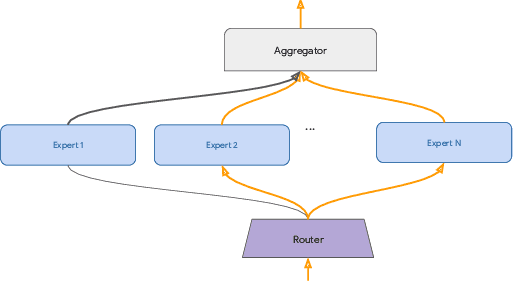

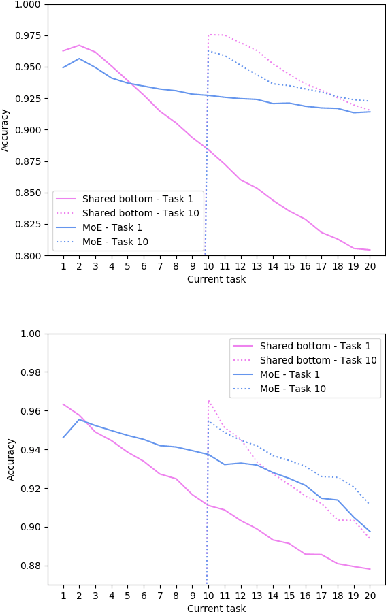
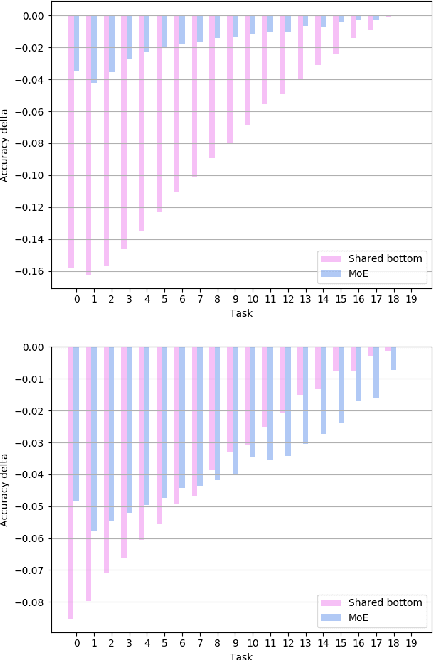
The core challenge with continual learning is catastrophic forgetting, the phenomenon that when neural networks are trained on a sequence of tasks they rapidly forget previously learned tasks. It has been observed that catastrophic forgetting is most severe when tasks are dissimilar to each other. We propose the use of sparse routing networks for continual learning. For each input, these network architectures activate a different path through a network of experts. Routing networks have been shown to learn to route similar tasks to overlapping sets of experts and dissimilar tasks to disjoint sets of experts. In the continual learning context this behaviour is desirable as it minimizes interference between dissimilar tasks while allowing positive transfer between related tasks. In practice, we find it is necessary to develop a new training method for routing networks, which we call co-training which avoids poorly initialized experts when new tasks are presented. When combined with a small episodic memory replay buffer, sparse routing networks with co-training outperform densely connected networks on the MNIST-Permutations and MNIST-Rotations benchmarks.
Analysis of Softmax Approximation for Deep Classifiers under Input-Dependent Label Noise
Mar 15, 2020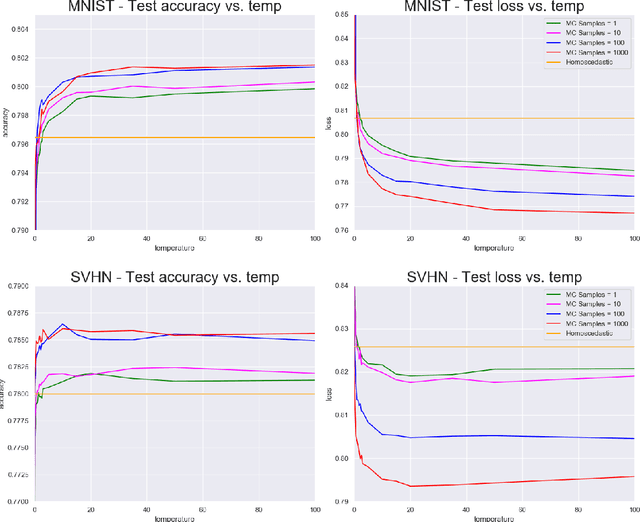

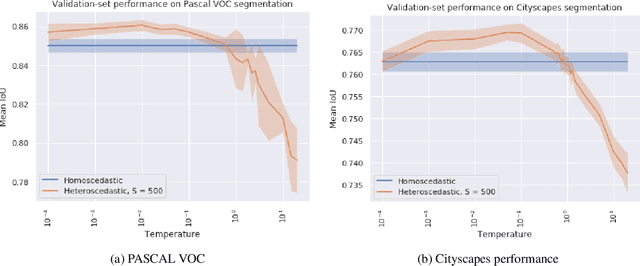
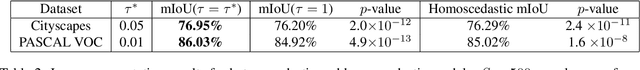
Modelling uncertainty arising from input-dependent label noise is an increasingly important problem. A state-of-the-art approach for classification [Kendall and Gal, 2017] places a normal distribution over the softmax logits, where the mean and variance of this distribution are learned functions of the inputs. This approach achieves impressive empirical performance but lacks theoretical justification. We show that this model is a special case of a well known and theoretically understood model studied in econometrics. Under this view the softmax over the logit distribution is a smooth approximation to an argmax, where the approximation is exact in the zero temperature limit. We further illustrate that the softmax temperature controls a bias-variance trade-off and the optimal point on this trade-off is not always found at 1.0. By tuning the softmax temperature, we achieve improved performance on well known image classification benchmarks with controlled label noise. For image segmentation, where input-dependent label noise naturally arises, we show that tuning the temperature increases the mean IoU on the PASCAL VOC and Cityscapes datasets by more than 1% over the state-of-the-art model and a strong baseline that does not model this noise source.
Ranking architectures using meta-learning
Nov 26, 2019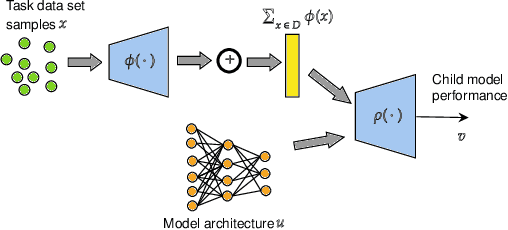
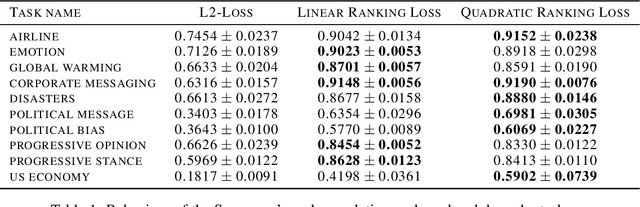
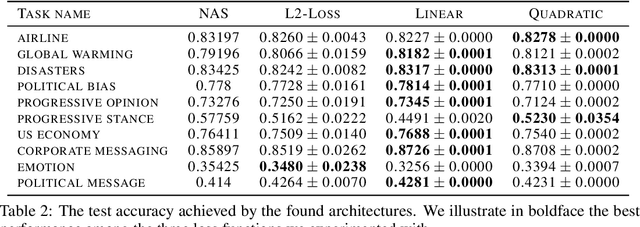
Neural architecture search has recently attracted lots of research efforts as it promises to automate the manual design of neural networks. However, it requires a large amount of computing resources and in order to alleviate this, a performance prediction network has been recently proposed that enables efficient architecture search by forecasting the performance of candidate architectures, instead of relying on actual model training. The performance predictor is task-aware taking as input not only the candidate architecture but also task meta-features and it has been designed to collectively learn from several tasks. In this work, we introduce a pairwise ranking loss for training a network able to rank candidate architectures for a new unseen task conditioning on its task meta-features. We present experimental results, showing that the ranking network is more effective in architecture search than the previously proposed performance predictor.
Gumbel-Matrix Routing for Flexible Multi-task Learning
Oct 10, 2019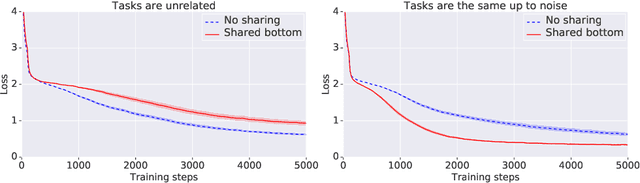

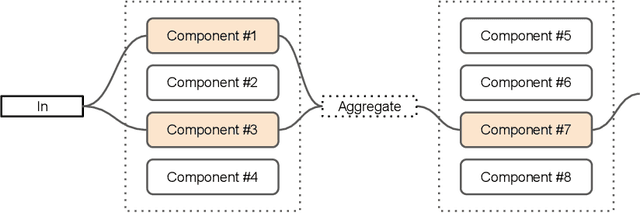
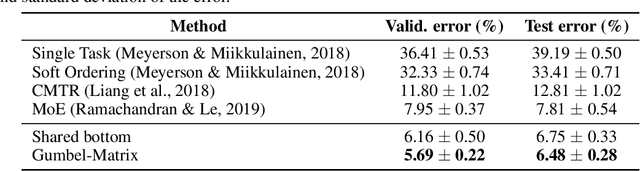
This paper proposes a novel per-task routing method for multi-task applications. Multi-task neural networks can learn to transfer knowledge across different tasks by using parameter sharing. However, sharing parameters between unrelated tasks can hurt performance. To address this issue, we advocate the use of routing networks to learn flexible parameter sharing, where each group of parameters is shared with a different subset of tasks in order to better leverage tasks relatedness. At the same time, it is known that routing networks are notoriously hard to train. We propose the Gumbel-Matrix routing: a novel multi-task routing method, designed to learn fine-grained patterns of parameter sharing. The routing is learned jointly with the model parameters by standard back-propagation thanks to the Gumbel-Softmax trick. When applied to the Omniglot benchmark, the proposed method reduces the state-of-the-art error rate by 17%.
Cap2Det: Learning to Amplify Weak Caption Supervision for Object Detection
Aug 16, 2019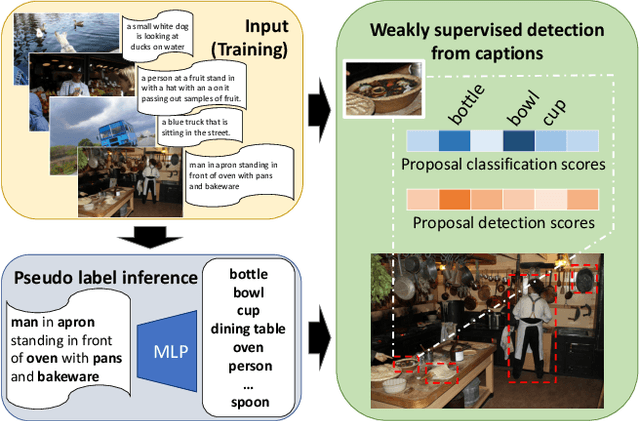
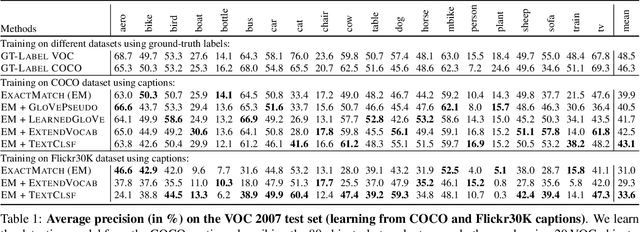
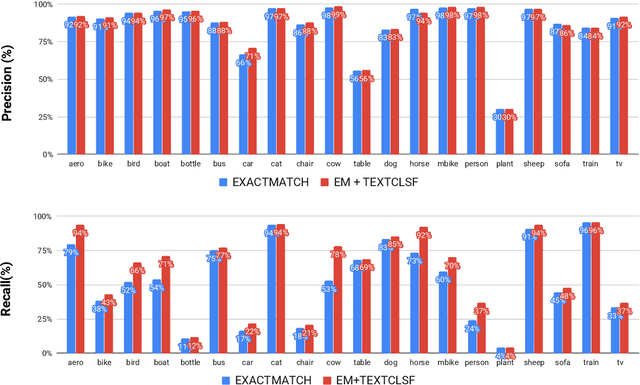
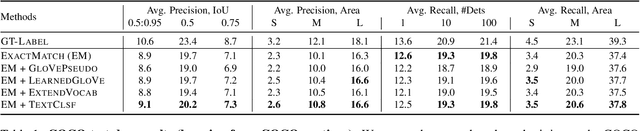
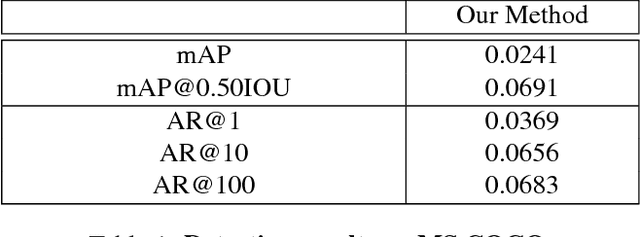
Learning to localize and name object instances is a fundamental problem in vision, but state-of-the-art approaches rely on expensive bounding box supervision. While weakly supervised detection (WSOD) methods relax the need for boxes to that of image-level annotations, even cheaper supervision is naturally available in the form of unstructured textual descriptions that users may freely provide when uploading image content. However, straightforward approaches to using such data for WSOD wastefully discard captions that do not exactly match object names. Instead, we show how to squeeze the most information out of these captions by training a text-only classifier that generalizes beyond dataset boundaries. Our discovery provides an opportunity for learning detection models from noisy but more abundant and freely-available caption data. We also validate our model on three classic object detection benchmarks and achieve state-of-the-art WSOD performance. Our code is available at https://github.com/yekeren/Cap2Det.
Fast Task-Aware Architecture Inference
Feb 15, 2019
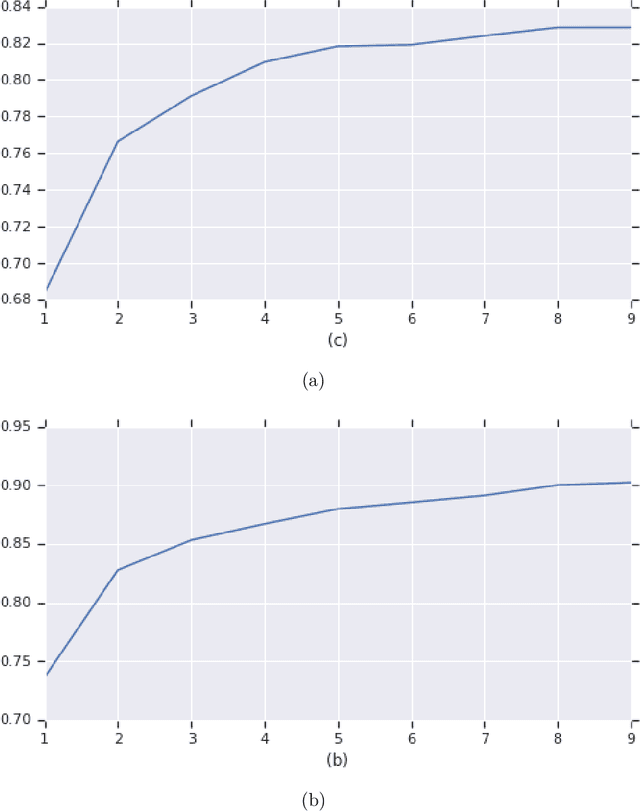

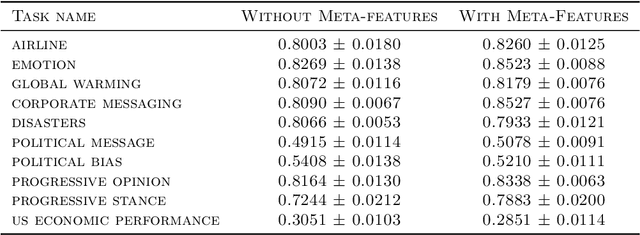
Neural architecture search has been shown to hold great promise towards the automation of deep learning. However in spite of its potential, neural architecture search remains quite costly. To this point, we propose a novel gradient-based framework for efficient architecture search by sharing information across several tasks. We start by training many model architectures on several related (training) tasks. When a new unseen task is presented, the framework performs architecture inference in order to quickly identify a good candidate architecture, before any model is trained on the new task. At the core of our framework lies a deep value network that can predict the performance of input architectures on a task by utilizing task meta-features and the previous model training experiments performed on related tasks. We adopt a continuous parametrization of the model architecture which allows for efficient gradient-based optimization. Given a new task, an effective architecture is quickly identified by maximizing the estimated performance with respect to the model architecture parameters with simple gradient ascent. It is key to point out that our goal is to achieve reasonable performance at the lowest cost. We provide experimental results showing the effectiveness of the framework despite its high computational efficiency.
Learning to discover and localize visual objects with open vocabulary
Nov 25, 2018
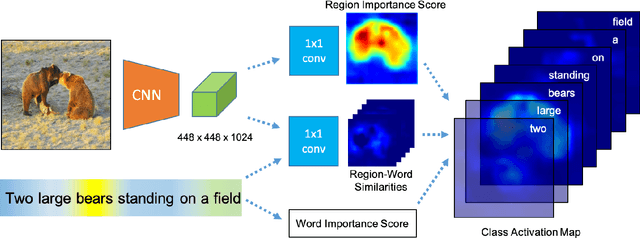

To alleviate the cost of obtaining accurate bounding boxes for training today's state-of-the-art object detection models, recent weakly supervised detection work has proposed techniques to learn from image-level labels. However, requiring discrete image-level labels is both restrictive and suboptimal. Real-world "supervision" usually consists of more unstructured text, such as captions. In this work we learn association maps between images and captions. We then use a novel objectness criterion to rank the resulting candidate boxes, such that high-ranking boxes have strong gradients along all edges. Thus, we can detect objects beyond a fixed object category vocabulary, if those objects are frequent and distinctive enough. We show that our objectness criterion improves the proposed bounding boxes in relation to prior weakly supervised detection methods. Further, we show encouraging results on object detection from image-level captions only.
WebVision Challenge: Visual Learning and Understanding With Web Data
May 16, 2017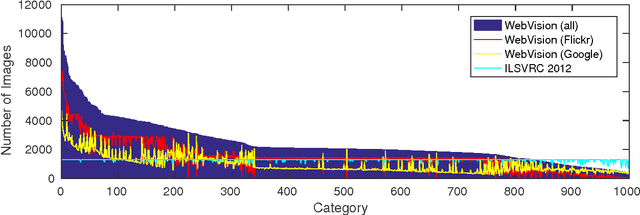

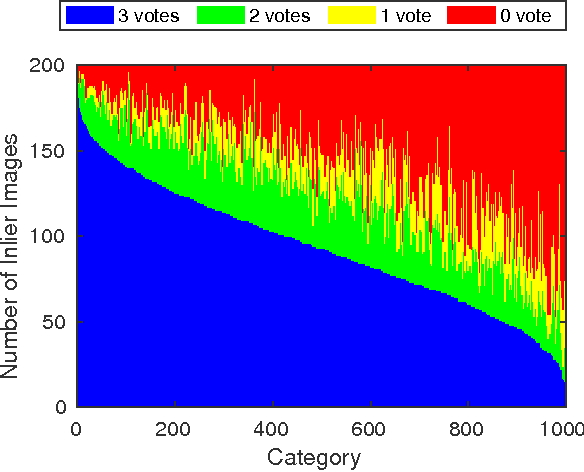
We present the 2017 WebVision Challenge, a public image recognition challenge designed for deep learning based on web images without instance-level human annotation. Following the spirit of previous vision challenges, such as ILSVRC, Places2 and PASCAL VOC, which have played critical roles in the development of computer vision by contributing to the community with large scale annotated data for model designing and standardized benchmarking, we contribute with this challenge a large scale web images dataset, and a public competition with a workshop co-located with CVPR 2017. The WebVision dataset contains more than $2.4$ million web images crawled from the Internet by using queries generated from the $1,000$ semantic concepts of the benchmark ILSVRC 2012 dataset. Meta information is also included. A validation set and test set containing human annotated images are also provided to facilitate algorithmic development. The 2017 WebVision challenge consists of two tracks, the image classification task on WebVision test set, and the transfer learning task on PASCAL VOC 2012 dataset. In this paper, we describe the details of data collection and annotation, highlight the characteristics of the dataset, and introduce the evaluation metrics.