 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Learning Structured Distributions from Untrusted Batches
Nov 05, 2019We study the problem, introduced by Qiao and Valiant, of learning from untrusted batches. Here, we assume $m$ users, all of whom have samples from some underlying distribution $p$ over $1, \ldots, n$. Each user sends a batch of $k$ i.i.d. samples from this distribution; however an $\epsilon$-fraction of users are untrustworthy and can send adversarially chosen responses. The goal is then to learn $p$ in total variation distance. When $k = 1$ this is the standard robust univariate density estimation setting and it is well-understood that $\Omega (\epsilon)$ error is unavoidable. Suprisingly, Qiao and Valiant gave an estimator which improves upon this rate when $k$ is large. Unfortunately, their algorithms run in time exponential in either $n$ or $k$. We first give a sequence of polynomial time algorithms whose estimation error approaches the information-theoretically optimal bound for this problem. Our approach is based on recent algorithms derived from the sum-of-squares hierarchy, in the context of high-dimensional robust estimation. We show that algorithms for learning from untrusted batches can also be cast in this framework, but by working with a more complicated set of test functions. It turns out this abstraction is quite powerful and can be generalized to incorporate additional problem specific constraints. Our second and main result is to show that this technology can be leveraged to build in prior knowledge about the shape of the distribution. Crucially, this allows us to reduce the sample complexity of learning from untrusted batches to polylogarithmic in $n$ for most natural classes of distributions, which is important in many applications. To do so, we demonstrate that these sum-of-squares algorithms for robust mean estimation can be made to handle complex combinatorial constraints (e.g. those arising from VC theory), which may be of independent technical interest.
Quantum Entropy Scoring for Fast Robust Mean Estimation and Improved Outlier Detection
Jun 26, 2019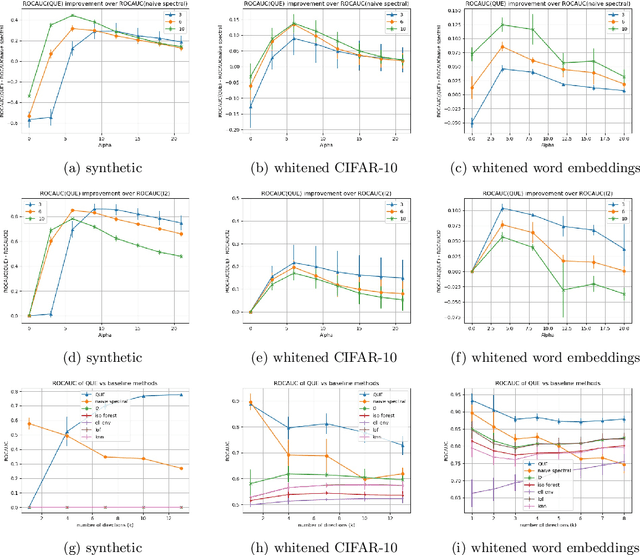

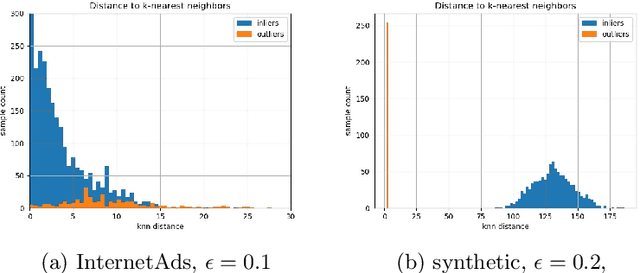
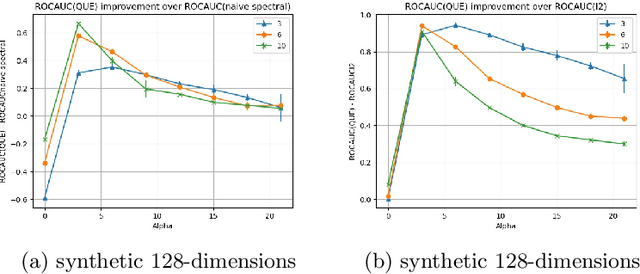
We study two problems in high-dimensional robust statistics: \emph{robust mean estimation} and \emph{outlier detection}. In robust mean estimation the goal is to estimate the mean $\mu$ of a distribution on $\mathbb{R}^d$ given $n$ independent samples, an $\varepsilon$-fraction of which have been corrupted by a malicious adversary. In outlier detection the goal is to assign an \emph{outlier score} to each element of a data set such that elements more likely to be outliers are assigned higher scores. Our algorithms for both problems are based on a new outlier scoring method we call QUE-scoring based on \emph{quantum entropy regularization}. For robust mean estimation, this yields the first algorithm with optimal error rates and nearly-linear running time $\widetilde{O}(nd)$ in all parameters, improving on the previous fastest running time $\widetilde{O}(\min(nd/\varepsilon^6, nd^2))$. For outlier detection, we evaluate the performance of QUE-scoring via extensive experiments on synthetic and real data, and demonstrate that it often performs better than previously proposed algorithms. Code for these experiments is available at https://github.com/twistedcubic/que-outlier-detection .
Provably Robust Deep Learning via Adversarially Trained Smoothed Classifiers
Jun 12, 2019
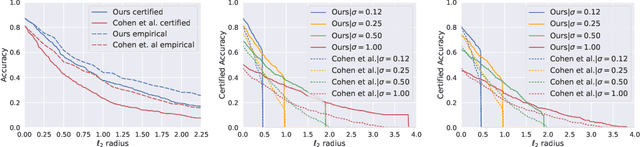

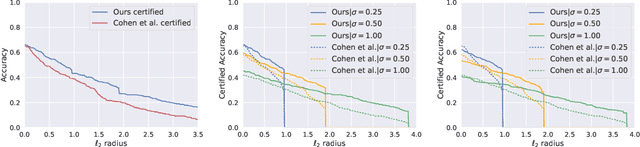
Recent works have shown the effectiveness of randomized smoothing as a scalable technique for building neural network-based classifiers that are provably robust to $\ell_2$-norm adversarial perturbations. In this paper, we employ adversarial training to improve the performance of randomized smoothing. We design an adapted attack for smoothed classifiers, and we show how this attack can be used in an adversarial training setting to boost the provable robustness of smoothed classifiers. We demonstrate through extensive experimentation that our method consistently outperforms all existing provably $\ell_2$-robust classifiers by a significant margin on ImageNet and CIFAR-10, establishing the state-of-the-art for provable $\ell_2$-defenses. Our code and trained models are available at http://github.com/Hadisalman/smoothing-adversarial .
Sample Efficient Toeplitz Covariance Estimation
Jun 06, 2019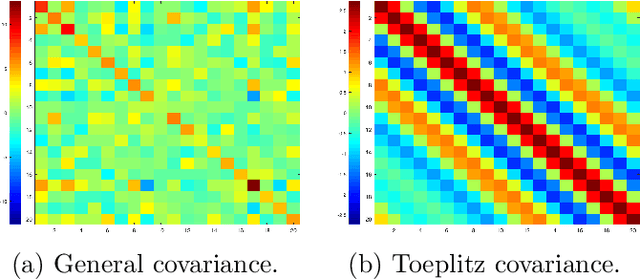
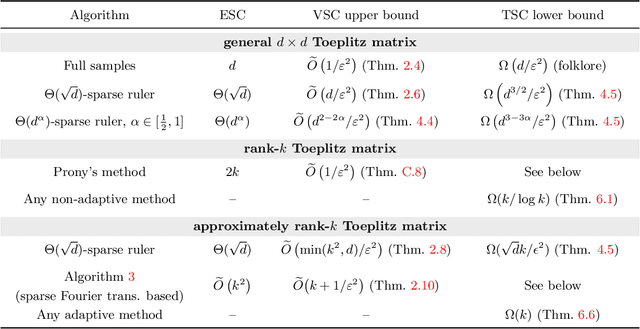
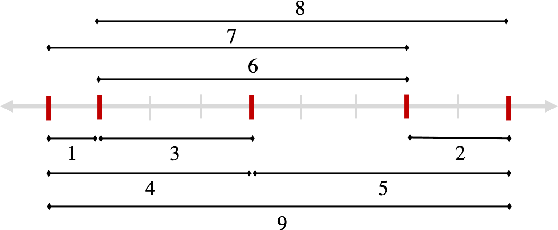
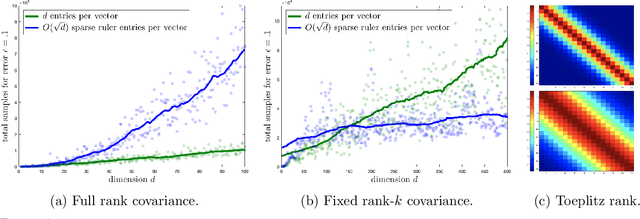
We study the sample complexity of estimating the covariance matrix $T$ of a distribution $\mathcal{D}$ over $d$-dimensional vectors, under the assumption that $T$ is Toeplitz. This assumption arises in many signal processing problems, where the covariance between any two measurements only depends on the time or distance between those measurements. We are interested in estimation strategies that may choose to view only a subset of entries in each vector sample $x \sim \mathcal{D}$, which often equates to reducing hardware and communication requirements in applications ranging from wireless signal processing to advanced imaging. Our goal is to minimize both 1) the number of vector samples drawn from $\mathcal{D}$ and 2) the number of entries accessed in each sample. We provide some of the first non-asymptotic bounds on these sample complexity measures that exploit $T$'s Toeplitz structure, and by doing so, significantly improve on results for generic covariance matrices. Our bounds follow from a novel analysis of classical and widely used estimation algorithms (along with some new variants), including methods based on selecting entries from each vector sample according to a so-called sparse ruler. In many cases, we pair our upper bounds with matching or nearly matching lower bounds. In addition to results that hold for any Toeplitz $T$, we further study the important setting when $T$ is close to low-rank, which is often the case in practice. We show that methods based on sparse rulers perform even better in this setting, with sample complexity scaling sublinearly in $d$. Motivated by this finding, we develop a new covariance estimation strategy that further improves on all existing methods in the low-rank case: when $T$ is rank-$k$ or nearly rank-$k$, it achieves sample complexity depending polynomially on $k$ and only logarithmically on $d$.
Spectral Signatures in Backdoor Attacks
Nov 01, 2018


A recent line of work has uncovered a new form of data poisoning: so-called \emph{backdoor} attacks. These attacks are particularly dangerous because they do not affect a network's behavior on typical, benign data. Rather, the network only deviates from its expected output when triggered by a perturbation planted by an adversary. In this paper, we identify a new property of all known backdoor attacks, which we call \emph{spectral signatures}. This property allows us to utilize tools from robust statistics to thwart the attacks. We demonstrate the efficacy of these signatures in detecting and removing poisoned examples on real image sets and state of the art neural network architectures. We believe that understanding spectral signatures is a crucial first step towards designing ML systems secure against such backdoor attacks
Privately Learning High-Dimensional Distributions
Sep 18, 2018We present novel, computationally efficient, and differentially private algorithms for two fundamental high-dimensional learning problems: learning a multivariate Gaussian in $R^d$ and learning a product distribution in $\{0,1\}^{d}$ in total variation distance. The sample complexity of our algorithms nearly matches the sample complexity of the optimal non-private learners for these tasks in a wide range of parameters. Thus, our results show that private comes essentially for free for these problems, providing a counterpoint to the many negative results showing that privacy is often costly in high dimensions. Our algorithms introduce a novel technical approach to reducing the sensitivity of the estimation procedure that we call recursive private preconditioning, which may find additional applications.
Twin-GAN -- Unpaired Cross-Domain Image Translation with Weight-Sharing GANs
Aug 26, 2018


We present a framework for translating unlabeled images from one domain into analog images in another domain. We employ a progressively growing skip-connected encoder-generator structure and train it with a GAN loss for realistic output, a cycle consistency loss for maintaining same-domain translation identity, and a semantic consistency loss that encourages the network to keep the input semantic features in the output. We apply our framework on the task of translating face images, and show that it is capable of learning semantic mappings for face images with no supervised one-to-one image mapping.
On the Limitations of First-Order Approximation in GAN Dynamics
Jun 03, 2018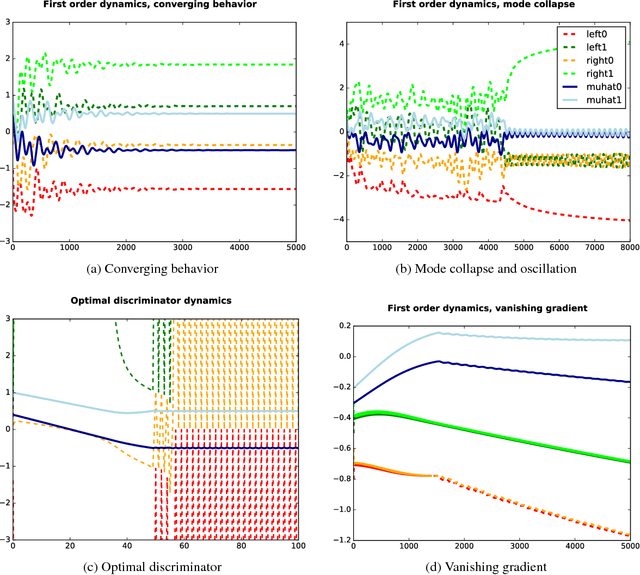
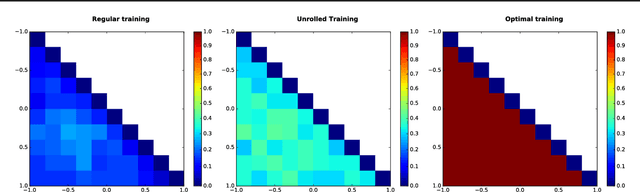
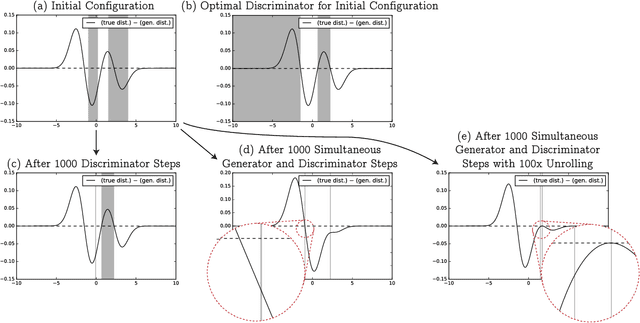
While Generative Adversarial Networks (GANs) have demonstrated promising performance on multiple vision tasks, their learning dynamics are not yet well understood, both in theory and in practice. To address this issue, we study GAN dynamics in a simple yet rich parametric model that exhibits several of the common problematic convergence behaviors such as vanishing gradients, mode collapse, and diverging or oscillatory behavior. In spite of the non-convex nature of our model, we are able to perform a rigorous theoretical analysis of its convergence behavior. Our analysis reveals an interesting dichotomy: a GAN with an optimal discriminator provably converges, while first order approximations of the discriminator steps lead to unstable GAN dynamics and mode collapse. Our result suggests that using first order discriminator steps (the de-facto standard in most existing GAN setups) might be one of the factors that makes GAN training challenging in practice.
Byzantine Stochastic Gradient Descent
Mar 23, 2018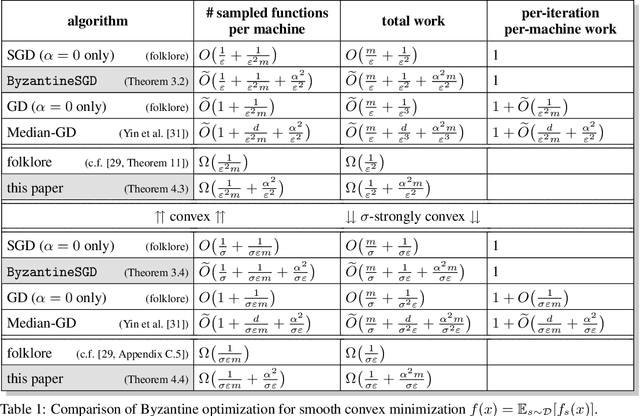
This paper studies the problem of distributed stochastic optimization in an adversarial setting where, out of the $m$ machines which allegedly compute stochastic gradients every iteration, an $\alpha$-fraction are Byzantine, and can behave arbitrarily and adversarially. Our main result is a variant of stochastic gradient descent (SGD) which finds $\varepsilon$-approximate minimizers of convex functions in $T = \tilde{O}\big( \frac{1}{\varepsilon^2 m} + \frac{\alpha^2}{\varepsilon^2} \big)$ iterations. In contrast, traditional mini-batch SGD needs $T = O\big( \frac{1}{\varepsilon^2 m} \big)$ iterations, but cannot tolerate Byzantine failures. Further, we provide a lower bound showing that, up to logarithmic factors, our algorithm is information-theoretically optimal both in terms of sampling complexity and time complexity.
Being Robust (in High Dimensions) Can Be Practical
Mar 13, 2018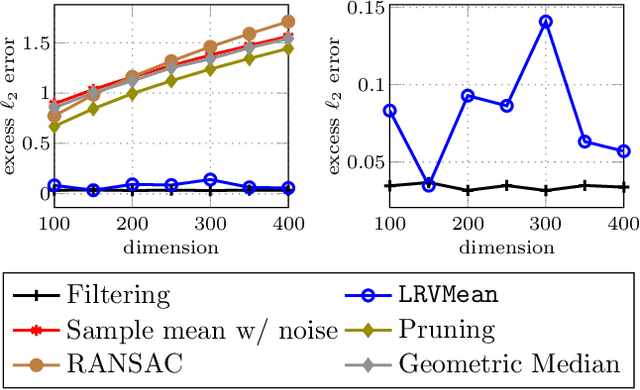
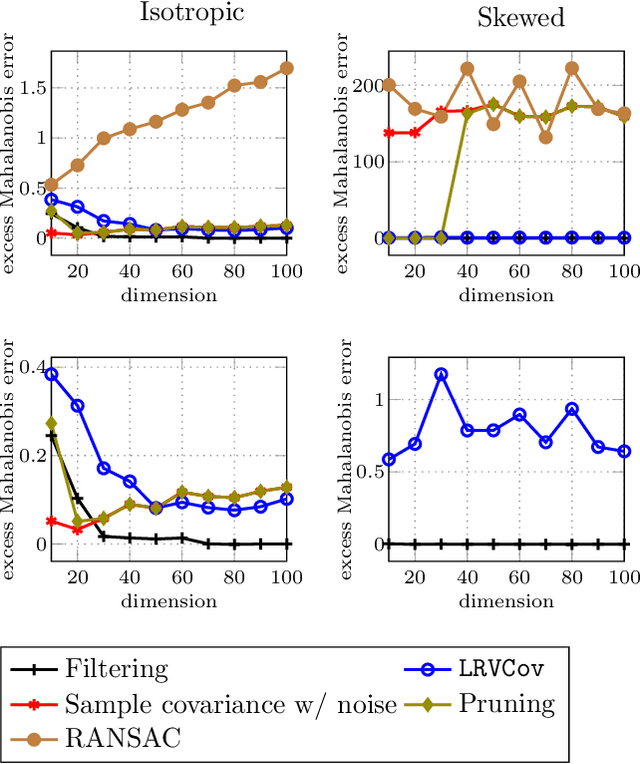
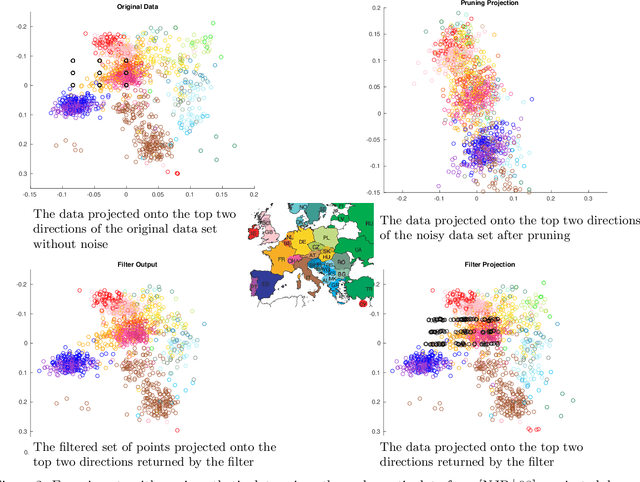
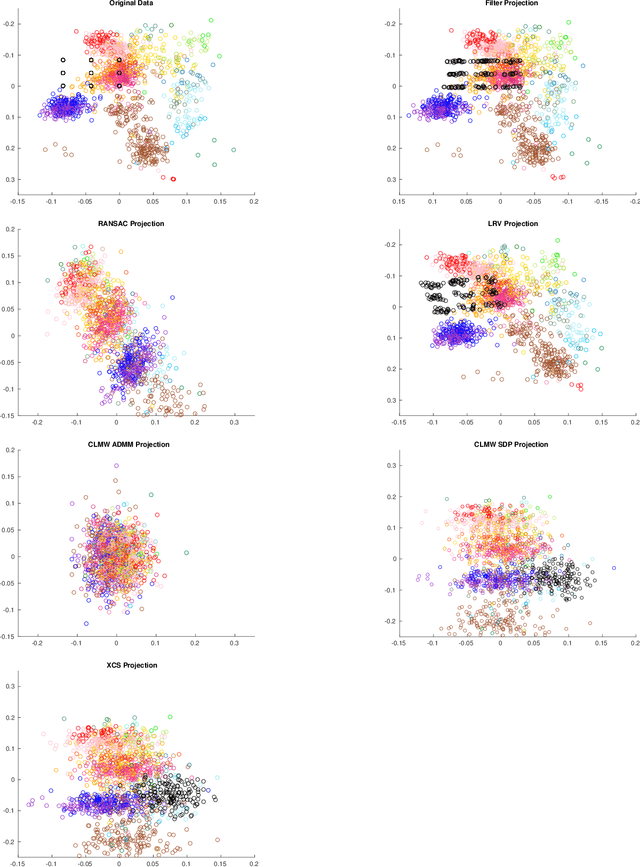
Robust estimation is much more challenging in high dimensions than it is in one dimension: Most techniques either lead to intractable optimization problems or estimators that can tolerate only a tiny fraction of errors. Recent work in theoretical computer science has shown that, in appropriate distributional models, it is possible to robustly estimate the mean and covariance with polynomial time algorithms that can tolerate a constant fraction of corruptions, independent of the dimension. However, the sample and time complexity of these algorithms is prohibitively large for high-dimensional applications. In this work, we address both of these issues by establishing sample complexity bounds that are optimal, up to logarithmic factors, as well as giving various refinements that allow the algorithms to tolerate a much larger fraction of corruptions. Finally, we show on both synthetic and real data that our algorithms have state-of-the-art performance and suddenly make high-dimensional robust estimation a realistic possibility.