 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreoperative-to-intraoperative Liver Registration for Laparoscopic Surgery via Latent-Grounded Correspondence Constraints
Mar 02, 2026In laparoscopic liver surgery, augmented reality technology enhances intraoperative anatomical guidance by overlaying 3D liver models from preoperative CT/MRI onto laparoscopic 2D views. However, existing registration methods lack explicit modeling of reliable 2D-3D geometric correspondences supported by latent evidence, leading to limited interpretability and potentially unstable alignment in clinical scenarios. In this work, we introduce Land-Reg, a correspondence-driven deformable registration framework that explicitly learns latent-grounded 2D-3D landmark correspondences as an interpretable intermediate representation to bridge cross-modal alignment. For rigid registration, Land-Reg embraces a Cross-modal Latent Alignment module to map multi-modal features into a unified latent space. Further, an Uncertainty-enhanced Overlap Landmark Detector with similarity matching is proposed to robustly estimate explicit 2D-3D landmark correspondences. For non-rigid registration, we design a novel shape-constrained supervision strategy that anchors shape deformation to matched landmarks through reprojection consistency and incorporates local-isometric regularization to alleviate inherent 2D-3D depth ambiguity, while a rendered-mask alignment enforces global shape consistency. Experimental results on the P2ILF dataset demonstrate the superiority of our method on both rigid pose estimation and non-rigid deformation. Our code will be available at https://github.com/cuiruize/Land-Reg.
CNN in CT Image Segmentation: Beyound Loss Function for Expoliting Ground Truth Images
Apr 08, 2020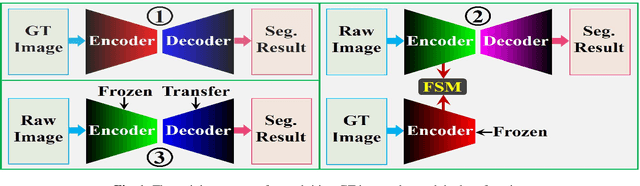
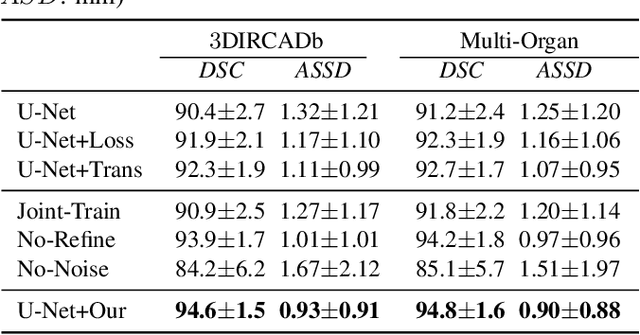
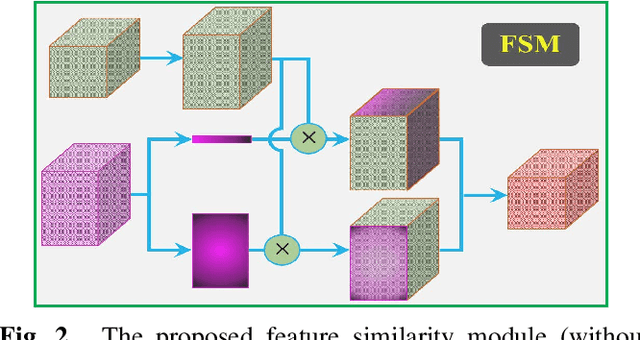
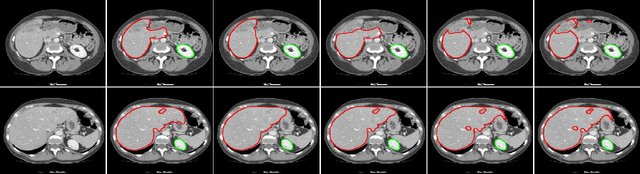
Exploiting more information from ground truth (GT) images now is a new research direction for further improving CNN's performance in CT image segmentation. Previous methods focus on devising the loss function for fulfilling such a purpose. However, it is rather difficult to devise a general and optimization-friendly loss function. We here present a novel and practical method that exploits GT images beyond the loss function. Our insight is that feature maps of two CNNs trained respectively on GT and CT images should be similar on some metric space, because they both are used to describe the same objects for the same purpose. We hence exploit GT images by enforcing such two CNNs' feature maps to be consistent. We assess the proposed method on two data sets, and compare its performance to several competitive methods. Extensive experimental results show that the proposed method is effective, outperforming all the compared methods.