 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Answer Type and Relation Prediction Task (SMART 2021)
Jan 10, 2022
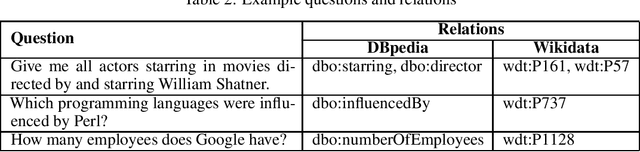
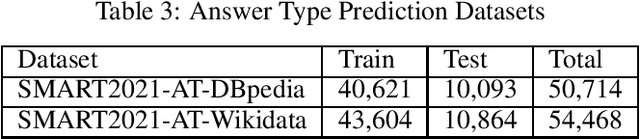
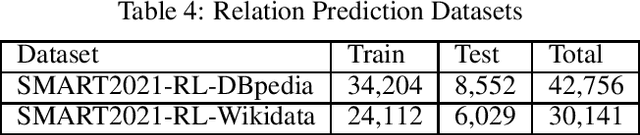
Each year the International Semantic Web Conference organizes a set of Semantic Web Challenges to establish competitions that will advance state-of-the-art solutions in some problem domains. The Semantic Answer Type and Relation Prediction Task (SMART) task is one of the ISWC 2021 Semantic Web challenges. This is the second year of the challenge after a successful SMART 2020 at ISWC 2020. This year's version focuses on two sub-tasks that are very important to Knowledge Base Question Answering (KBQA): Answer Type Prediction and Relation Prediction. Question type and answer type prediction can play a key role in knowledge base question answering systems providing insights about the expected answer that are helpful to generate correct queries or rank the answer candidates. More concretely, given a question in natural language, the first task is, to predict the answer type using a target ontology (e.g., DBpedia or Wikidata. Similarly, the second task is to identify relations in the natural language query and link them to the relations in a target ontology. This paper discusses the task descriptions, benchmark datasets, and evaluation metrics. For more information, please visit https://smart-task.github.io/2021/.
Survey on English Entity Linking on Wikidata
Dec 03, 2021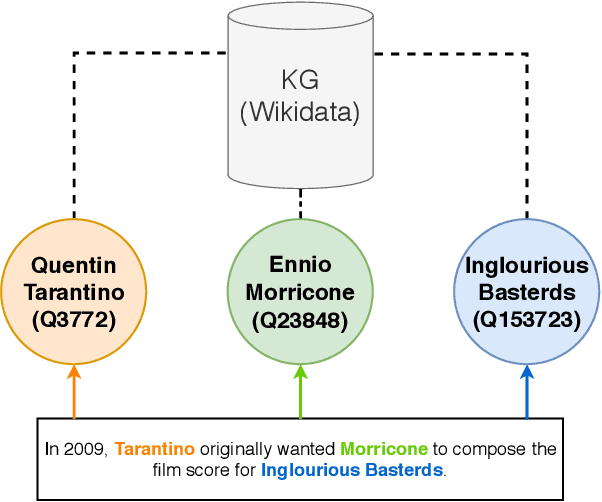

Wikidata is a frequently updated, community-driven, and multilingual knowledge graph. Hence, Wikidata is an attractive basis for Entity Linking, which is evident by the recent increase in published papers. This survey focuses on four subjects: (1) Which Wikidata Entity Linking datasets exist, how widely used are they and how are they constructed? (2) Do the characteristics of Wikidata matter for the design of Entity Linking datasets and if so, how? (3) How do current Entity Linking approaches exploit the specific characteristics of Wikidata? (4) Which Wikidata characteristics are unexploited by existing Entity Linking approaches? This survey reveals that current Wikidata-specific Entity Linking datasets do not differ in their annotation scheme from schemes for other knowledge graphs like DBpedia. Thus, the potential for multilingual and time-dependent datasets, naturally suited for Wikidata, is not lifted. Furthermore, we show that most Entity Linking approaches use Wikidata in the same way as any other knowledge graph missing the chance to leverage Wikidata-specific characteristics to increase quality. Almost all approaches employ specific properties like labels and sometimes descriptions but ignore characteristics such as the hyper-relational structure. Hence, there is still room for improvement, for example, by including hyper-relational graph embeddings or type information. Many approaches also include information from Wikipedia, which is easily combinable with Wikidata and provides valuable textual information, which Wikidata lacks.
Improving Inductive Link Prediction Using Hyper-Relational Facts
Jul 10, 2021

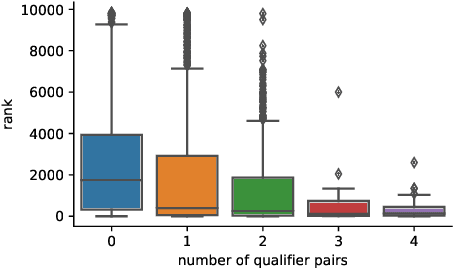
For many years, link prediction on knowledge graphs (KGs) has been a purely transductive task, not allowing for reasoning on unseen entities. Recently, increasing efforts are put into exploring semi- and fully inductive scenarios, enabling inference over unseen and emerging entities. Still, all these approaches only consider triple-based \glspl{kg}, whereas their richer counterparts, hyper-relational KGs (e.g., Wikidata), have not yet been properly studied. In this work, we classify different inductive settings and study the benefits of employing hyper-relational KGs on a wide range of semi- and fully inductive link prediction tasks powered by recent advancements in graph neural networks. Our experiments on a novel set of benchmarks show that qualifiers over typed edges can lead to performance improvements of 6% of absolute gains (for the Hits@10 metric) compared to triple-only baselines. Our code is available at \url{https://github.com/mali-git/hyper_relational_ilp}.
Trans4E: Link Prediction on Scholarly Knowledge Graphs
Jul 03, 2021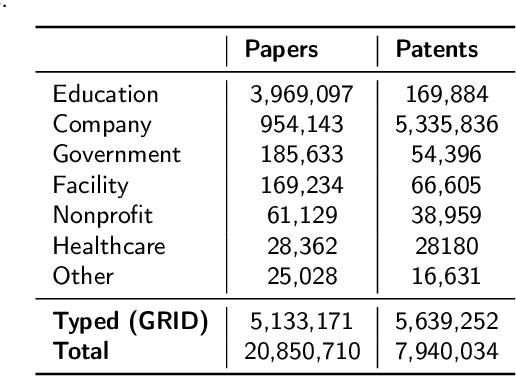
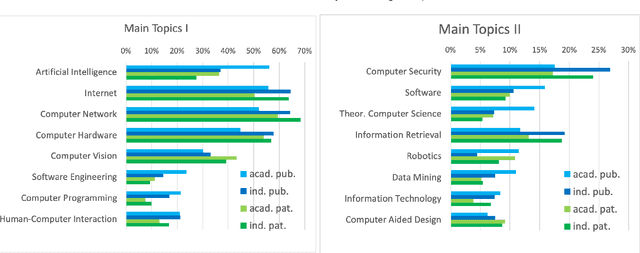
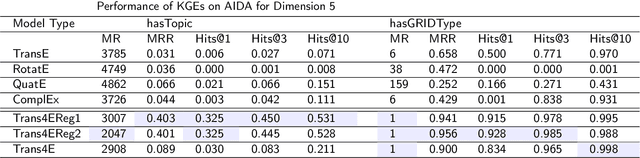
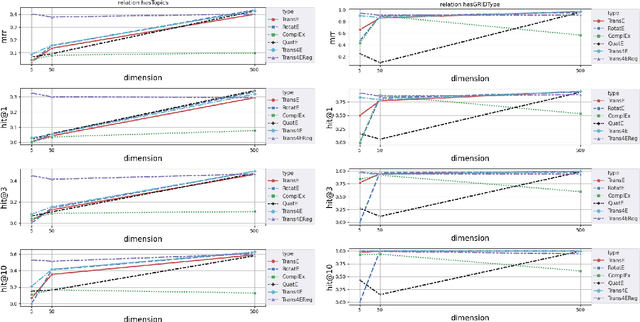
The incompleteness of Knowledge Graphs (KGs) is a crucial issue affecting the quality of AI-based services. In the scholarly domain, KGs describing research publications typically lack important information, hindering our ability to analyse and predict research dynamics. In recent years, link prediction approaches based on Knowledge Graph Embedding models became the first aid for this issue. In this work, we present Trans4E, a novel embedding model that is particularly fit for KGs which include N to M relations with N$\gg$M. This is typical for KGs that categorize a large number of entities (e.g., research articles, patents, persons) according to a relatively small set of categories. Trans4E was applied on two large-scale knowledge graphs, the Academia/Industry DynAmics (AIDA) and Microsoft Academic Graph (MAG), for completing the information about Fields of Study (e.g., 'neural networks', 'machine learning', 'artificial intelligence'), and affiliation types (e.g., 'education', 'company', 'government'), improving the scope and accuracy of the resulting data. We evaluated our approach against alternative solutions on AIDA, MAG, and four other benchmarks (FB15k, FB15k-237, WN18, and WN18RR). Trans4E outperforms the other models when using low embedding dimensions and obtains competitive results in high dimensions.
VOGUE: Answer Verbalization through Multi-Task Learning
Jun 28, 2021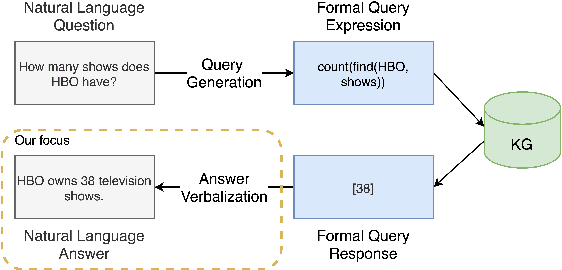
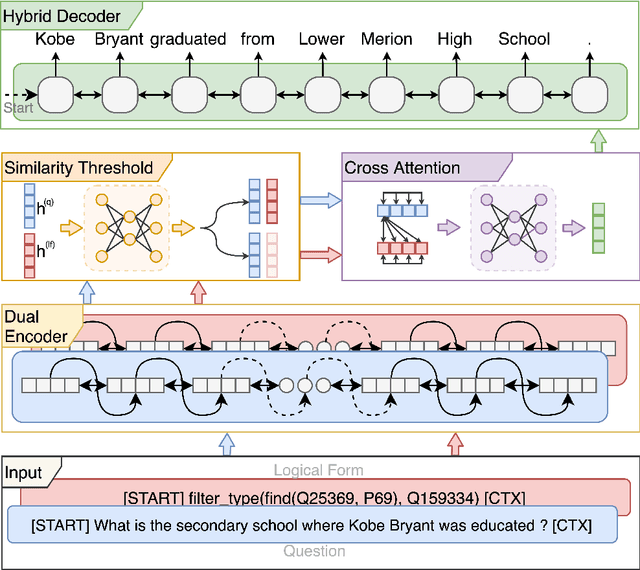
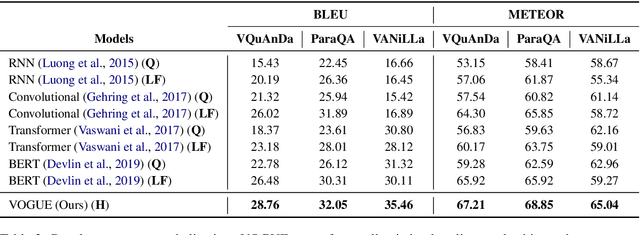
In recent years, there have been significant developments in Question Answering over Knowledge Graphs (KGQA). Despite all the notable advancements, current KGQA systems only focus on answer generation techniques and not on answer verbalization. However, in real-world scenarios (e.g., voice assistants such as Alexa, Siri, etc.), users prefer verbalized answers instead of a generated response. This paper addresses the task of answer verbalization for (complex) question answering over knowledge graphs. In this context, we propose a multi-task-based answer verbalization framework: VOGUE (Verbalization thrOuGh mUlti-task lEarning). The VOGUE framework attempts to generate a verbalized answer using a hybrid approach through a multi-task learning paradigm. Our framework can generate results based on using questions and queries as inputs concurrently. VOGUE comprises four modules that are trained simultaneously through multi-task learning. We evaluate our framework on existing datasets for answer verbalization, and it outperforms all current baselines on both BLEU and METEOR scores.
VANiLLa : Verbalized Answers in Natural Language at Large Scale
May 24, 2021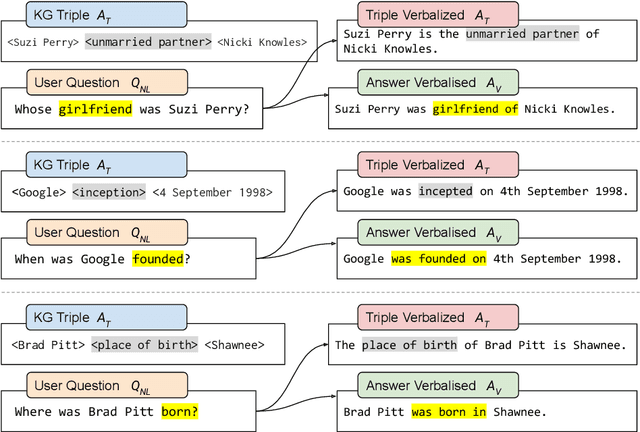
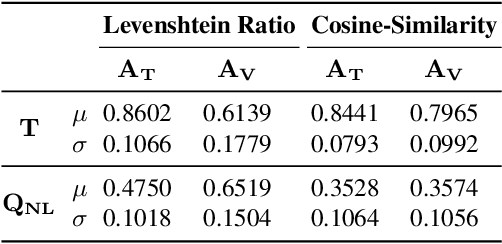
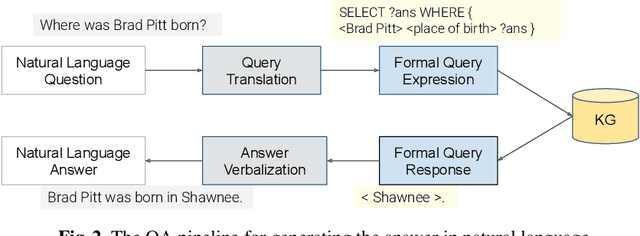
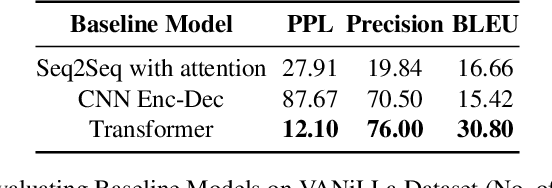
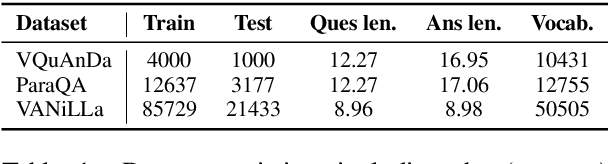
In the last years, there have been significant developments in the area of Question Answering over Knowledge Graphs (KGQA). Despite all the notable advancements, current KGQA datasets only provide the answers as the direct output result of the formal query, rather than full sentences incorporating question context. For achieving coherent answers sentence with the question's vocabulary, template-based verbalization so are usually employed for a better representation of answers, which in turn require extensive expert intervention. Thus, making way for machine learning approaches; however, there is a scarcity of datasets that empower machine learning models in this area. Hence, we provide the VANiLLa dataset which aims at reducing this gap by offering answers in natural language sentences. The answer sentences in this dataset are syntactically and semantically closer to the question than to the triple fact. Our dataset consists of over 100k simple questions adapted from the CSQA and SimpleQuestionsWikidata datasets and generated using a semi-automatic framework. We also present results of training our dataset on multiple baseline models adapted from current state-of-the-art Natural Language Generation (NLG) architectures. We believe that this dataset will allow researchers to focus on finding suitable methodologies and architectures for answer verbalization.
GeoWINE: Geolocation based Wiki, Image,News and Event Retrieval
May 04, 2021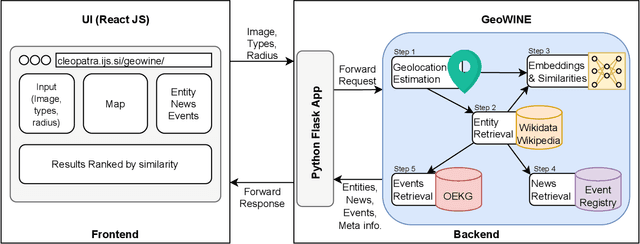

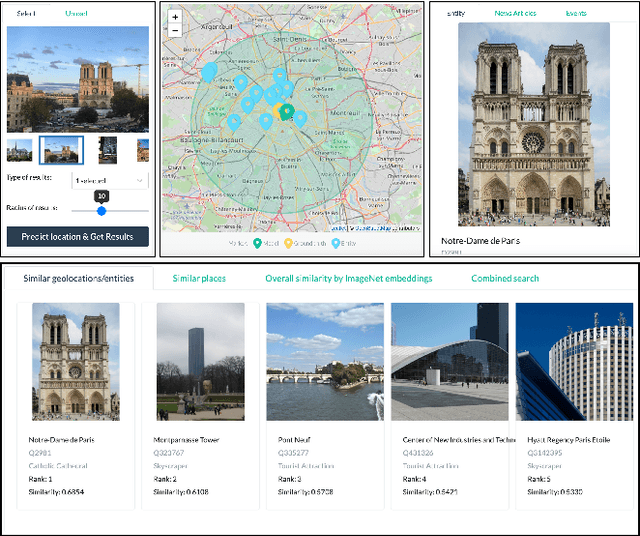
In the context of social media, geolocation inference on news or events has become a very important task. In this paper, we present the GeoWINE (Geolocation-based Wiki-Image-News-Event retrieval) demonstrator, an effective modular system for multimodal retrieval which expects only a single image as input. The GeoWINE system consists of five modules in order to retrieve related information from various sources. The first module is a state-of-the-art model for geolocation estimation of images. The second module performs a geospatial-based query for entity retrieval using the Wikidata knowledge graph. The third module exploits four different image embedding representations, which are used to retrieve most similar entities compared to the input image. The embeddings are derived from the tasks of geolocation estimation, place recognition, ImageNet-based image classification, and their combination. The last two modules perform news and event retrieval from EventRegistry and the Open Event Knowledge Graph (OEKG). GeoWINE provides an intuitive interface for end-users and is insightful for experts for reconfiguration to individual setups. The GeoWINE achieves promising results in entity label prediction for images on Google Landmarks dataset. The demonstrator is publicly available at http://cleopatra.ijs.si/geowine/.
Multiple Run Ensemble Learning withLow-Dimensional Knowledge Graph Embeddings
Apr 11, 2021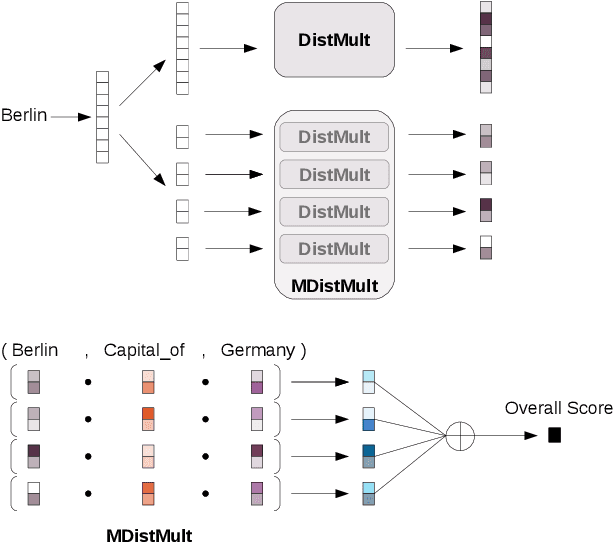
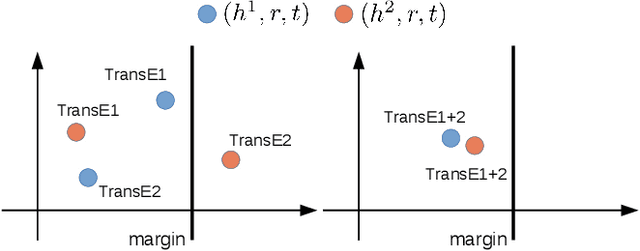
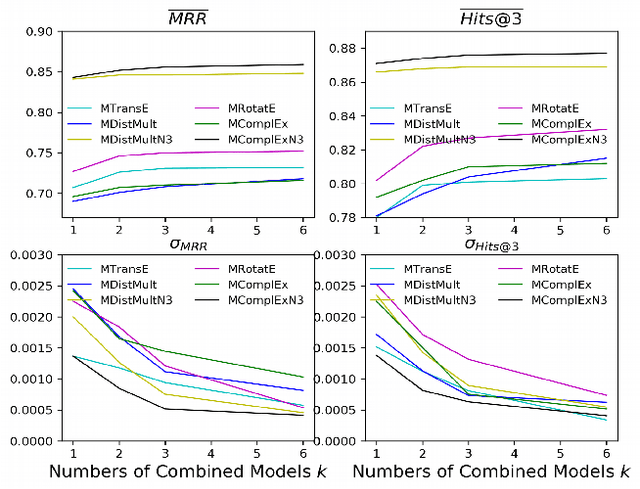
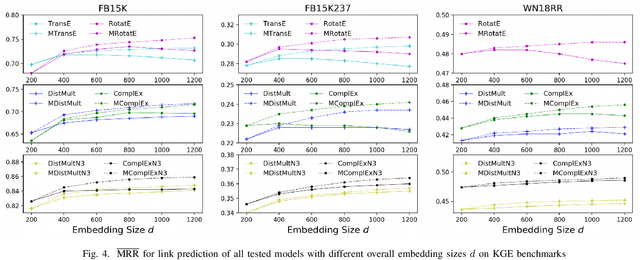
Among the top approaches of recent years, link prediction using knowledge graph embedding (KGE) models has gained significant attention for knowledge graph completion. Various embedding models have been proposed so far, among which, some recent KGE models obtain state-of-the-art performance on link prediction tasks by using embeddings with a high dimension (e.g. 1000) which accelerate the costs of training and evaluation considering the large scale of KGs. In this paper, we propose a simple but effective performance boosting strategy for KGE models by using multiple low dimensions in different repetition rounds of the same model. For example, instead of training a model one time with a large embedding size of 1200, we repeat the training of the model 6 times in parallel with an embedding size of 200 and then combine the 6 separate models for testing while the overall numbers of adjustable parameters are same (6*200=1200) and the total memory footprint remains the same. We show that our approach enables different models to better cope with their expressiveness issues on modeling various graph patterns such as symmetric, 1-n, n-1 and n-n. In order to justify our findings, we conduct experiments on various KGE models. Experimental results on standard benchmark datasets, namely FB15K, FB15K-237 and WN18RR, show that multiple low-dimensional models of the same kind outperform the corresponding single high-dimensional models on link prediction in a certain range and have advantages in training efficiency by using parallel training while the overall numbers of adjustable parameters are same.
Conversational Question Answering over Knowledge Graphs with Transformer and Graph Attention Networks
Apr 04, 2021
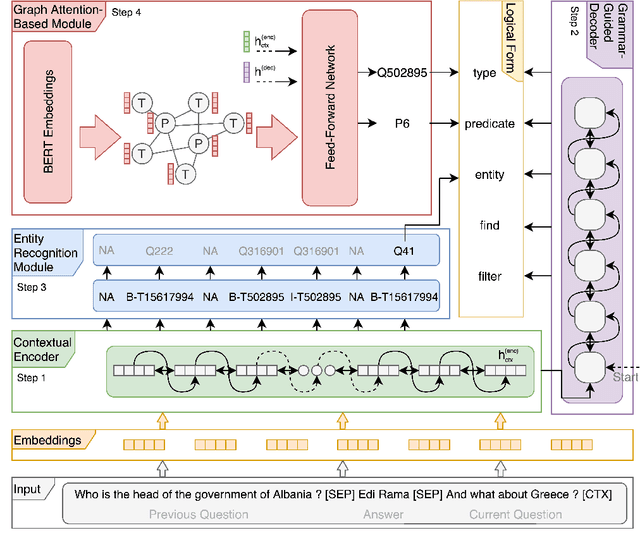
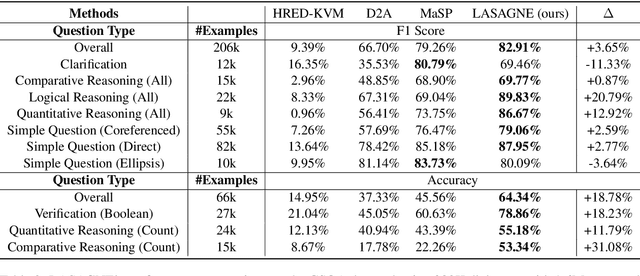
This paper addresses the task of (complex) conversational question answering over a knowledge graph. For this task, we propose LASAGNE (muLti-task semAntic parSing with trAnsformer and Graph atteNtion nEtworks). It is the first approach, which employs a transformer architecture extended with Graph Attention Networks for multi-task neural semantic parsing. LASAGNE uses a transformer model for generating the base logical forms, while the Graph Attention model is used to exploit correlations between (entity) types and predicates to produce node representations. LASAGNE also includes a novel entity recognition module which detects, links, and ranks all relevant entities in the question context. We evaluate LASAGNE on a standard dataset for complex sequential question answering, on which it outperforms existing baseline averages on all question types. Specifically, we show that LASAGNE improves the F1-score on eight out of ten question types; in some cases, the increase in F1-score is more than 20% compared to the state of the art.
Grounding Dialogue Systems via Knowledge Graph Aware Decoding with Pre-trained Transformers
Mar 30, 2021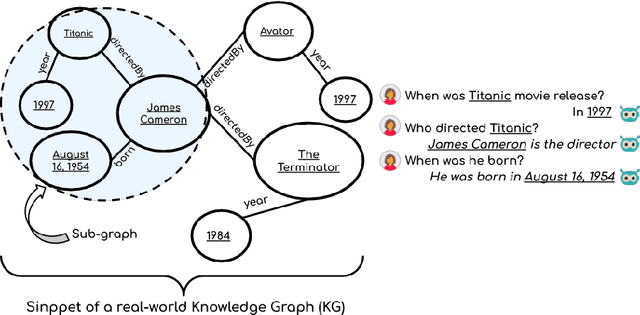
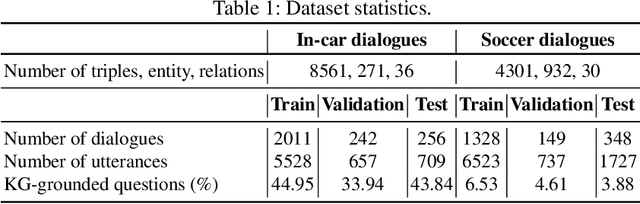
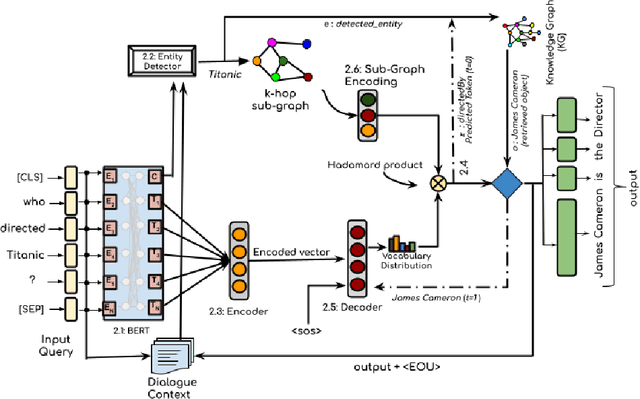
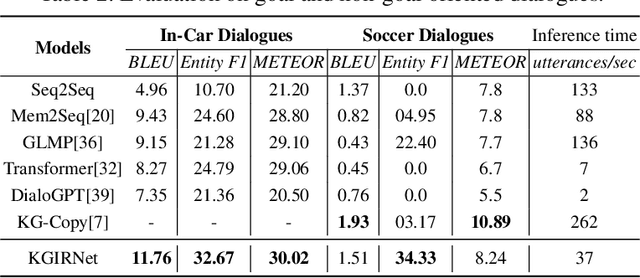
Generating knowledge grounded responses in both goal and non-goal oriented dialogue systems is an important research challenge. Knowledge Graphs (KG) can be viewed as an abstraction of the real world, which can potentially facilitate a dialogue system to produce knowledge grounded responses. However, integrating KGs into the dialogue generation process in an end-to-end manner is a non-trivial task. This paper proposes a novel architecture for integrating KGs into the response generation process by training a BERT model that learns to answer using the elements of the KG (entities and relations) in a multi-task, end-to-end setting. The k-hop subgraph of the KG is incorporated into the model during training and inference using Graph Laplacian. Empirical evaluation suggests that the model achieves better knowledge groundedness (measured via Entity F1 score) compared to other state-of-the-art models for both goal and non-goal oriented dialogues.