 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Detecting Label Errors using Pre-Trained Language Models
May 25, 2022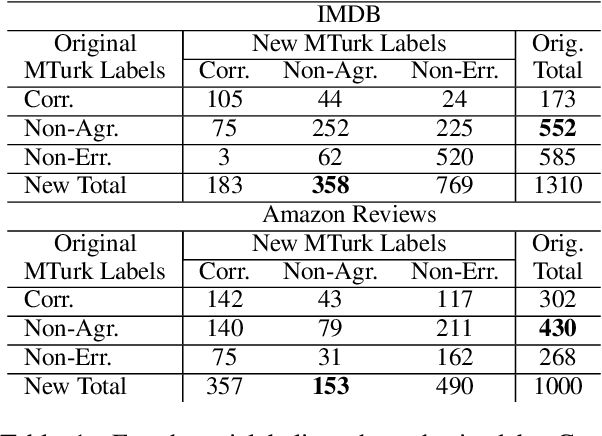
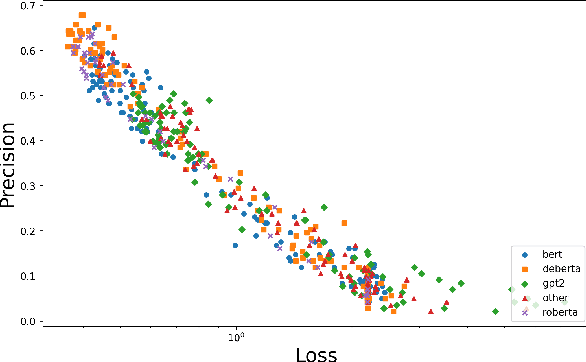
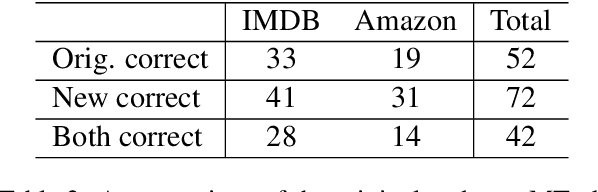
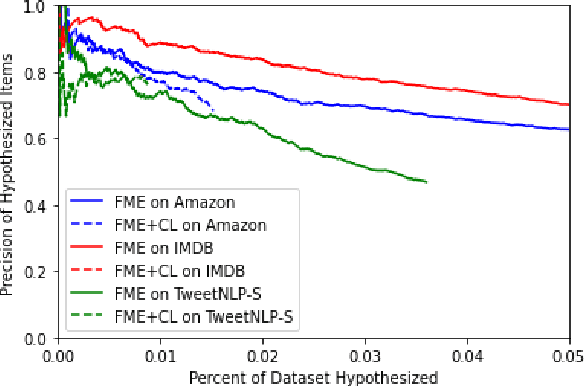
We show that large pre-trained language models are extremely capable of identifying label errors in datasets: simply verifying data points in descending order of out-of-distribution loss significantly outperforms more complex mechanisms for detecting label errors on natural language datasets. We contribute a novel method to produce highly realistic, human-originated label noise from crowdsourced data, and demonstrate the effectiveness of this method on TweetNLP, providing an otherwise difficult to obtain measure of realistic recall.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Convex Optimization in Julia
Oct 17, 2014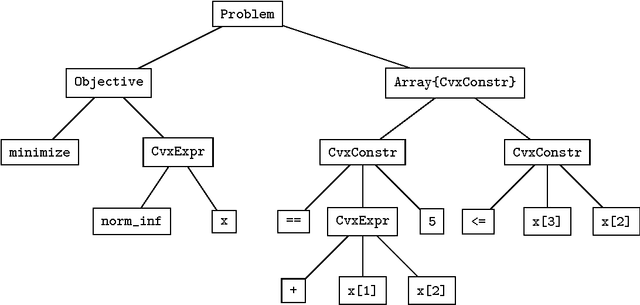
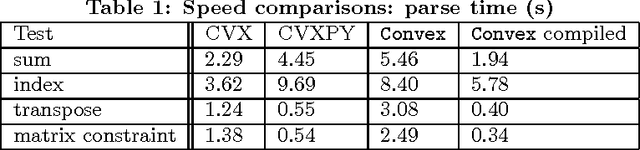
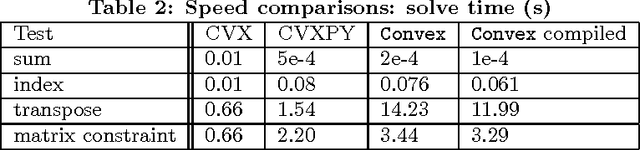
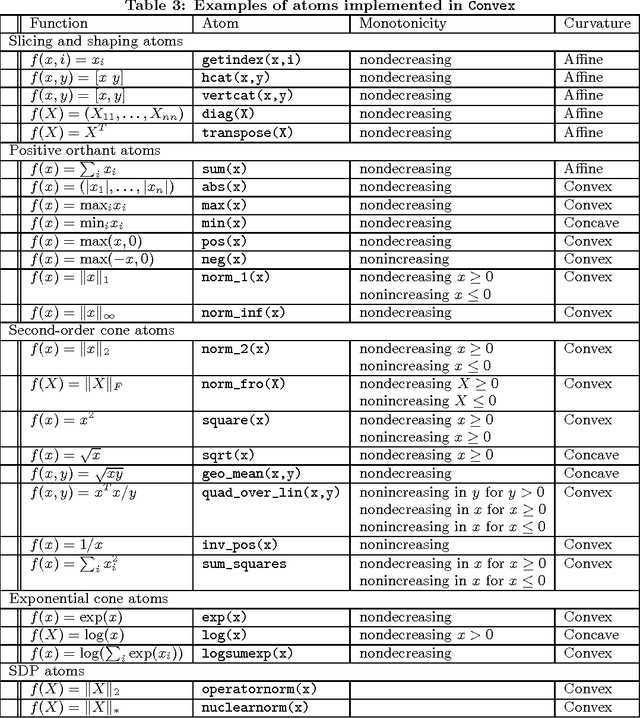
This paper describes Convex, a convex optimization modeling framework in Julia. Convex translates problems from a user-friendly functional language into an abstract syntax tree describing the problem. This concise representation of the global structure of the problem allows Convex to infer whether the problem complies with the rules of disciplined convex programming (DCP), and to pass the problem to a suitable solver. These operations are carried out in Julia using multiple dispatch, which dramatically reduces the time required to verify DCP compliance and to parse a problem into conic form. Convex then automatically chooses an appropriate backend solver to solve the conic form problem.