 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparCL: Sparse Continual Learning on the Edge
Sep 20, 2022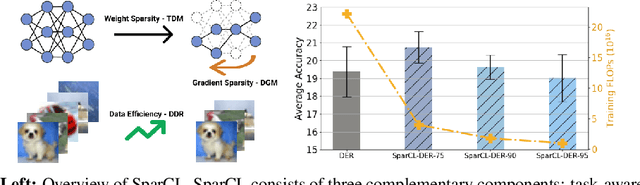
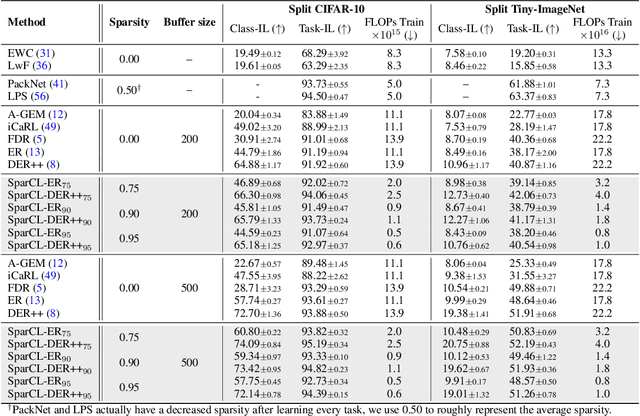
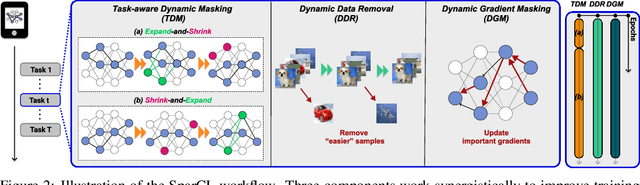
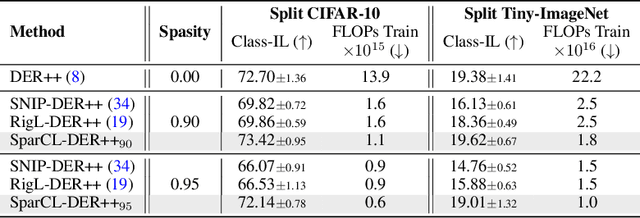
Existing work in continual learning (CL) focuses on mitigating catastrophic forgetting, i.e., model performance deterioration on past tasks when learning a new task. However, the training efficiency of a CL system is under-investigated, which limits the real-world application of CL systems under resource-limited scenarios. In this work, we propose a novel framework called Sparse Continual Learning(SparCL), which is the first study that leverages sparsity to enable cost-effective continual learning on edge devices. SparCL achieves both training acceleration and accuracy preservation through the synergy of three aspects: weight sparsity, data efficiency, and gradient sparsity. Specifically, we propose task-aware dynamic masking (TDM) to learn a sparse network throughout the entire CL process, dynamic data removal (DDR) to remove less informative training data, and dynamic gradient masking (DGM) to sparsify the gradient updates. Each of them not only improves efficiency, but also further mitigates catastrophic forgetting. SparCL consistently improves the training efficiency of existing state-of-the-art (SOTA) CL methods by at most 23X less training FLOPs, and, surprisingly, further improves the SOTA accuracy by at most 1.7%. SparCL also outperforms competitive baselines obtained from adapting SOTA sparse training methods to the CL setting in both efficiency and accuracy. We also evaluate the effectiveness of SparCL on a real mobile phone, further indicating the practical potential of our method.
Analyzing the Effects of Classifier Lipschitzness on Explainers
Jun 24, 2022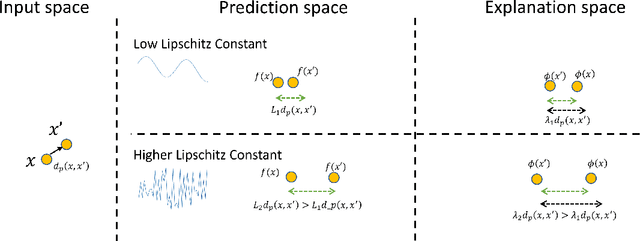
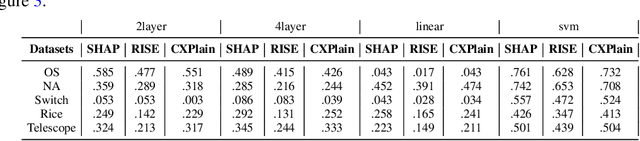
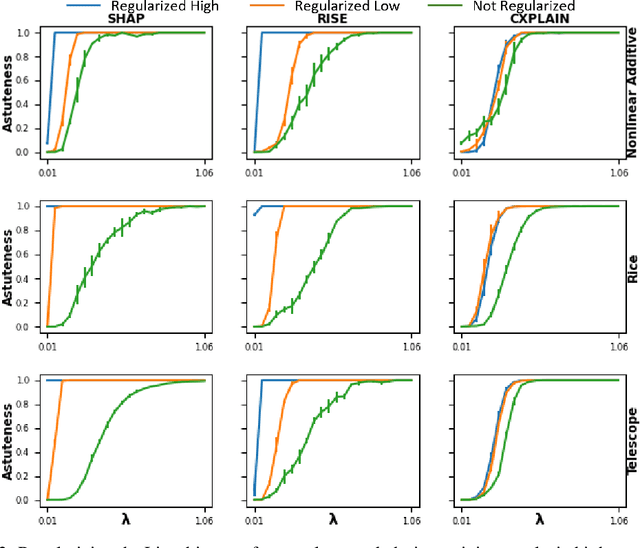
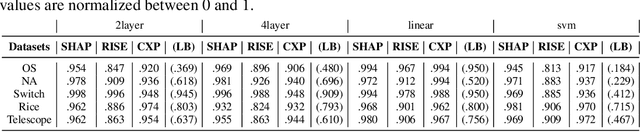
Machine learning methods are getting increasingly better at making predictions, but at the same time they are also becoming more complicated and less transparent. As a result, explainers are often relied on to provide interpretability to these black-box prediction models. As crucial diagnostics tools, it is important that these explainers themselves are reliable. In this paper we focus on one particular aspect of reliability, namely that an explainer should give similar explanations for similar data inputs. We formalize this notion by introducing and defining explainer astuteness, analogous to astuteness of classifiers. Our formalism is inspired by the concept of probabilistic Lipschitzness, which captures the probability of local smoothness of a function. For a variety of explainers (e.g., SHAP, RISE, CXPlain), we provide lower bound guarantees on the astuteness of these explainers given the Lipschitzness of the prediction function. These theoretical results imply that locally smooth prediction functions lend themselves to locally robust explanations. We evaluate these results empirically on simulated as well as real datasets.
DualPrompt: Complementary Prompting for Rehearsal-free Continual Learning
Apr 10, 2022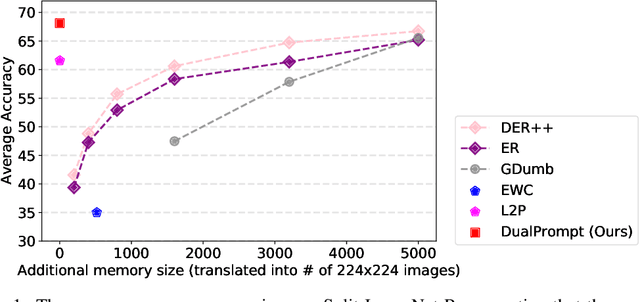
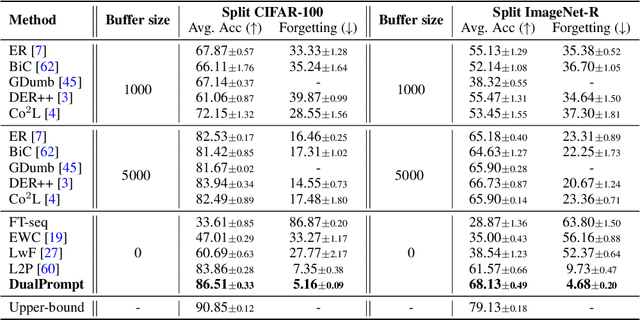
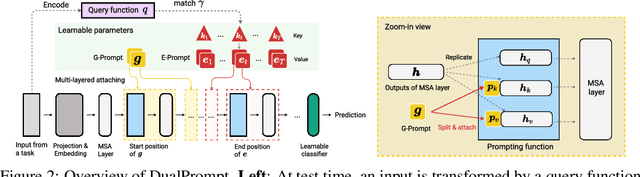
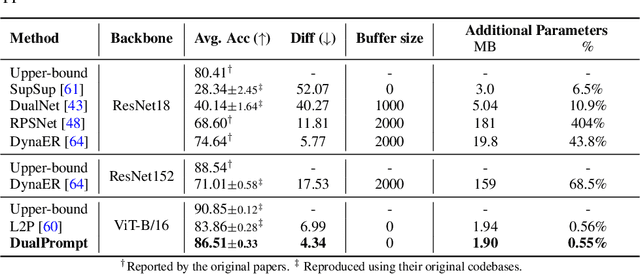
Continual learning aims to enable a single model to learn a sequence of tasks without catastrophic forgetting. Top-performing methods usually require a rehearsal buffer to store past pristine examples for experience replay, which, however, limits their practical value due to privacy and memory constraints. In this work, we present a simple yet effective framework, DualPrompt, which learns a tiny set of parameters, called prompts, to properly instruct a pre-trained model to learn tasks arriving sequentially without buffering past examples. DualPrompt presents a novel approach to attach complementary prompts to the pre-trained backbone, and then formulates the objective as learning task-invariant and task-specific "instructions". With extensive experimental validation, DualPrompt consistently sets state-of-the-art performance under the challenging class-incremental setting. In particular, DualPrompt outperforms recent advanced continual learning methods with relatively large buffer sizes. We also introduce a more challenging benchmark, Split ImageNet-R, to help generalize rehearsal-free continual learning research. Source code is available at https://github.com/google-research/l2p.
Deep Layer-wise Networks Have Closed-Form Weights
Feb 07, 2022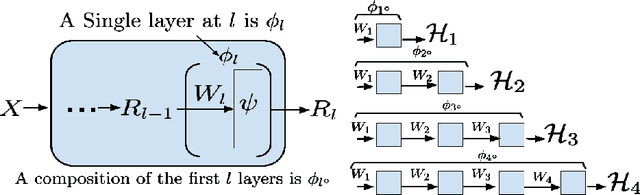
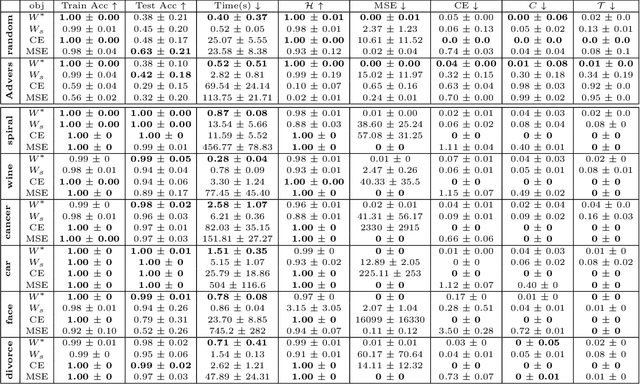
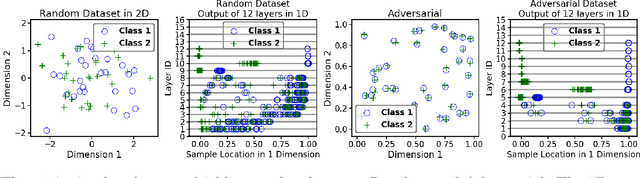
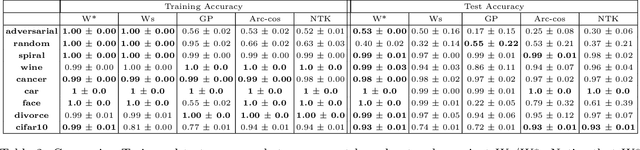
There is currently a debate within the neuroscience community over the likelihood of the brain performing backpropagation (BP). To better mimic the brain, training a network \textit{one layer at a time} with only a "single forward pass" has been proposed as an alternative to bypass BP; we refer to these networks as "layer-wise" networks. We continue the work on layer-wise networks by answering two outstanding questions. First, $\textit{do they have a closed-form solution?}$ Second, $\textit{how do we know when to stop adding more layers?}$ This work proves that the Kernel Mean Embedding is the closed-form weight that achieves the network global optimum while driving these networks to converge towards a highly desirable kernel for classification; we call it the $\textit{Neural Indicator Kernel}$.
* Since this version is similar to an older version, I should have updated the older version instead of creating a new version. I will now retract this version, and update a previous version to this. See arXiv:2006.08539
Deep Learning on Multimodal Sensor Data at the Wireless Edge for Vehicular Network
Jan 12, 2022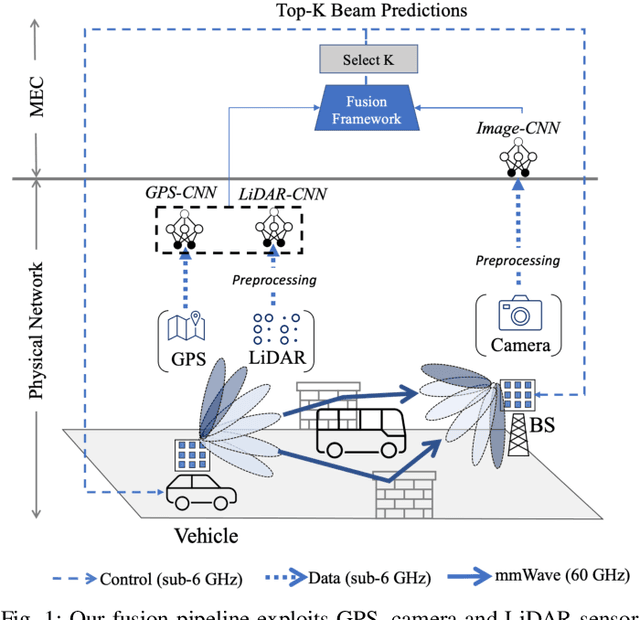
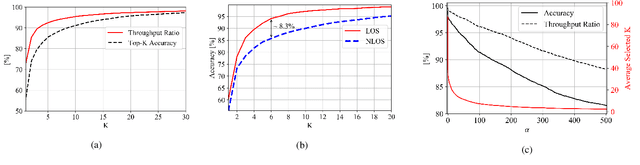
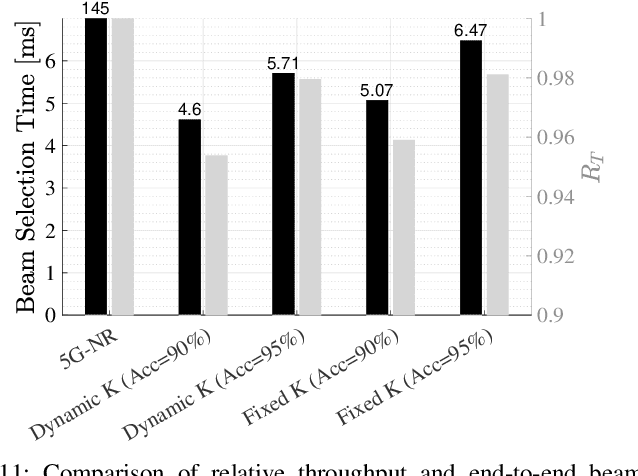
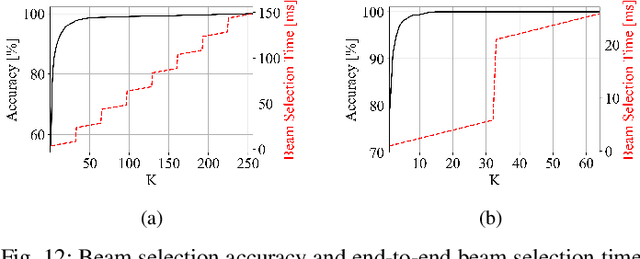
Beam selection for millimeter-wave links in a vehicular scenario is a challenging problem, as an exhaustive search among all candidate beam pairs cannot be assuredly completed within short contact times. We solve this problem via a novel expediting beam selection by leveraging multimodal data collected from sensors like LiDAR, camera images, and GPS. We propose individual modality and distributed fusion-based deep learning (F-DL) architectures that can execute locally as well as at a mobile edge computing center (MEC), with a study on associated tradeoffs. We also formulate and solve an optimization problem that considers practical beam-searching, MEC processing and sensor-to-MEC data delivery latency overheads for determining the output dimensions of the above F-DL architectures. Results from extensive evaluations conducted on publicly available synthetic and home-grown real-world datasets reveal 95% and 96% improvement in beam selection speed over classical RF-only beam sweeping, respectively. F-DL also outperforms the state-of-the-art techniques by 20-22% in predicting top-10 best beam pairs.
Learning to Prompt for Continual Learning
Dec 16, 2021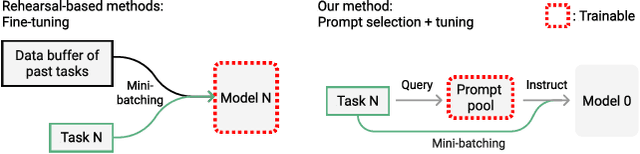
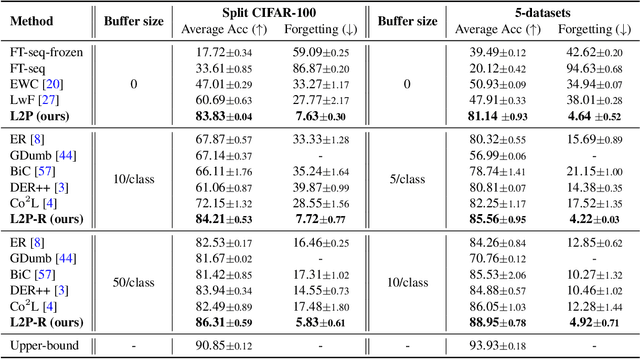
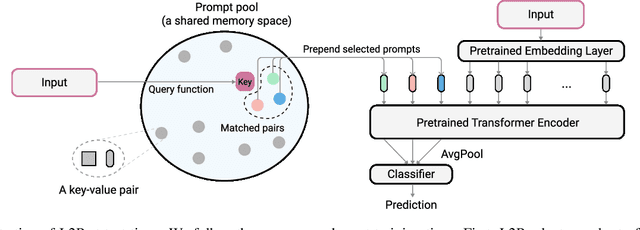
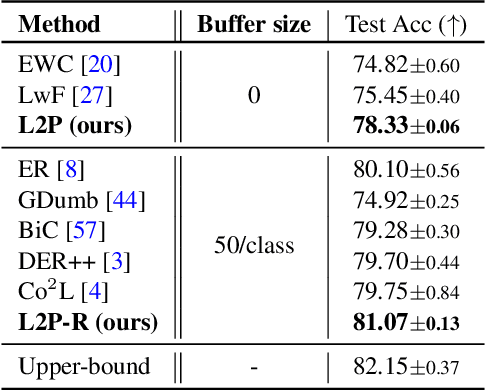
The mainstream paradigm behind continual learning has been to adapt the model parameters to non-stationary data distributions, where catastrophic forgetting is the central challenge. Typical methods rely on a rehearsal buffer or known task identity at test time to retrieve learned knowledge and address forgetting, while this work presents a new paradigm for continual learning that aims to train a more succinct memory system without accessing task identity at test time. Our method learns to dynamically prompt (L2P) a pre-trained model to learn tasks sequentially under different task transitions. In our proposed framework, prompts are small learnable parameters, which are maintained in a memory space. The objective is to optimize prompts to instruct the model prediction and explicitly manage task-invariant and task-specific knowledge while maintaining model plasticity. We conduct comprehensive experiments under popular image classification benchmarks with different challenging continual learning settings, where L2P consistently outperforms prior state-of-the-art methods. Surprisingly, L2P achieves competitive results against rehearsal-based methods even without a rehearsal buffer and is directly applicable to challenging task-agnostic continual learning. Source code is available at https://github.com/google-research/l2p.
Unsupervised Approaches for Out-Of-Distribution Dermoscopic Lesion Detection
Nov 08, 2021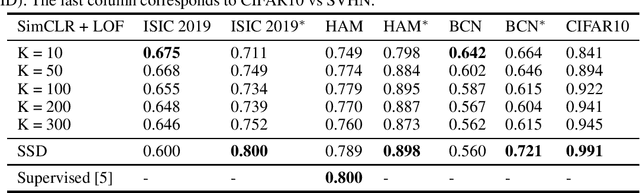

There are limited works showing the efficacy of unsupervised Out-of-Distribution (OOD) methods on complex medical data. Here, we present preliminary findings of our unsupervised OOD detection algorithm, SimCLR-LOF, as well as a recent state of the art approach (SSD), applied on medical images. SimCLR-LOF learns semantically meaningful features using SimCLR and uses LOF for scoring if a test sample is OOD. We evaluated on the multi-source International Skin Imaging Collaboration (ISIC) 2019 dataset, and show results that are competitive with SSD as well as with recent supervised approaches applied on the same data.
Reliable Estimation of KL Divergence using a Discriminator in Reproducing Kernel Hilbert Space
Sep 29, 2021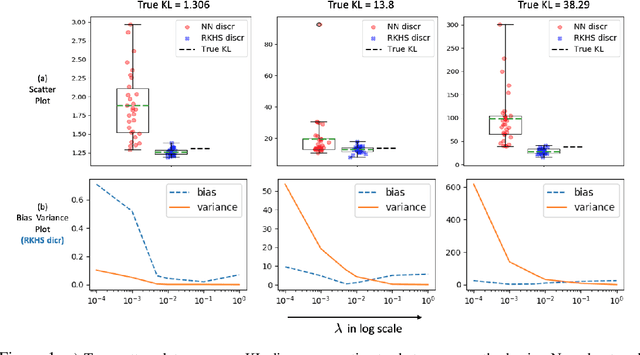

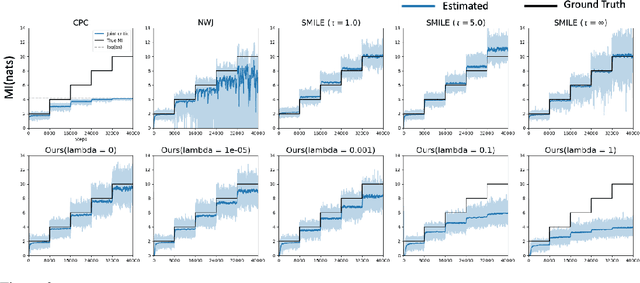
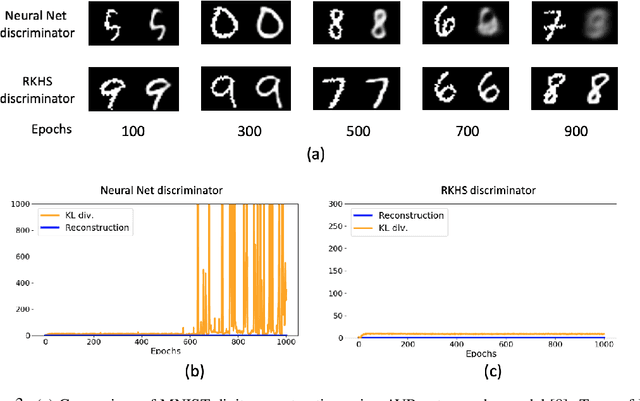
Estimating Kullback Leibler (KL) divergence from samples of two distributions is essential in many machine learning problems. Variational methods using neural network discriminator have been proposed to achieve this task in a scalable manner. However, we noted that most of these methods using neural network discriminators suffer from high fluctuations (variance) in estimates and instability in training. In this paper, we look at this issue from statistical learning theory and function space complexity perspective to understand why this happens and how to solve it. We argue that the cause of these pathologies is lack of control over the complexity of the neural network discriminator function and could be mitigated by controlling it. To achieve this objective, we 1) present a novel construction of the discriminator in the Reproducing Kernel Hilbert Space (RKHS), 2) theoretically relate the error probability bound of the KL estimates to the complexity of the discriminator in the RKHS space, 3) present a scalable way to control the complexity (RKHS norm) of the discriminator for a reliable estimation of KL divergence, and 4) prove the consistency of the proposed estimator. In three different applications of KL divergence : estimation of KL, estimation of mutual information and Variational Bayes, we show that by controlling the complexity as developed in the theory, we are able to reduce the variance of KL estimates and stabilize the training
* 27 pages, 3 figures. arXiv admin note: text overlap with arXiv:2002.11187
Deep Bayesian Unsupervised Lifelong Learning
Jun 13, 2021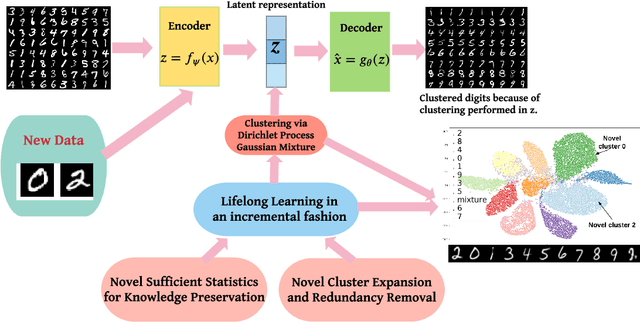

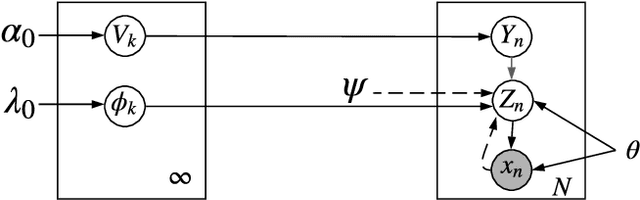
Lifelong Learning (LL) refers to the ability to continually learn and solve new problems with incremental available information over time while retaining previous knowledge. Much attention has been given lately to Supervised Lifelong Learning (SLL) with a stream of labelled data. In contrast, we focus on resolving challenges in Unsupervised Lifelong Learning (ULL) with streaming unlabelled data when the data distribution and the unknown class labels evolve over time. Bayesian framework is natural to incorporate past knowledge and sequentially update the belief with new data. We develop a fully Bayesian inference framework for ULL with a novel end-to-end Deep Bayesian Unsupervised Lifelong Learning (DBULL) algorithm, which can progressively discover new clusters without forgetting the past with unlabelled data while learning latent representations. To efficiently maintain past knowledge, we develop a novel knowledge preservation mechanism via sufficient statistics of the latent representation for raw data. To detect the potential new clusters on the fly, we develop an automatic cluster discovery and redundancy removal strategy in our inference inspired by Nonparametric Bayesian statistics techniques. We demonstrate the effectiveness of our approach using image and text corpora benchmark datasets in both LL and batch settings.
Revisiting Hilbert-Schmidt Information Bottleneck for Adversarial Robustness
Jun 04, 2021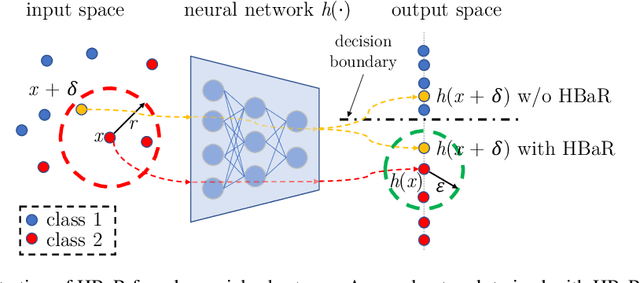
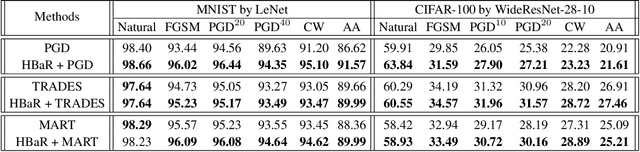
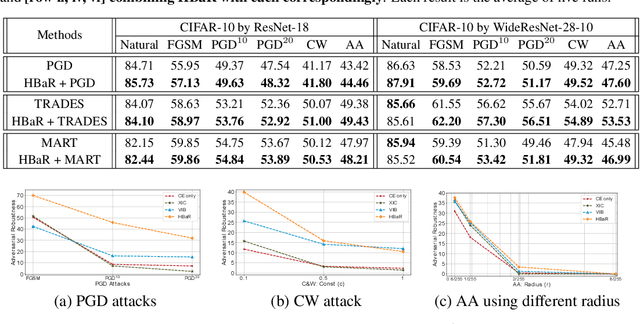
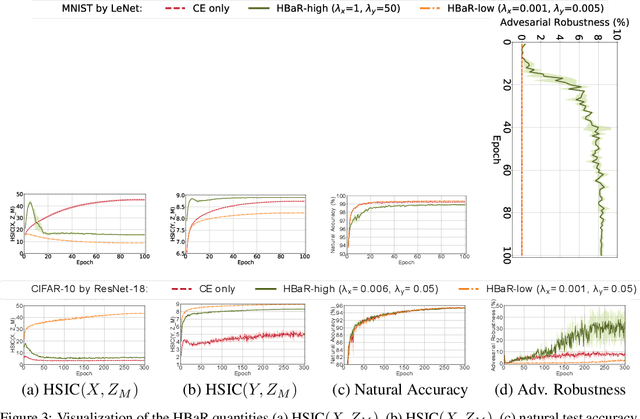
We investigate the HSIC (Hilbert-Schmidt independence criterion) bottleneck as a regularizer for learning an adversarially robust deep neural network classifier. We show that the HSIC bottleneck enhances robustness to adversarial attacks both theoretically and experimentally. Our experiments on multiple benchmark datasets and architectures demonstrate that incorporating an HSIC bottleneck regularizer attains competitive natural accuracy and improves adversarial robustness, both with and without adversarial examples during training.