 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Neural Operators for Multi-Dimensional Fluid Dynamics
May 12, 2026Partial differential equations (PDEs) govern diverse physical phenomena, yet high-fidelity numerical solutions are computationally expensive and Machine Learning approaches lack generalization. While Scientific Foundation Models (SFMs) aim to provide universal surrogates, typical encoding-decoding approaches suffer from high pretraining costs and limited interpretability. In this paper, we propose Compositional Neural Operators (CompNO) for 2D systems, a framework that decomposes complex PDEs into a library of Foundation Blocks. Each block is a specialized Neural Operator pretrained on elementary physics. This modular library contains convection, diffusion, and nonlinear convection blocks as well as a Poisson Solver, enabling the framework to address the pressure-velocity coupling. These experts are assembled via an Adaptation Block featuring an Aggregator. This aggregator learns nonlinear interactions by minimizing data loss and physics-based residuals driven from governing equations. The proposed approach has been evaluated on the Convection-Diffusion equation, the Burgers' equation, and the Incompressible Navier-Stokes equation. Our results demonstrate that learning from elementary operators significantly improves adaptability, enhances model interpretability and facilitates the reuse of pretrained blocks when adapting to new physical systems.
Audio-Visual Speech Enhancement Using Multimodal Deep Convolutional Neural Networks
Jan 24, 2018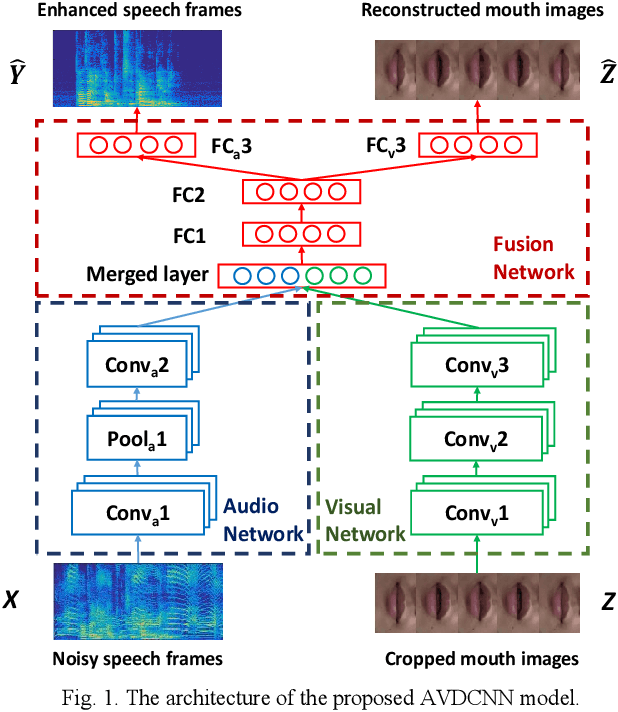
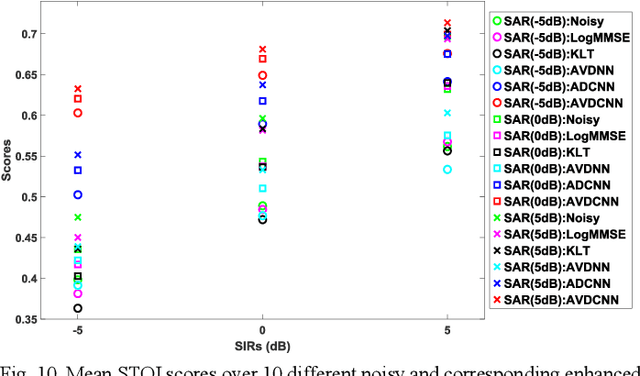
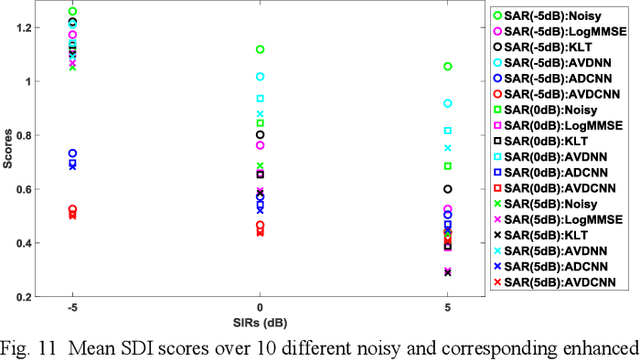
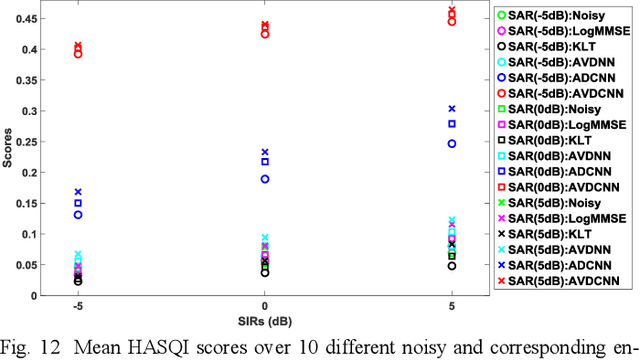
Speech enhancement (SE) aims to reduce noise in speech signals. Most SE techniques focus only on addressing audio information. In this work, inspired by multimodal learning, which utilizes data from different modalities, and the recent success of convolutional neural networks (CNNs) in SE, we propose an audio-visual deep CNNs (AVDCNN) SE model, which incorporates audio and visual streams into a unified network model. We also propose a multi-task learning framework for reconstructing audio and visual signals at the output layer. Precisely speaking, the proposed AVDCNN model is structured as an audio-visual encoder-decoder network, in which audio and visual data are first processed using individual CNNs, and then fused into a joint network to generate enhanced speech (the primary task) and reconstructed images (the secondary task) at the output layer. The model is trained in an end-to-end manner, and parameters are jointly learned through back-propagation. We evaluate enhanced speech using five instrumental criteria. Results show that the AVDCNN model yields a notably superior performance compared with an audio-only CNN-based SE model and two conventional SE approaches, confirming the effectiveness of integrating visual information into the SE process. In addition, the AVDCNN model also outperforms an existing audio-visual SE model, confirming its capability of effectively combining audio and visual information in SE.