 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Segment Actions from Observation and Narration
May 07, 2020

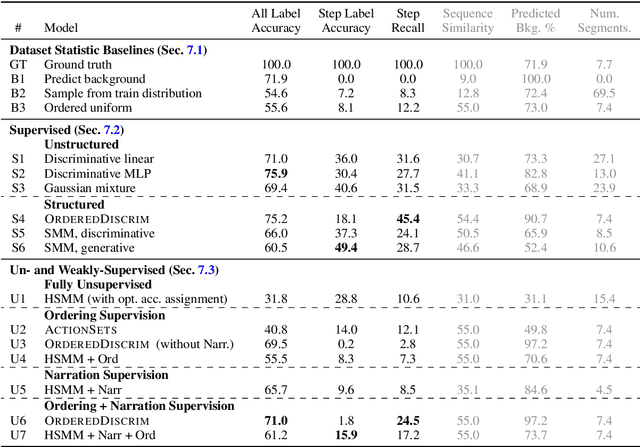
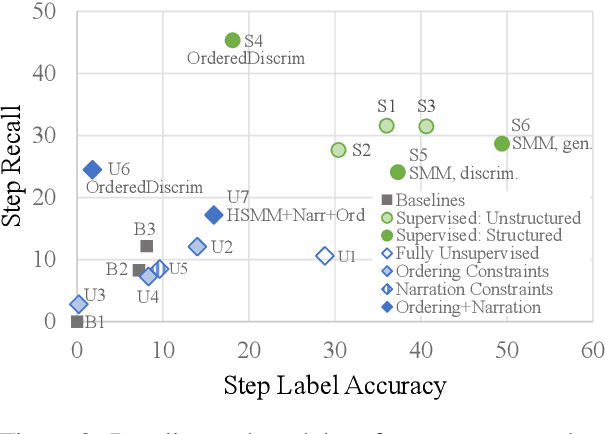
We apply a generative segmental model of task structure, guided by narration, to action segmentation in video. We focus on unsupervised and weakly-supervised settings where no action labels are known during training. Despite its simplicity, our model performs competitively with previous work on a dataset of naturalistic instructional videos. Our model allows us to vary the sources of supervision used in training, and we find that both task structure and narrative language provide large benefits in segmentation quality.
Visual Grounding in Video for Unsupervised Word Translation
Mar 26, 2020
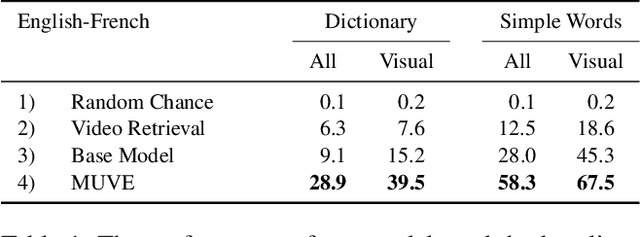
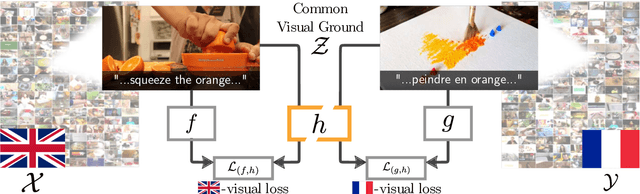
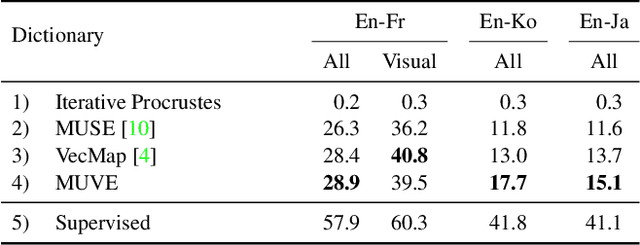
There are thousands of actively spoken languages on Earth, but a single visual world. Grounding in this visual world has the potential to bridge the gap between all these languages. Our goal is to use visual grounding to improve unsupervised word mapping between languages. The key idea is to establish a common visual representation between two languages by learning embeddings from unpaired instructional videos narrated in the native language. Given this shared embedding we demonstrate that (i) we can map words between the languages, particularly the 'visual' words; (ii) that the shared embedding provides a good initialization for existing unsupervised text-based word translation techniques, forming the basis for our proposed hybrid visual-text mapping algorithm, MUVE; and (iii) our approach achieves superior performance by addressing the shortcomings of text-based methods -- it is more robust, handles datasets with less commonality, and is applicable to low-resource languages. We apply these methods to translate words from English to French, Korean, and Japanese -- all without any parallel corpora and simply by watching many videos of people speaking while doing things.
* CVPR 2020
End-to-End Learning of Visual Representations from Uncurated Instructional Videos
Jan 17, 2020

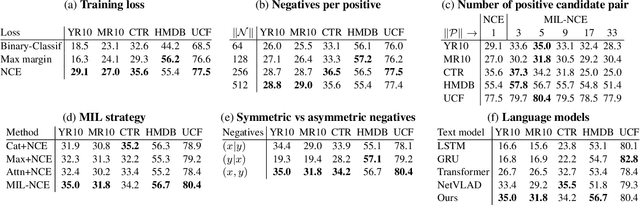
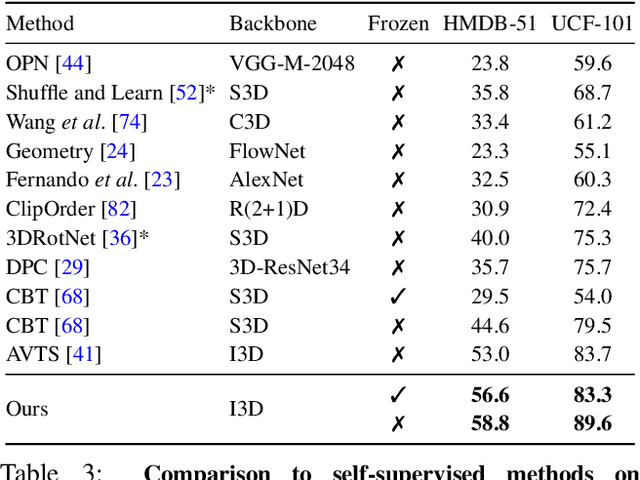
Annotating videos is cumbersome, expensive and not scalable. Yet, many strong video models still rely on manually annotated data. With the recent introduction of the HowTo100M dataset, narrated videos now offer the possibility of learning video representations without manual supervision. In this work we propose a new learning approach, MIL-NCE, capable of addressing misalignments inherent to narrated videos. With this approach we are able to learn strong video representations from scratch, without the need for any manual annotation. We evaluate our representations on a wide range of four downstream tasks over eight datasets: action recognition (HMDB-51, UCF-101, Kinetics-700), text-to-video retrieval (YouCook2, MSR-VTT), action localization (YouTube-8M Segments, CrossTask) and action segmentation (COIN). Our method outperforms all published self-supervised approaches for these tasks as well as several fully supervised baselines.
Controllable Attention for Structured Layered Video Decomposition
Oct 24, 2019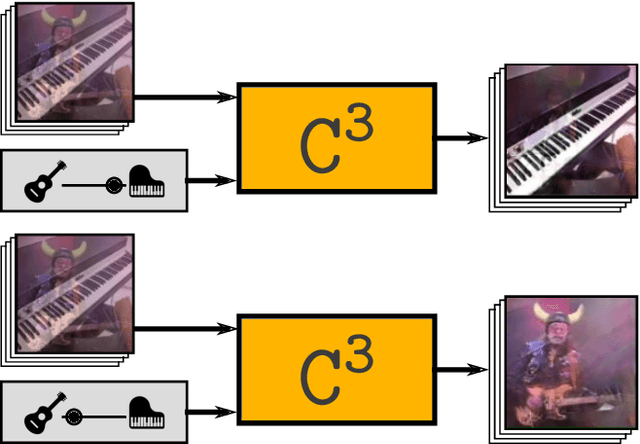
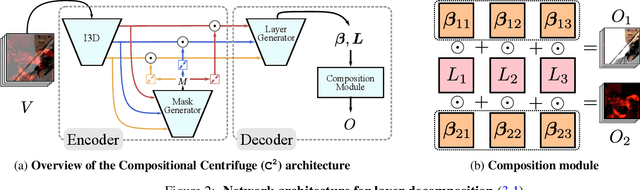
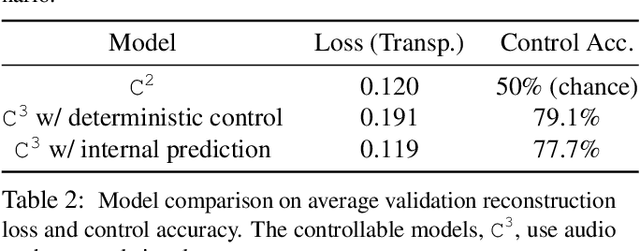
The objective of this paper is to be able to separate a video into its natural layers, and to control which of the separated layers to attend to. For example, to be able to separate reflections, transparency or object motion. We make the following three contributions: (i) we introduce a new structured neural network architecture that explicitly incorporates layers (as spatial masks) into its design. This improves separation performance over previous general purpose networks for this task; (ii) we demonstrate that we can augment the architecture to leverage external cues such as audio for controllability and to help disambiguation; and (iii) we experimentally demonstrate the effectiveness of our approach and training procedure with controlled experiments while also showing that the proposed model can be successfully applied to real-word applications such as reflection removal and action recognition in cluttered scenes.
HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips
Jul 31, 2019
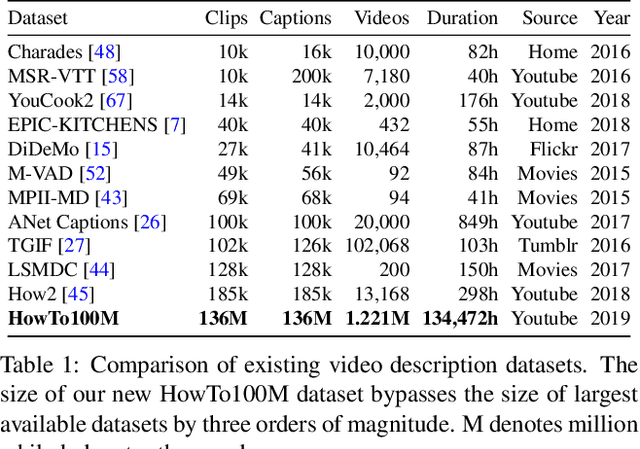

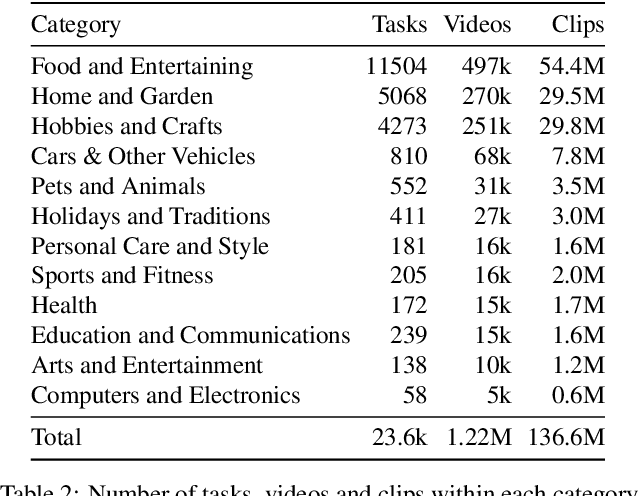
Learning text-video embeddings usually requires a dataset of video clips with manually provided captions. However, such datasets are expensive and time consuming to create and therefore difficult to obtain on a large scale. In this work, we propose instead to learn such embeddings from video data with readily available natural language annotations in the form of automatically transcribed narrations. The contributions of this work are three-fold. First, we introduce HowTo100M: a large-scale dataset of 136 million video clips sourced from 1.22M narrated instructional web videos depicting humans performing and describing over 23k different visual tasks. Our data collection procedure is fast, scalable and does not require any additional manual annotation. Second, we demonstrate that a text-video embedding trained on this data leads to state-of-the-art results for text-to-video retrieval and action localization on instructional video datasets such as YouCook2 or CrossTask. Finally, we show that this embedding transfers well to other domains: fine-tuning on generic Youtube videos (MSR-VTT dataset) and movies (LSMDC dataset) outperforms models trained on these datasets alone. Our dataset, code and models will be publicly available at: www.di.ens.fr/willow/research/howto100m/.
Cross-task weakly supervised learning from instructional videos
Mar 19, 2019
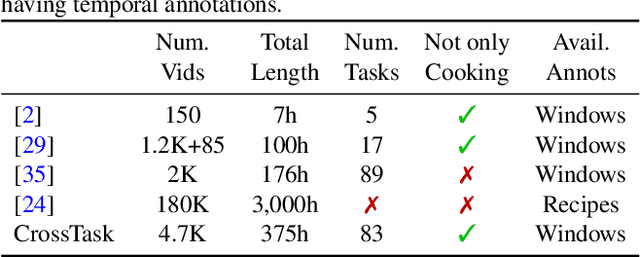
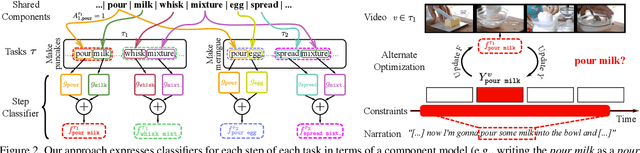
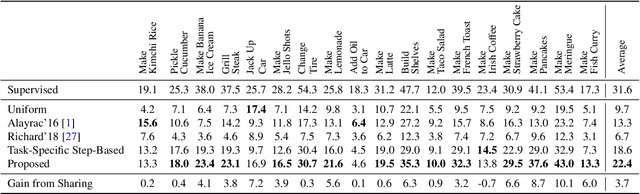
In this paper we investigate learning visual models for the steps of ordinary tasks using weak supervision via instructional narrations and an ordered list of steps instead of strong supervision via temporal annotations. At the heart of our approach is the observation that weakly supervised learning may be easier if a model shares components while learning different steps: `pour egg' should be trained jointly with other tasks involving `pour' and `egg'. We formalize this in a component model for recognizing steps and a weakly supervised learning framework that can learn this model under temporal constraints from narration and the list of steps. Past data does not permit systematic studying of sharing and so we also gather a new dataset, CrossTask, aimed at assessing cross-task sharing. Our experiments demonstrate that sharing across tasks improves performance, especially when done at the component level and that our component model can parse previously unseen tasks by virtue of its compositionality.
The Visual Centrifuge: Model-Free Layered Video Representations
Dec 04, 2018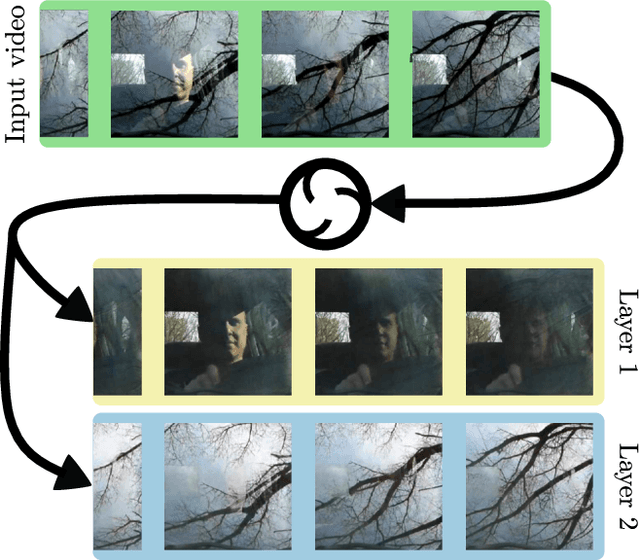

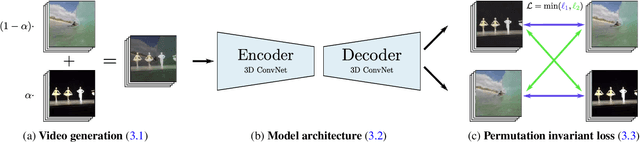
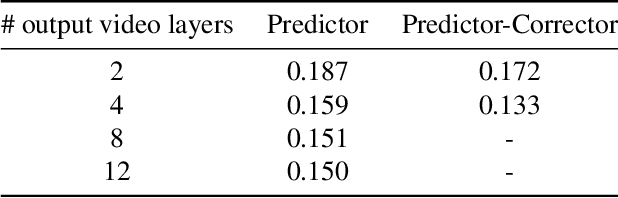
True video understanding requires making sense of non-lambertian scenes where the color of light arriving at the camera sensor encodes information about not just the last object it collided with, but about multiple mediums -- colored windows, dirty mirrors, smoke or rain. Layered video representations have the potential of accurately modelling realistic scenes but have so far required stringent assumptions on motion, lighting and shape. Here we propose a learning-based approach for multi-layered video representation: we introduce novel uncertainty-capturing 3D convolutional architectures and train them to separate blended videos. We show that these models then generalize to single videos, where they exhibit interesting abilities: color constancy, factoring out shadows and separating reflections. We present quantitative and qualitative results on real world videos.
Learning to Localize and Align Fine-Grained Actions to Sparse Instructions
Sep 22, 2018
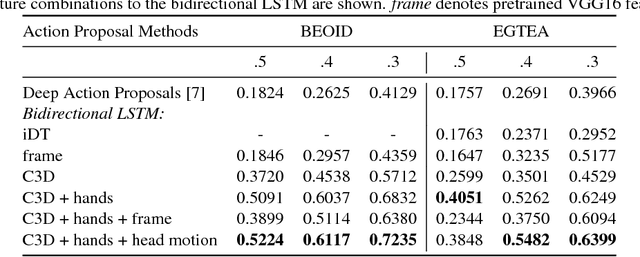
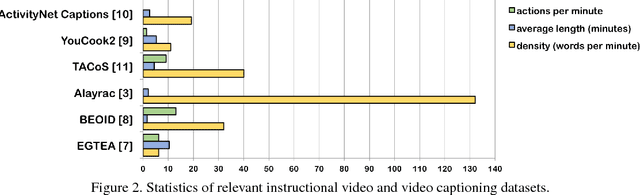
Automatic generation of textual video descriptions that are time-aligned with video content is a long-standing goal in computer vision. The task is challenging due to the difficulty of bridging the semantic gap between the visual and natural language domains. This paper addresses the task of automatically generating an alignment between a set of instructions and a first person video demonstrating an activity. The sparse descriptions and ambiguity of written instructions create significant alignment challenges. The key to our approach is the use of egocentric cues to generate a concise set of action proposals, which are then matched to recipe steps using object recognition and computational linguistic techniques. We obtain promising results on both the Extended GTEA Gaze+ dataset and the Bristol Egocentric Object Interactions Dataset.
A flexible model for training action localization with varying levels of supervision
Jun 29, 2018

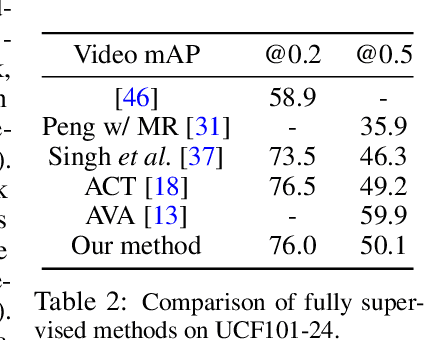
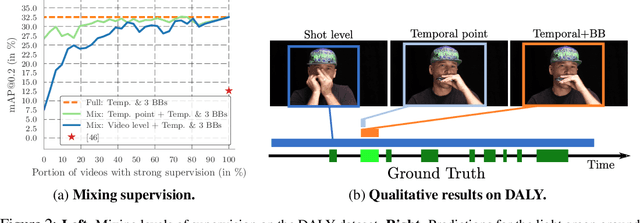
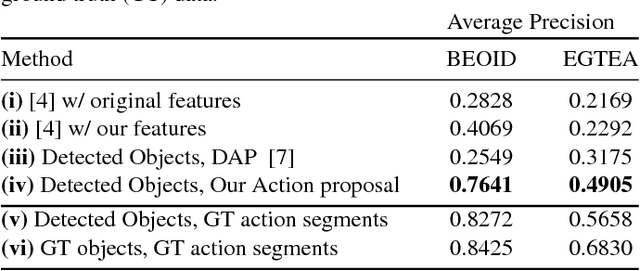
Spatio-temporal action detection in videos is typically addressed in a fully-supervised setup with manual annotation of training videos required at every frame. Since such annotation is extremely tedious and prohibits scalability, there is a clear need to minimize the amount of manual supervision. In this work we propose a unifying framework that can handle and combine varying types of less-demanding weak supervision. Our model is based on discriminative clustering and integrates different types of supervision as constraints on the optimization. We investigate applications of such a model to training setups with alternative supervisory signals ranging from video-level class labels over temporal points or sparse action bounding boxes to the full per-frame annotation of action bounding boxes. Experiments on the challenging UCF101-24 and DALY datasets demonstrate competitive performance of our method at a fraction of supervision used by previous methods. The flexibility of our model enables joint learning from data with different levels of annotation. Experimental results demonstrate a significant gain by adding a few fully supervised examples to otherwise weakly labeled videos.
SEARNN: Training RNNs with Global-Local Losses
Mar 04, 2018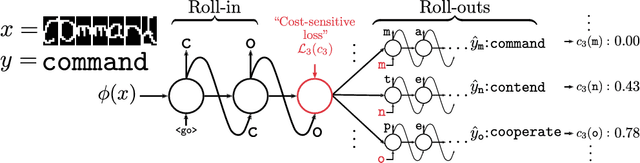
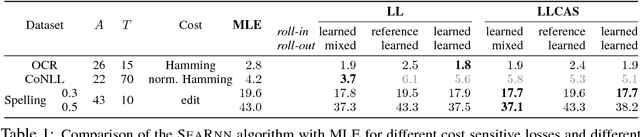

We propose SEARNN, a novel training algorithm for recurrent neural networks (RNNs) inspired by the "learning to search" (L2S) approach to structured prediction. RNNs have been widely successful in structured prediction applications such as machine translation or parsing, and are commonly trained using maximum likelihood estimation (MLE). Unfortunately, this training loss is not always an appropriate surrogate for the test error: by only maximizing the ground truth probability, it fails to exploit the wealth of information offered by structured losses. Further, it introduces discrepancies between training and predicting (such as exposure bias) that may hurt test performance. Instead, SEARNN leverages test-alike search space exploration to introduce global-local losses that are closer to the test error. We first demonstrate improved performance over MLE on two different tasks: OCR and spelling correction. Then, we propose a subsampling strategy to enable SEARNN to scale to large vocabulary sizes. This allows us to validate the benefits of our approach on a machine translation task.