 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Layered Image Decomposition into Object Prototypes
Apr 29, 2021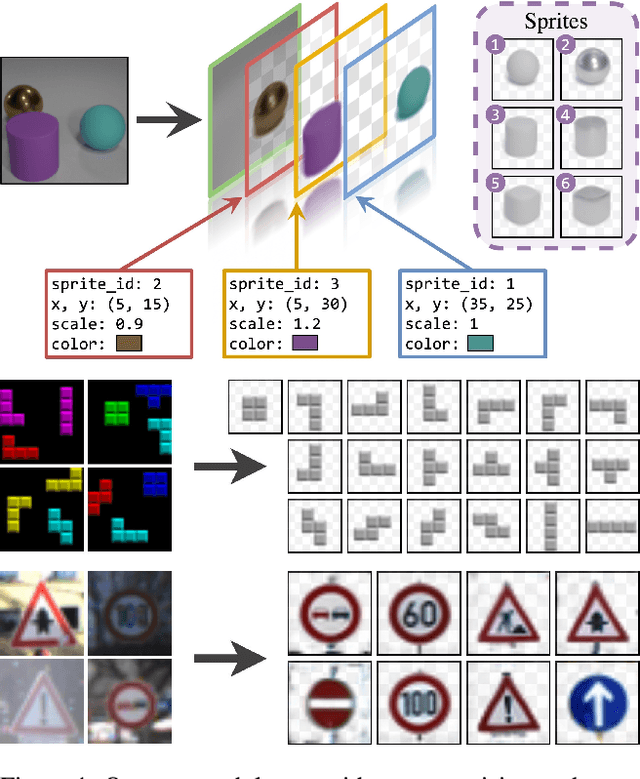
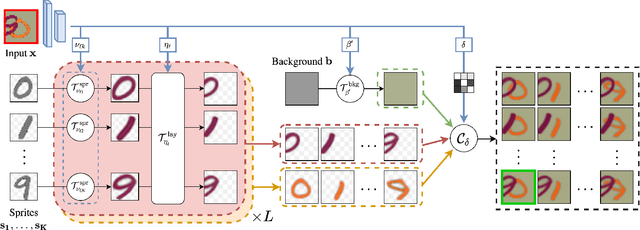

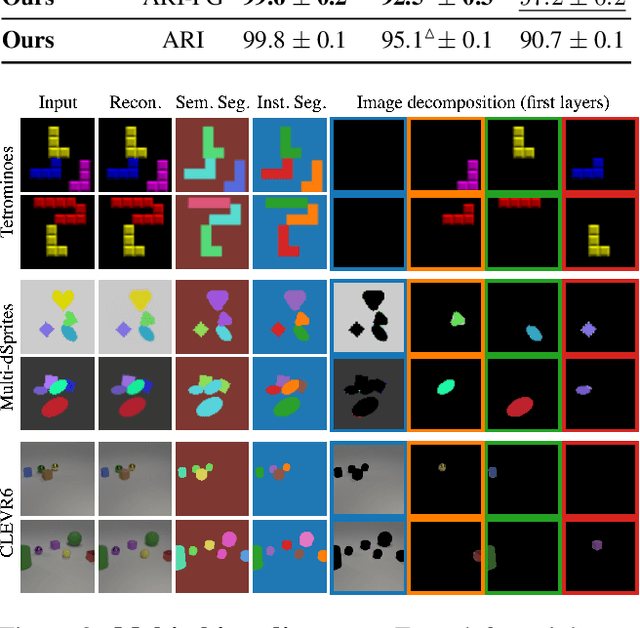
We present an unsupervised learning framework for decomposing images into layers of automatically discovered object models. Contrary to recent approaches that model image layers with autoencoder networks, we represent them as explicit transformations of a small set of prototypical images. Our model has three main components: (i) a set of object prototypes in the form of learnable images with a transparency channel, which we refer to as sprites; (ii) differentiable parametric functions predicting occlusions and transformation parameters necessary to instantiate the sprites in a given image; (iii) a layered image formation model with occlusion for compositing these instances into complete images including background. By jointly learning the sprites and occlusion/transformation predictors to reconstruct images, our approach not only yields accurate layered image decompositions, but also identifies object categories and instance parameters. We first validate our approach by providing results on par with the state of the art on standard multi-object synthetic benchmarks (Tetrominoes, Multi-dSprites, CLEVR6). We then demonstrate the applicability of our model to real images in tasks that include clustering (SVHN, GTSRB), cosegmentation (Weizmann Horse) and object discovery from unfiltered social network images. To the best of our knowledge, our approach is the first layered image decomposition algorithm that learns an explicit and shared concept of object type, and is robust enough to be applied to real images.
Learning to Jointly Deblur, Demosaick and Denoise Raw Images
Apr 13, 2021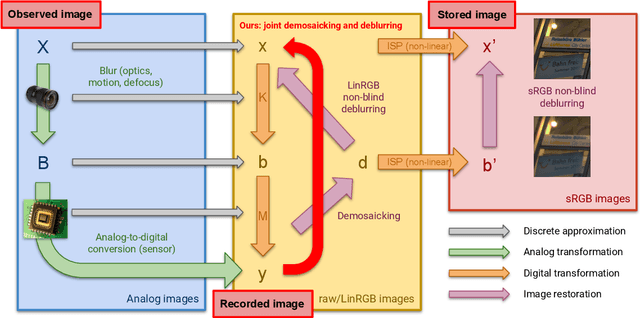
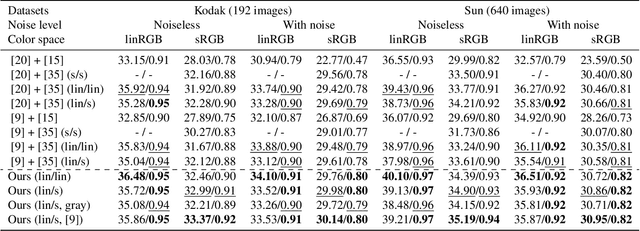
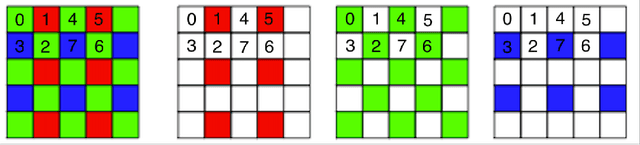
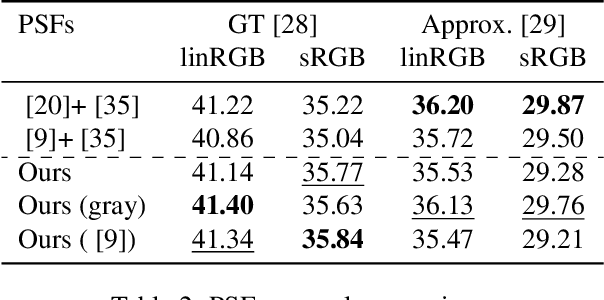
We address the problem of non-blind deblurring and demosaicking of noisy raw images. We adapt an existing learning-based approach to RGB image deblurring to handle raw images by introducing a new interpretable module that jointly demosaicks and deblurs them. We train this model on RGB images converted into raw ones following a realistic invertible camera pipeline. We demonstrate the effectiveness of this model over two-stage approaches stacking demosaicking and deblurring modules on quantitive benchmarks. We also apply our approach to remove a camera's inherent blur (its color-dependent point-spread function) from real images, in essence deblurring sharp images.
Aliasing is your Ally: End-to-End Super-Resolution from Raw Image Bursts
Apr 13, 2021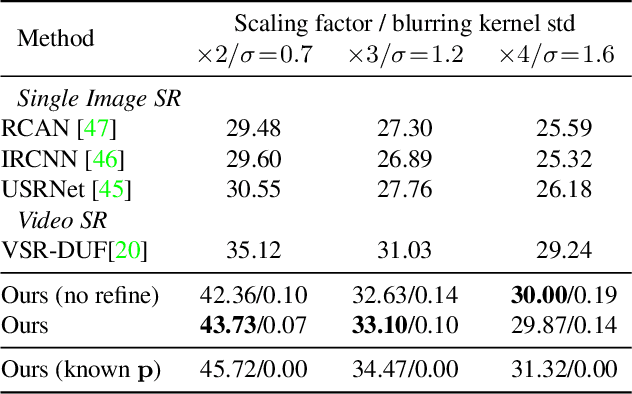

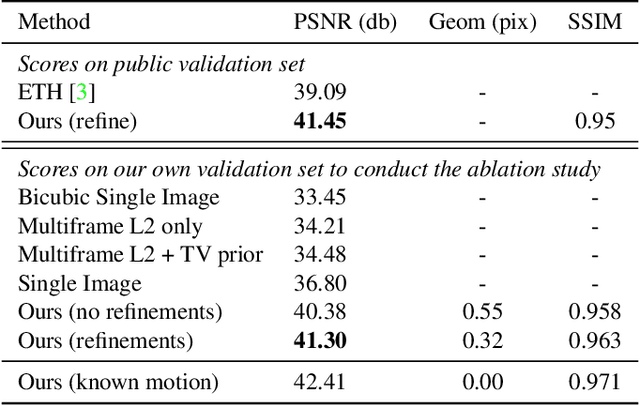

This presentation addresses the problem of reconstructing a high-resolution image from multiple lower-resolution snapshots captured from slightly different viewpoints in space and time. Key challenges for solving this problem include (i) aligning the input pictures with sub-pixel accuracy, (ii) handling raw (noisy) images for maximal faithfulness to native camera data, and (iii) designing/learning an image prior (regularizer) well suited to the task. We address these three challenges with a hybrid algorithm building on the insight from Wronski et al. that aliasing is an ally in this setting, with parameters that can be learned end to end, while retaining the interpretability of classical approaches to inverse problems. The effectiveness of our approach is demonstrated on synthetic and real image bursts, setting a new state of the art on several benchmarks and delivering excellent qualitative results on real raw bursts captured by smartphones and prosumer cameras.
Learning to Compose Hypercolumns for Visual Correspondence
Jul 21, 2020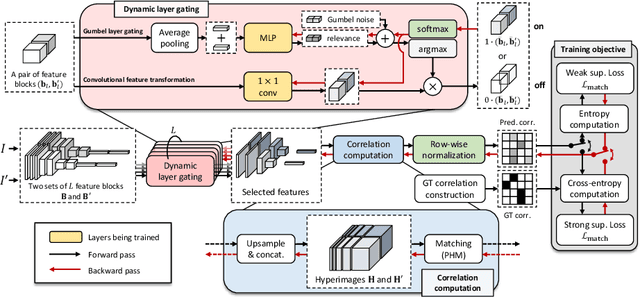
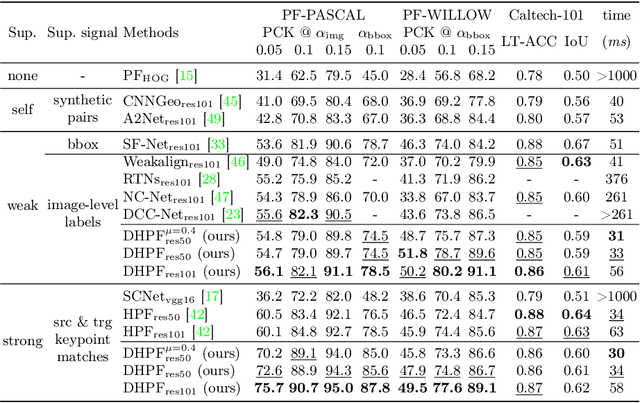
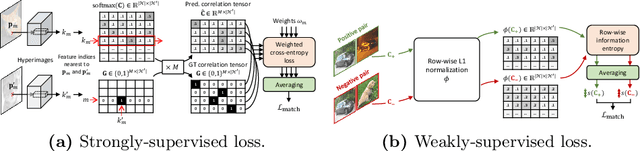
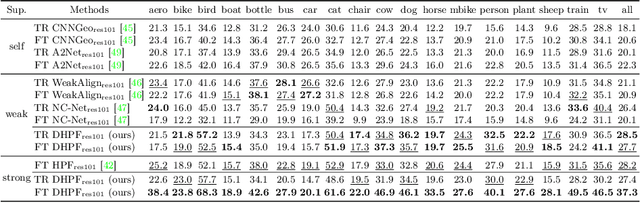
Feature representation plays a crucial role in visual correspondence, and recent methods for image matching resort to deeply stacked convolutional layers. These models, however, are both monolithic and static in the sense that they typically use a specific level of features, e.g., the output of the last layer, and adhere to it regardless of the images to match. In this work, we introduce a novel approach to visual correspondence that dynamically composes effective features by leveraging relevant layers conditioned on the images to match. Inspired by both multi-layer feature composition in object detection and adaptive inference architectures in classification, the proposed method, dubbed Dynamic Hyperpixel Flow, learns to compose hypercolumn features on the fly by selecting a small number of relevant layers from a deep convolutional neural network. We demonstrate the effectiveness on the task of semantic correspondence, i.e., establishing correspondences between images depicting different instances of the same object or scene category. Experiments on standard benchmarks show that the proposed method greatly improves matching performance over the state of the art in an adaptive and efficient manner.
Toward unsupervised, multi-object discovery in large-scale image collections
Jul 06, 2020

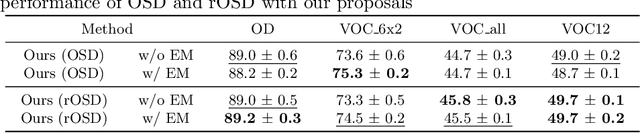
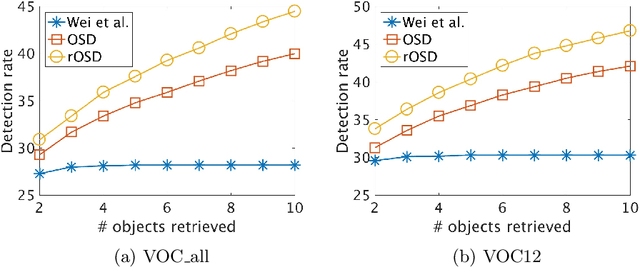
This paper addresses the problem of discovering the objects present in a collection of images without any supervision. We build on the optimization approach of Vo {\em et al.}~\cite{Vo2019UnsupOptim} with several key novelties: (1) We propose a novel saliency-based region proposal algorithm that achieves significantly higher overlap with ground-truth objects than other competitive methods. This procedure leverages off-the-shelf CNN features trained on classification tasks without any bounding box information, but is otherwise unsupervised. (2) We exploit the inherent hierarchical structure of proposals as an effective regularizer for the approach to object discovery of~\cite{Vo2019UnsupOptim}, boosting its performance to significantly improve over the state of the art on several standard benchmarks. (3) We adopt a two-stage strategy to select promising proposals using small random sets of images before using the whole image collection to discover the objects it depicts, allowing us to tackle, for the first time (to the best of our knowledge), the discovery of multiple objects in each one of the pictures making up datasets with up to 20,000 images, an over five-fold increase compared to existing methods, and a first step toward true large-scale unsupervised image interpretation.
End-to-end Interpretable Learning of Non-blind Image Deblurring
Jul 03, 2020

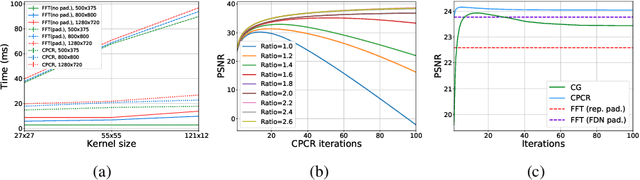

Non-blind image deblurring is typically formulated as a linear least-squares problem regularized by natural priors on the corresponding sharp picture's gradients, which can be solved, for example, using a half-quadratic splitting method with Richardson fixed-point iterations for its least-squares updates and a proximal operator for the auxiliary variable updates. We propose to precondition the Richardson solver using approximate inverse filters of the (known) blur and natural image prior kernels. Using convolutions instead of a generic linear preconditioner allows extremely efficient parameter sharing across the image, and leads to significant gains in accuracy and/or speed compared to classical FFT and conjugate-gradient methods. More importantly, the proposed architecture is easily adapted to learning both the preconditioner and the proximal operator using CNN embeddings. This yields a simple and efficient algorithm for non-blind image deblurring which is fully interpretable, can be learned end to end, and whose accuracy matches or exceeds the state of the art, quite significantly, in the non-uniform case.
Designing and Learning Trainable Priors with Non-Cooperative Games
Jun 26, 2020
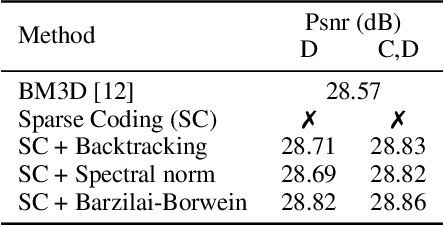
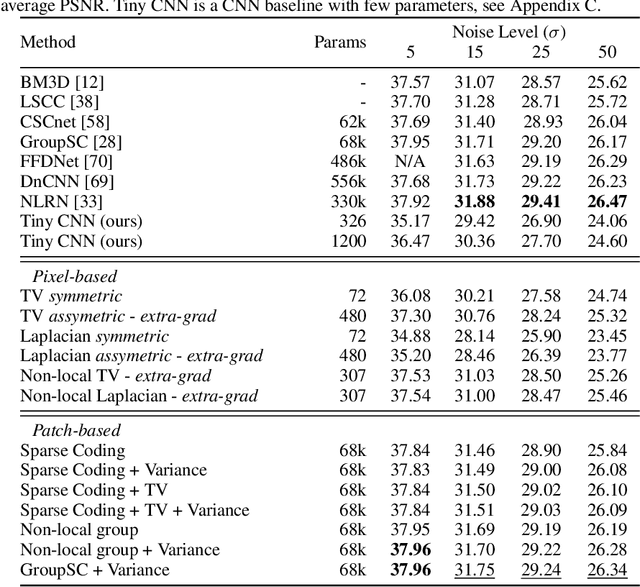
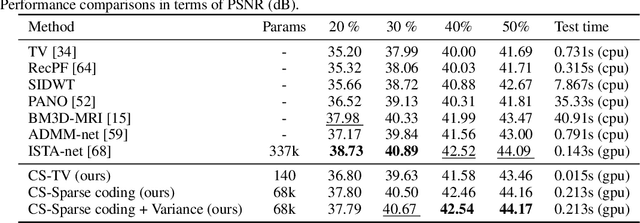
We introduce a general framework for designing and learning neural networks whose forward passes can be interpreted as solving convex optimization problems, and whose architectures are derived from an optimization algorithm. We focus on non-cooperative convex games, solved by local agents represented by the nodes of a graph and interacting through regularization functions. This approach is appealing for solving imaging problems, as it allows the use of classical image priors within deep models that are trainable end to end. The priors used in this presentation include variants of total variation, Laplacian regularization, sparse coding on learned dictionaries, and non-local self similarities. Our models are parameter efficient and fully interpretable, and our experiments demonstrate their effectiveness on a large diversity of tasks ranging from image denoising and compressed sensing for fMRI to dense stereo matching.
Structured and Localized Image Restoration
Jun 16, 2020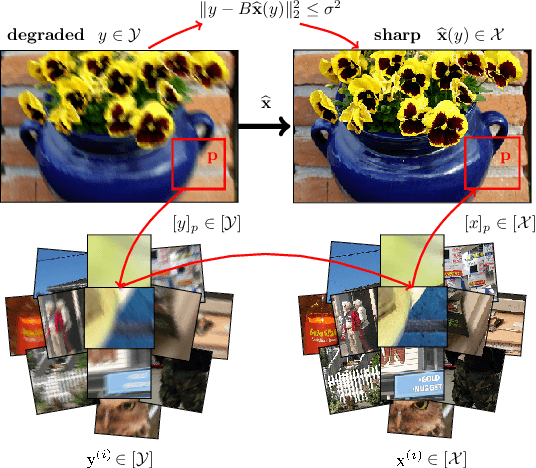


We present a novel approach to image restoration that leverages ideas from localized structured prediction and non-linear multi-task learning. We optimize a penalized energy function regularized by a sum of terms measuring the distance between patches to be restored and clean patches from an external database gathered beforehand. The resulting estimator comes with strong statistical guarantees leveraging local dependency properties of overlapping patches. We derive the corresponding algorithms for energies based on the mean-squared and Euclidean norm errors. Finally, we demonstrate the practical effectiveness of our model on different image restoration problems using standard benchmarks.
Revisiting Non Local Sparse Models for Image Restoration
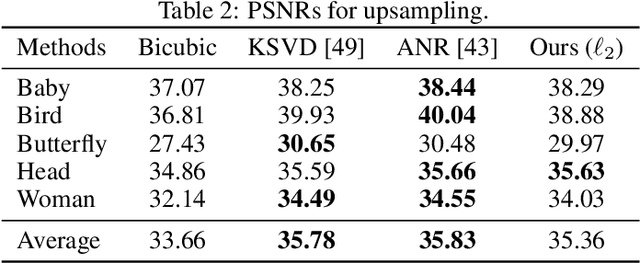
Jan 28, 2020


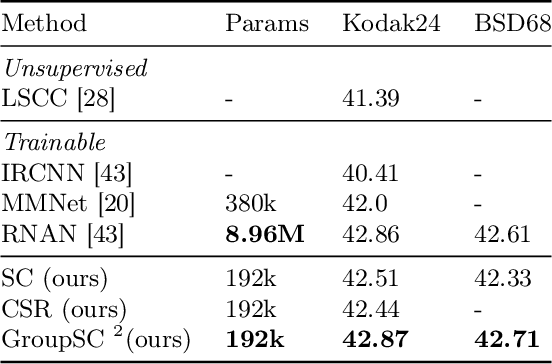
We propose a differentiable algorithm for image restoration inspired by the success of sparse models and self-similarity priors for natural images. Our approach builds upon the concept of joint sparsity between groups of similar image patches, and we show how this simple idea can be implemented in a differentiable architecture, allowing end-to-end training. The algorithm has the advantage of being interpretable, performing sparse decompositions of image patches, while being more parameter efficient than recent deep learning methods. We evaluate our algorithm on grayscale and color denoising, where we achieve competitive results, and on demoisaicking, where we outperform the most recent state-of-the-art deep learning model with 47 times less parameters and a much shallower architecture.
Learning Semantic Correspondence Exploiting an Object-level Prior
Nov 29, 2019
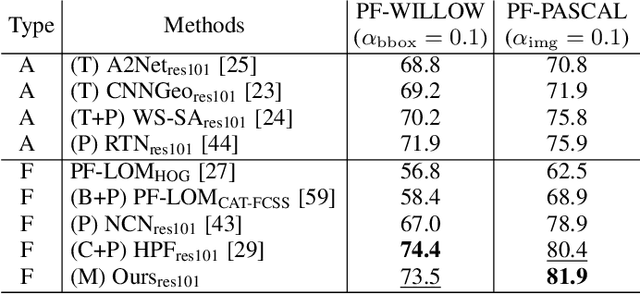
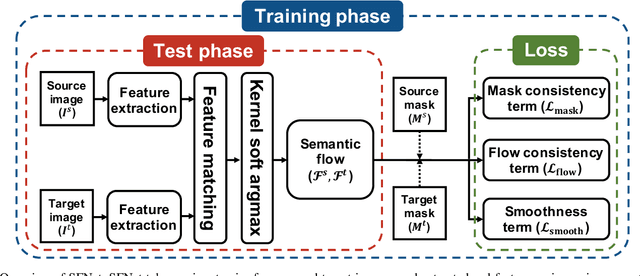

We address the problem of semantic correspondence, that is, establishing a dense flow field between images depicting different instances of the same object or scene category. We propose to use images annotated with binary foreground masks and subjected to synthetic geometric deformations to train a convolutional neural network (CNN) for this task. Using these masks as part of the supervisory signal provides an object-level prior for the semantic correspondence task and offers a good compromise between semantic flow methods, where the amount of training data is limited by the cost of manually selecting point correspondences, and semantic alignment ones, where the regression of a single global geometric transformation between images may be sensitive to image-specific details such as background clutter. We propose a new CNN architecture, dubbed SFNet, which implements this idea. It leverages a new and differentiable version of the argmax function for end-to-end training, with a loss that combines mask and flow consistency with smoothness terms. Experimental results demonstrate the effectiveness of our approach, which significantly outperforms the state of the art on standard benchmarks.