 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Speech Recognition from Federated Acoustic Models
Apr 29, 2021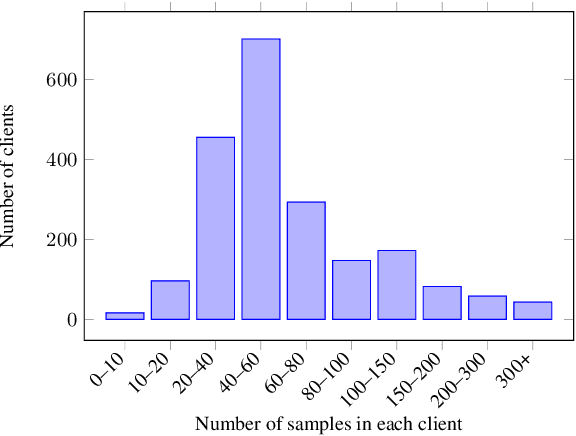

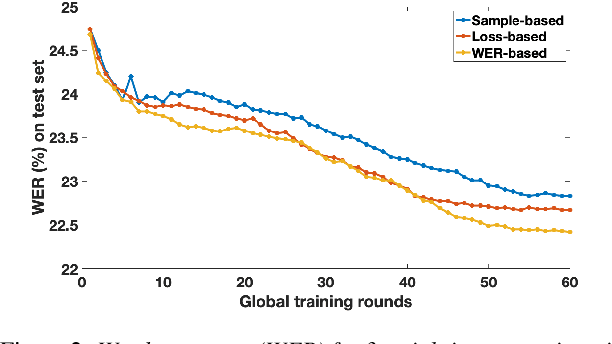
Training Automatic Speech Recognition (ASR) models under federated learning (FL) settings has recently attracted considerable attention. However, the FL scenarios often presented in the literature are artificial and fail to capture the complexity of real FL systems. In this paper, we construct a challenging and realistic ASR federated experimental setup consisting of clients with heterogeneous data distributions using the French Common Voice dataset, a large heterogeneous dataset containing over 10k speakers. We present the first empirical study on attention-based sequence-to-sequence E2E ASR model with three aggregation weighting strategies -- standard FedAvg, loss-based aggregation and a novel word error rate (WER)-based aggregation, are conducted in two realistic FL scenarios: cross-silo with 10-clients and cross-device with 2k-clients. In particular, the WER-based weighting method is proposed to better adapt FL to the context of ASR by integrating the error rate metric with the aggregation process. Our analysis on E2E ASR from heterogeneous and realistic federated acoustic models provides the foundations for future research and development of realistic FL-based ASR applications.
On-device Federated Learning with Flower
Apr 07, 2021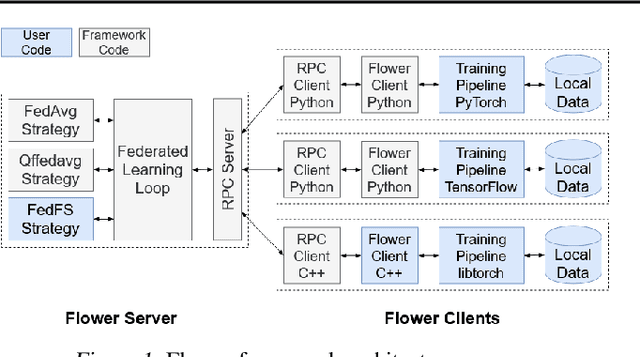
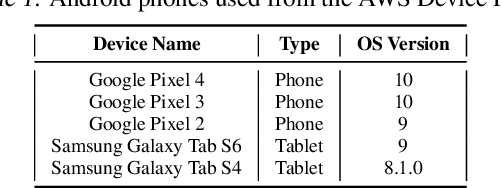
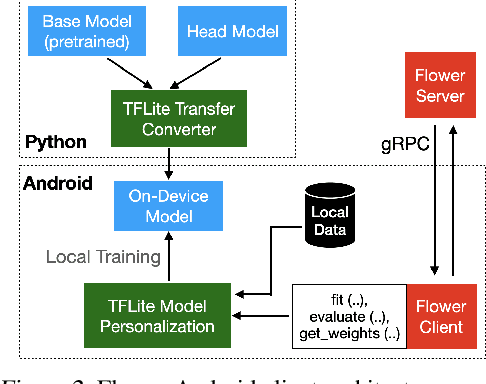

Federated Learning (FL) allows edge devices to collaboratively learn a shared prediction model while keeping their training data on the device, thereby decoupling the ability to do machine learning from the need to store data in the cloud. Despite the algorithmic advancements in FL, the support for on-device training of FL algorithms on edge devices remains poor. In this paper, we present an exploration of on-device FL on various smartphones and embedded devices using the Flower framework. We also evaluate the system costs of on-device FL and discuss how this quantification could be used to design more efficient FL algorithms.
* Accepted at the 2nd On-device Intelligence Workshop @ MLSys 2021. arXiv admin note: substantial text overlap with arXiv:2007.14390
unzipFPGA: Enhancing FPGA-based CNN Engines with On-the-Fly Weights Generation
Apr 03, 2021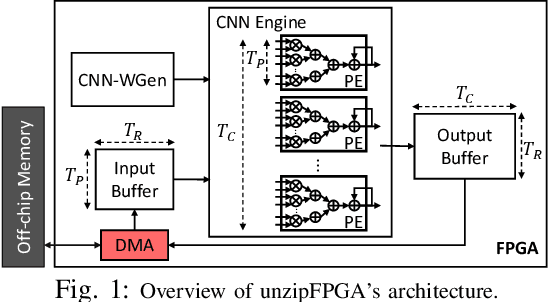
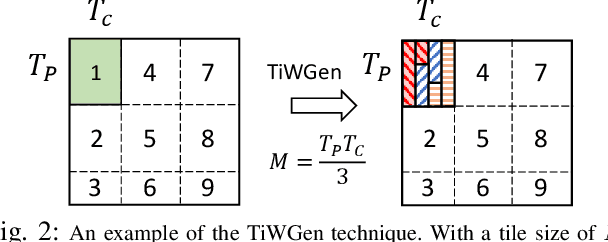
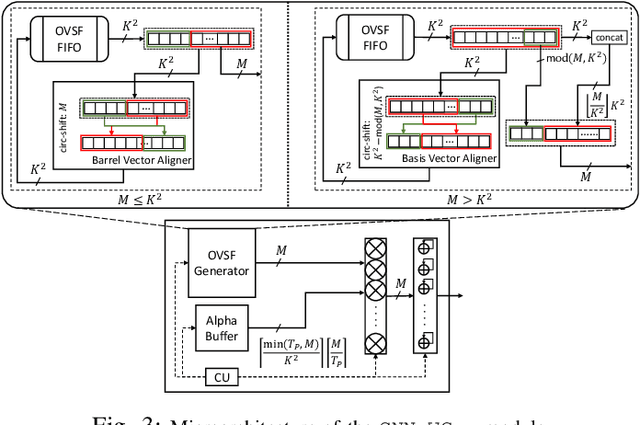
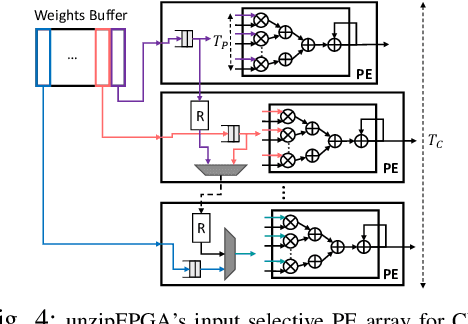
Single computation engines have become a popular design choice for FPGA-based convolutional neural networks (CNNs) enabling the deployment of diverse models without fabric reconfiguration. This flexibility, however, often comes with significantly reduced performance on memory-bound layers and resource underutilisation due to suboptimal mapping of certain layers on the engine's fixed configuration. In this work, we investigate the implications in terms of CNN engine design for a class of models that introduce a pre-convolution stage to decompress the weights at run time. We refer to these approaches as on-the-fly. To minimise the negative impact of limited bandwidth on memory-bound layers, we present a novel hardware component that enables the on-chip on-the-fly generation of weights. We further introduce an input selective processing element (PE) design that balances the load between PEs on suboptimally mapped layers. Finally, we present unzipFPGA, a framework to train on-the-fly models and traverse the design space to select the highest performing CNN engine configuration. Quantitative evaluation shows that unzipFPGA yields an average speedup of 2.14x and 71% over optimised status-quo and pruned CNN engines under constrained bandwidth and up to 3.69x higher performance density over the state-of-the-art FPGA-based CNN accelerators.
A first look into the carbon footprint of federated learning
Feb 15, 2021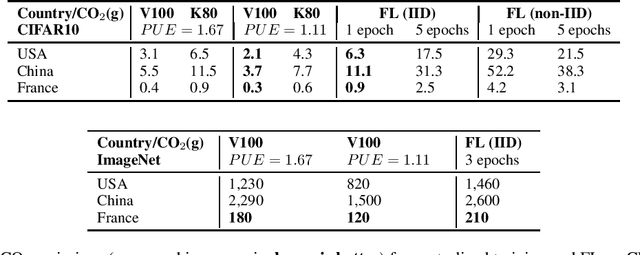
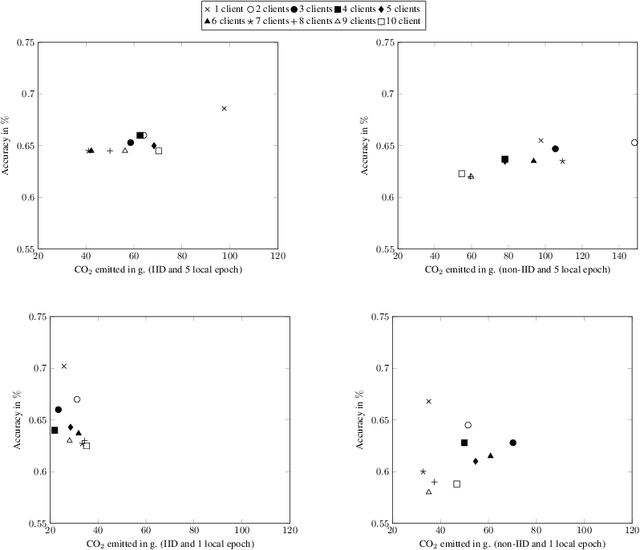
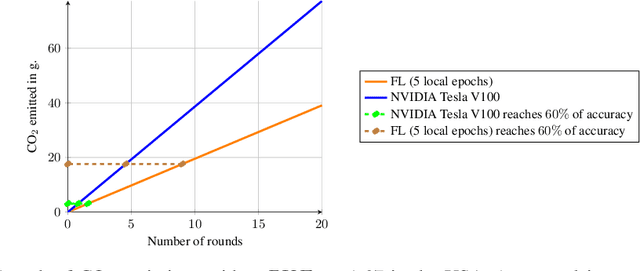
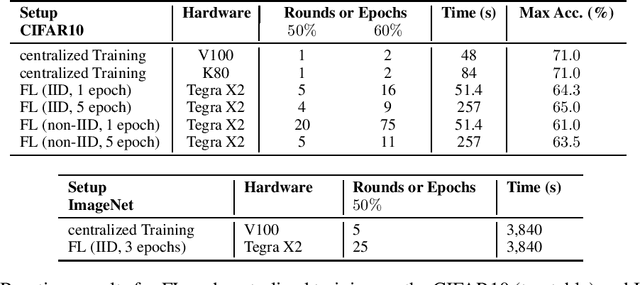
Despite impressive results, deep learning-based technologies also raise severe privacy and environmental concerns induced by the training procedure often conducted in datacenters. In response, alternatives to centralized training such as Federated Learning (FL) have emerged. Perhaps unexpectedly, FL, in particular, is starting to be deployed at a global scale by companies that must adhere to new legal demands and policies originating from governments and civil society for privacy protection. However, the potential environmental impact related to FL remains unclear and unexplored. This paper offers the first-ever systematic study of the carbon footprint of FL. First, we propose a rigorous model to quantify the carbon footprint, hence facilitating the investigation of the relationship between FL design and carbon emissions. Then, we compare the carbon footprint of FL to traditional centralized learning. Our findings show that FL, despite being slower to converge in some cases, may result in a comparatively greener impact than a centralized equivalent setup. We performed extensive experiments across different types of datasets, settings, and various deep learning models with FL. Finally, we highlight and connect the reported results to the future challenges and trends in FL to reduce its environmental impact, including algorithms efficiency, hardware capabilities, and stronger industry transparency.
Degree-Quant: Quantization-Aware Training for Graph Neural Networks
Aug 11, 2020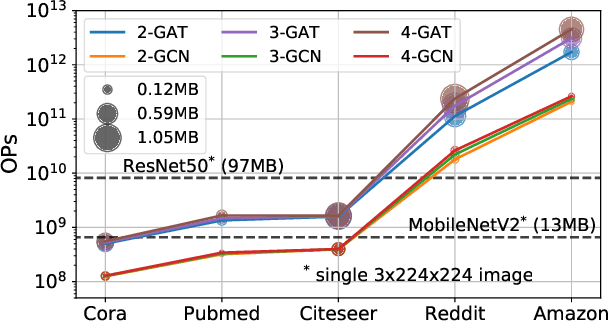
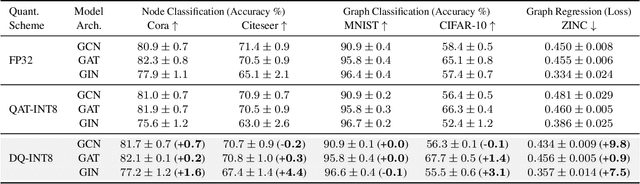
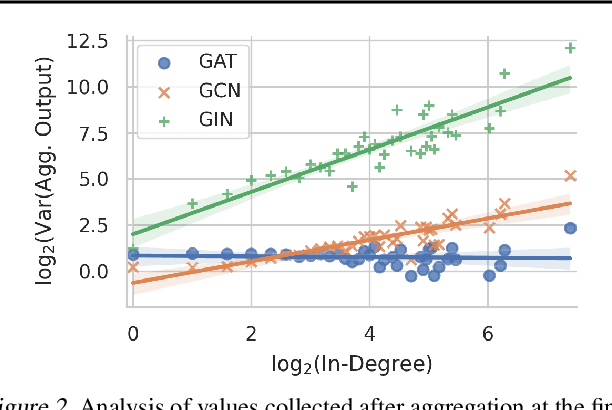
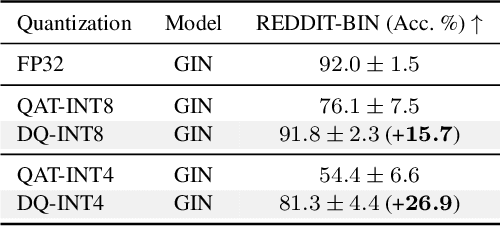
Graph neural networks (GNNs) have demonstrated strong performance on a wide variety of tasks due to their ability to model non-uniform structured data. Despite their promise, there exists little research exploring methods to make these architectures more efficient at inference time. In this work, we explore the viability of training quantized GNNs models, enabling the usage of low precision integer arithmetic during inference. We identify the sources of error that uniquely arise when attempting to quantize GNNs, and propose a method, Degree-Quant, to improve performance over existing quantization-aware training baselines commonly used on other architectures, such as CNNs. Models trained with Degree-Quant for INT8 quantization perform as well as FP32 models in most cases; for INT4 models, we obtain up to 69% gains over the baselines. Our work provides a comprehensive set of experiments across several datasets for node classification, graph classification and graph regression, laying strong foundations for future work in this area.
Searching for Winograd-aware Quantized Networks
Feb 25, 2020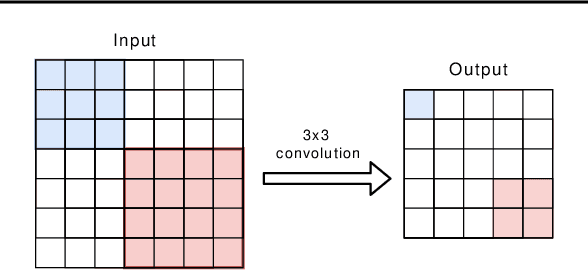
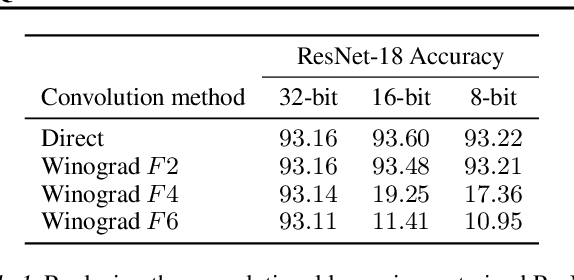
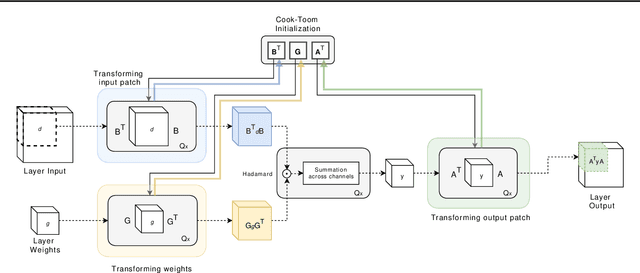
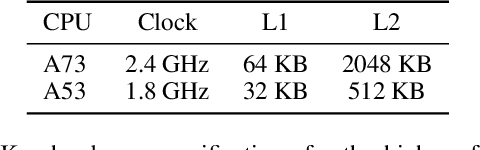
Lightweight architectural designs of Convolutional Neural Networks (CNNs) together with quantization have paved the way for the deployment of demanding computer vision applications on mobile devices. Parallel to this, alternative formulations to the convolution operation such as FFT, Strassen and Winograd, have been adapted for use in CNNs offering further speedups. Winograd convolutions are the fastest known algorithm for spatially small convolutions, but exploiting their full potential comes with the burden of numerical error, rendering them unusable in quantized contexts. In this work we propose a Winograd-aware formulation of convolution layers which exposes the numerical inaccuracies introduced by the Winograd transformations to the learning of the model parameters, enabling the design of competitive quantized models without impacting model size. We also address the source of the numerical error and propose a relaxation on the form of the transformation matrices, resulting in up to 10% higher classification accuracy on CIFAR-10. Finally, we propose wiNAS, a neural architecture search (NAS) framework that jointly optimizes a given macro-architecture for accuracy and latency leveraging Winograd-aware layers. A Winograd-aware ResNet-18 optimized with wiNAS for CIFAR-10 results in 2.66x speedup compared to im2row, one of the most widely used optimized convolution implementations, with no loss in accuracy.