 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent advancements in computational morphology : A comprehensive survey
Jun 08, 2024



Computational morphology handles the language processing at the word level. It is one of the foundational tasks in the NLP pipeline for the development of higher level NLP applications. It mainly deals with the processing of words and word forms. Computational Morphology addresses various sub problems such as morpheme boundary detection, lemmatization, morphological feature tagging, morphological reinflection etc. In this paper, we present exhaustive survey of the methods for developing computational morphology related tools. We survey the literature in the chronological order starting from the conventional methods till the recent evolution of deep neural network based approaches. We also review the existing datasets available for this task across the languages. We discuss about the effectiveness of neural model compared with the traditional models and present some unique challenges associated with building the computational morphology tools. We conclude by discussing some recent and open research issues in this field.
UniMorph 4.0: Universal Morphology
May 10, 2022



The Universal Morphology (UniMorph) project is a collaborative effort providing broad-coverage instantiated normalized morphological inflection tables for hundreds of diverse world languages. The project comprises two major thrusts: a language-independent feature schema for rich morphological annotation and a type-level resource of annotated data in diverse languages realizing that schema. This paper presents the expansions and improvements made on several fronts over the last couple of years (since McCarthy et al. (2020)). Collaborative efforts by numerous linguists have added 67 new languages, including 30 endangered languages. We have implemented several improvements to the extraction pipeline to tackle some issues, e.g. missing gender and macron information. We have also amended the schema to use a hierarchical structure that is needed for morphological phenomena like multiple-argument agreement and case stacking, while adding some missing morphological features to make the schema more inclusive. In light of the last UniMorph release, we also augmented the database with morpheme segmentation for 16 languages. Lastly, this new release makes a push towards inclusion of derivational morphology in UniMorph by enriching the data and annotation schema with instances representing derivational processes from MorphyNet.
Morpheme Boundary Detection & Grammatical Feature Prediction for Gujarati : Dataset & Model
Dec 18, 2021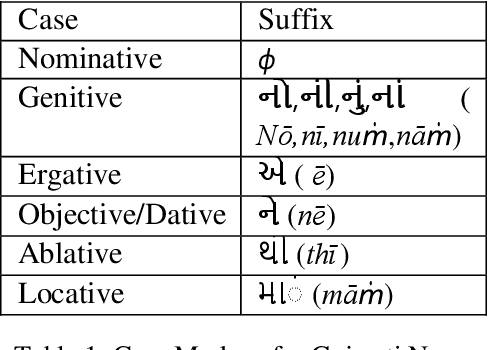
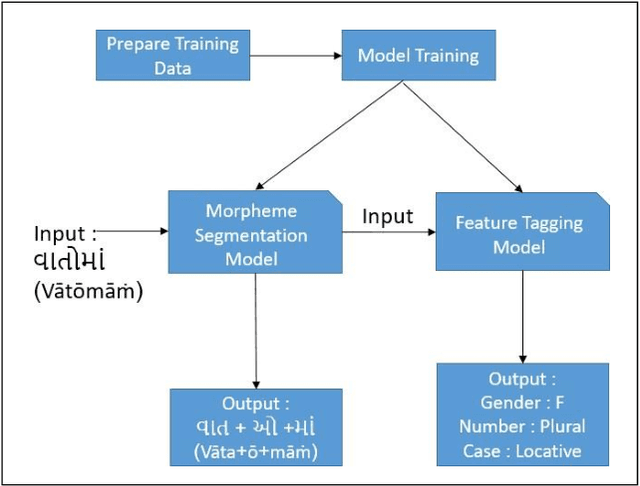
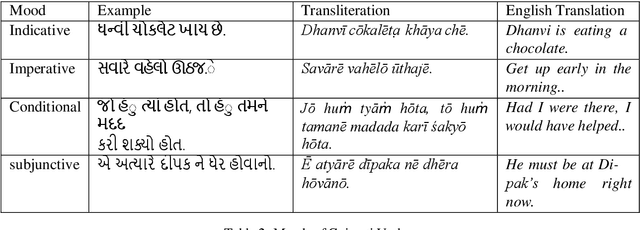
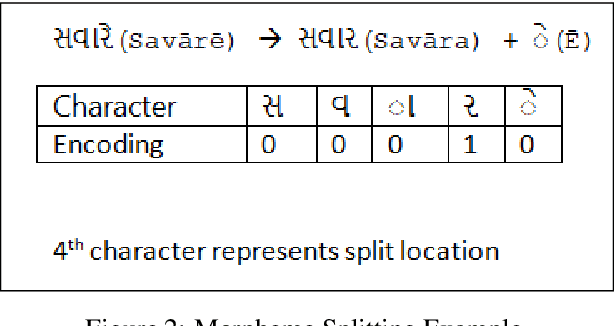
Developing Natural Language Processing resources for a low resource language is a challenging but essential task. In this paper, we present a Morphological Analyzer for Gujarati. We have used a Bi-Directional LSTM based approach to perform morpheme boundary detection and grammatical feature tagging. We have created a data set of Gujarati words with lemma and grammatical features. The Bi-LSTM based model of Morph Analyzer discussed in the paper handles the language morphology effectively without the knowledge of any hand-crafted suffix rules. To the best of our knowledge, this is the first dataset and morph analyzer model for the Gujarati language which performs both grammatical feature tagging and morpheme boundary detection tasks.