 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the Benefits of Model Ensembles in Neural Re-Ranking for Passage Retrieval
Jan 21, 2021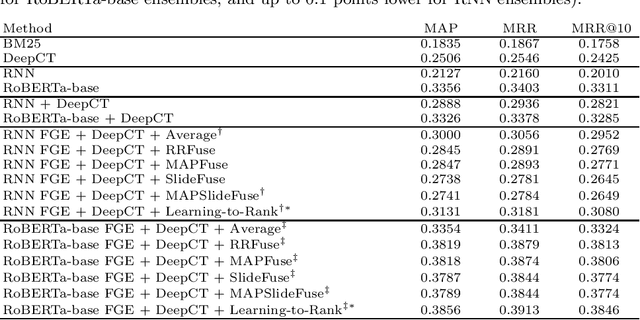
Our work aimed at experimentally assessing the benefits of model ensembling within the context of neural methods for passage reranking. Starting from relatively standard neural models, we use a previous technique named Fast Geometric Ensembling to generate multiple model instances from particular training schedules, then focusing or attention on different types of approaches for combining the results from the multiple model instances (e.g., averaging the ranking scores, using fusion methods from the IR literature, or using supervised learning-to-rank). Tests with the MS-MARCO dataset show that model ensembling can indeed benefit the ranking quality, particularly with supervised learning-to-rank although also with unsupervised rank aggregation.
PGT: Pseudo Relevance Feedback Using a Graph-Based Transformer
Jan 20, 2021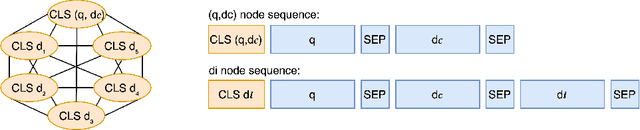
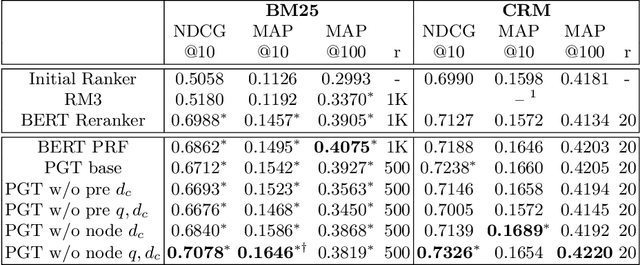
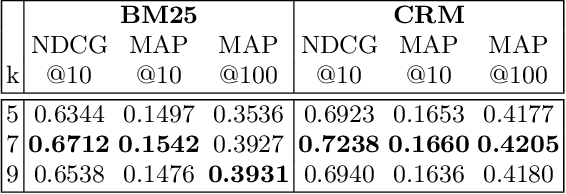
Most research on pseudo relevance feedback (PRF) has been done in vector space and probabilistic retrieval models. This paper shows that Transformer-based rerankers can also benefit from the extra context that PRF provides. It presents PGT, a graph-based Transformer that sparsifies attention between graph nodes to enable PRF while avoiding the high computational complexity of most Transformer architectures. Experiments show that PGT improves upon non-PRF Transformer reranker, and it is at least as accurate as Transformer PRF models that use full attention, but with lower computational costs.
Generating Categories for Sets of Entities
Aug 19, 2020
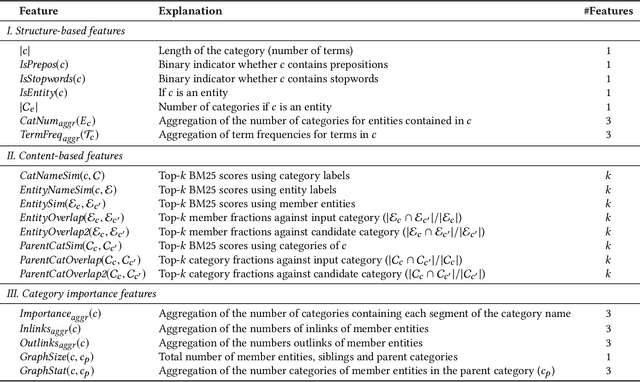
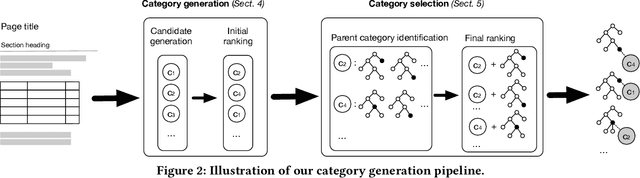

Category systems are central components of knowledge bases, as they provide a hierarchical grouping of semantically related concepts and entities. They are a unique and valuable resource that is utilized in a broad range of information access tasks. To aid knowledge editors in the manual process of expanding a category system, this paper presents a method of generating categories for sets of entities. First, we employ neural abstractive summarization models to generate candidate categories. Next, the location within the hierarchy is identified for each candidate. Finally, structure-, content-, and hierarchy-based features are used to rank candidates to identify by the most promising ones (measured in terms of specificity, hierarchy, and importance). We develop a test collection based on Wikipedia categories and demonstrate the effectiveness of the proposed approach.
Ranking Clarification Questions via Natural Language Inference
Aug 18, 2020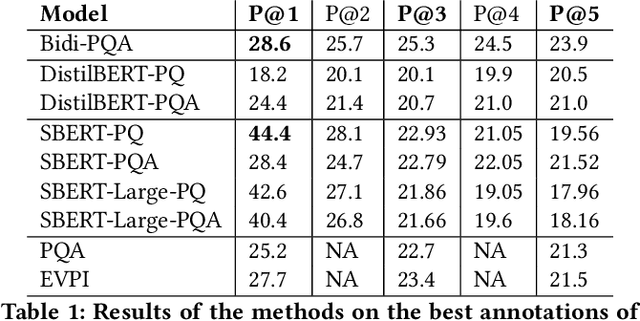
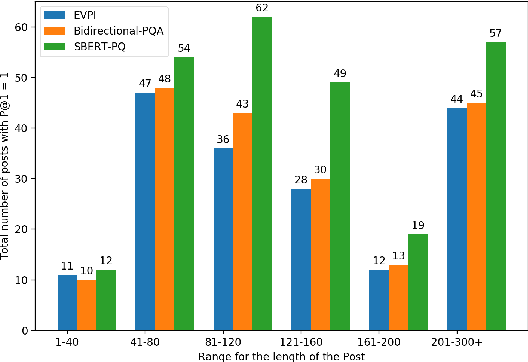
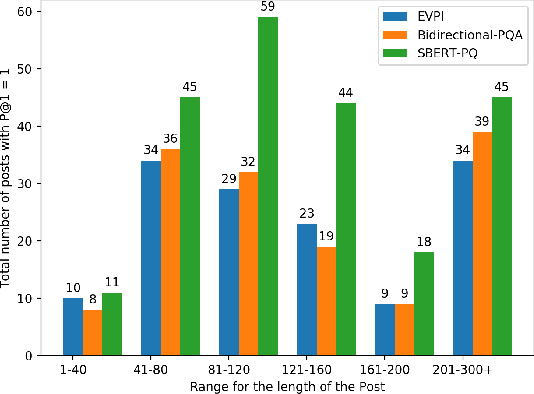
Given a natural language query, teaching machines to ask clarifying questions is of immense utility in practical natural language processing systems. Such interactions could help in filling information gaps for better machine comprehension of the query. For the task of ranking clarification questions, we hypothesize that determining whether a clarification question pertains to a missing entry in a given post (on QA forums such as StackExchange) could be considered as a special case of Natural Language Inference (NLI), where both the post and the most relevant clarification question point to a shared latent piece of information or context. We validate this hypothesis by incorporating representations from a Siamese BERT model fine-tuned on NLI and Multi-NLI datasets into our models and demonstrate that our best performing model obtains a relative performance improvement of 40 percent and 60 percent respectively (on the key metric of Precision@1), over the state-of-the-art baseline(s) on the two evaluation sets of the StackExchange dataset, thereby, significantly surpassing the state-of-the-art.
Understanding BERT Rankers Under Distillation
Jul 21, 2020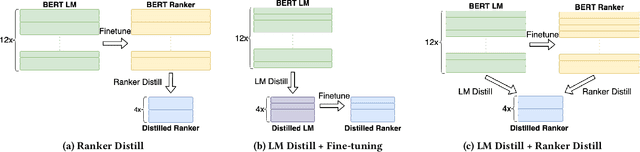
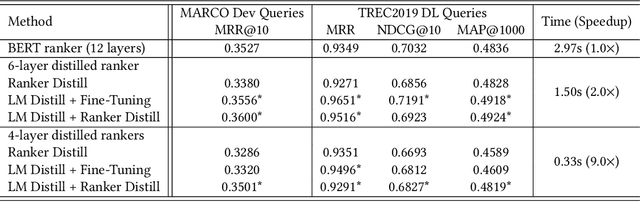
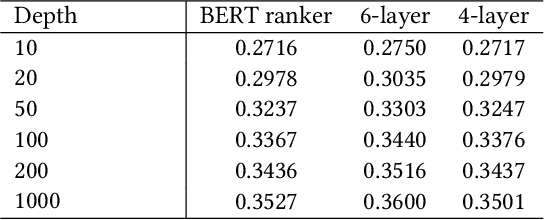
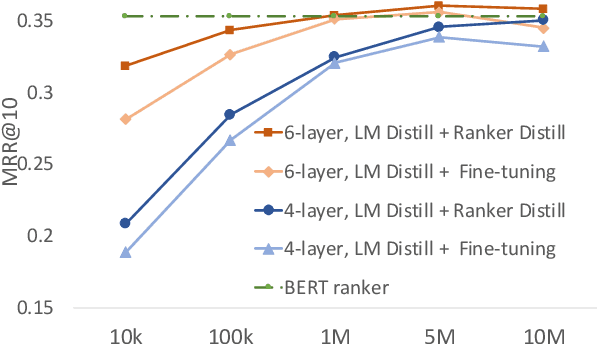
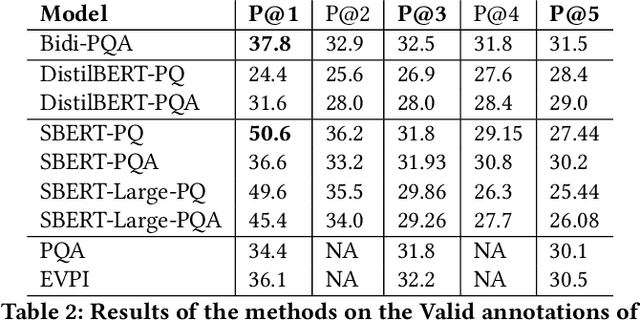
Deep language models such as BERT pre-trained on large corpus have given a huge performance boost to the state-of-the-art information retrieval ranking systems. Knowledge embedded in such models allows them to pick up complex matching signals between passages and queries. However, the high computation cost during inference limits their deployment in real-world search scenarios. In this paper, we study if and how the knowledge for search within BERT can be transferred to a smaller ranker through distillation. Our experiments demonstrate that it is crucial to use a proper distillation procedure, which produces up to nine times speedup while preserving the state-of-the-art performance.
Summarizing and Exploring Tabular Data in Conversational Search
May 23, 2020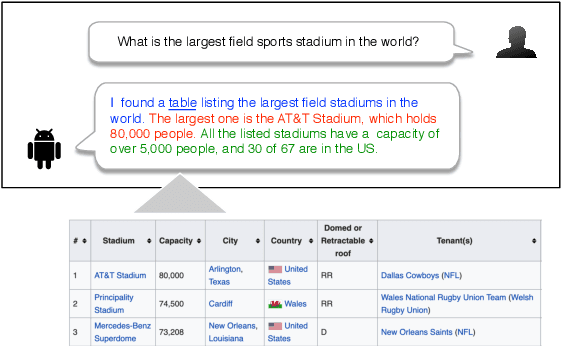

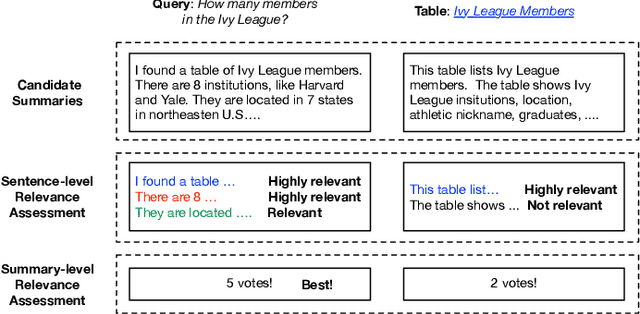

Tabular data provide answers to a significant portion of search queries. However, reciting an entire result table is impractical in conversational search systems. We propose to generate natural language summaries as answers to describe the complex information contained in a table. Through crowdsourcing experiments, we build a new conversation-oriented, open-domain table summarization dataset. It includes annotated table summaries, which not only answer questions but also help people explore other information in the table. We utilize this dataset to develop automatic table summarization systems as SOTA baselines. Based on the experimental results, we identify challenges and point out future research directions that this resource will support.
TREC CAsT 2019: The Conversational Assistance Track Overview
Mar 30, 2020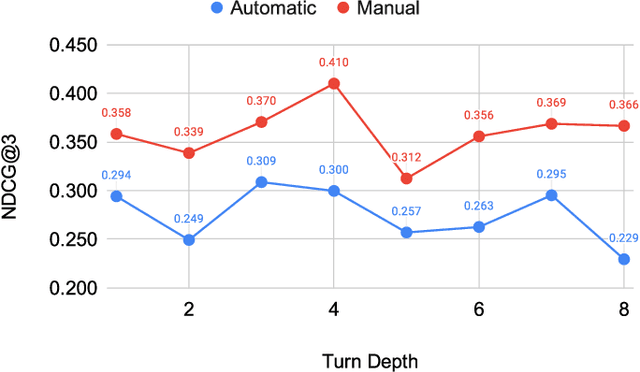
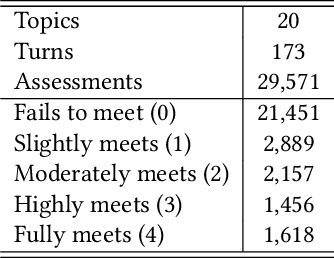
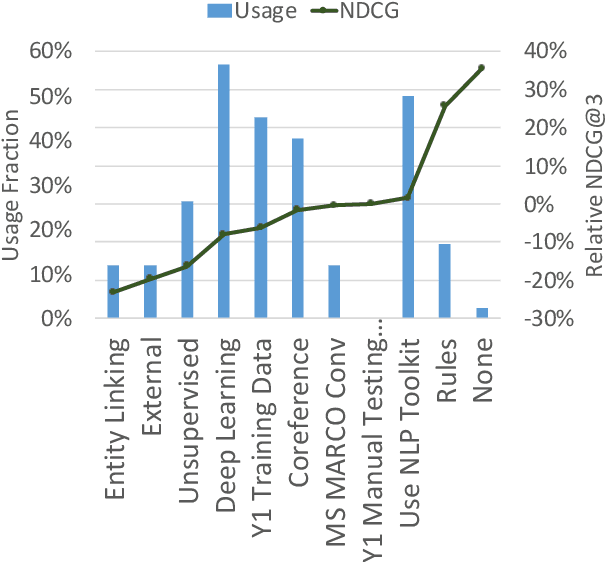
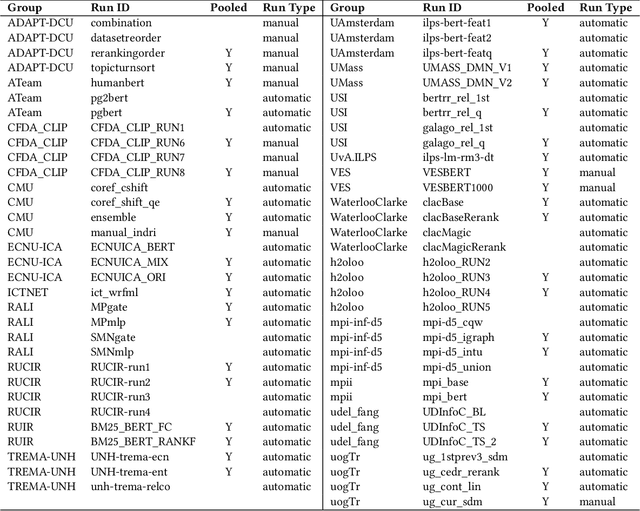
The Conversational Assistance Track (CAsT) is a new track for TREC 2019 to facilitate Conversational Information Seeking (CIS) research and to create a large-scale reusable test collection for conversational search systems. The document corpus is 38,426,252 passages from the TREC Complex Answer Retrieval (CAR) and Microsoft MAchine Reading COmprehension (MARCO) datasets. Eighty information seeking dialogues (30 train, 50 test) are an average of 9 to 10 questions long. Relevance assessments are provided for 30 training topics and 20 test topics. This year 21 groups submitted a total of 65 runs using varying methods for conversational query understanding and ranking. Methods include traditional retrieval based methods, feature based learning-to-rank, neural models, and knowledge enhanced methods. A common theme through the runs is the use of BERT-based neural reranking methods. Leading methods also employed document expansion, conversational query expansion, and generative language models for conversational query rewriting (GPT-2). The results show a gap between automatic systems and those using the manually resolved utterances, with a 35% relative improvement of manual rewrites over the best automatic system.
Deeper Text Understanding for IR with Contextual Neural Language Modeling
May 22, 2019

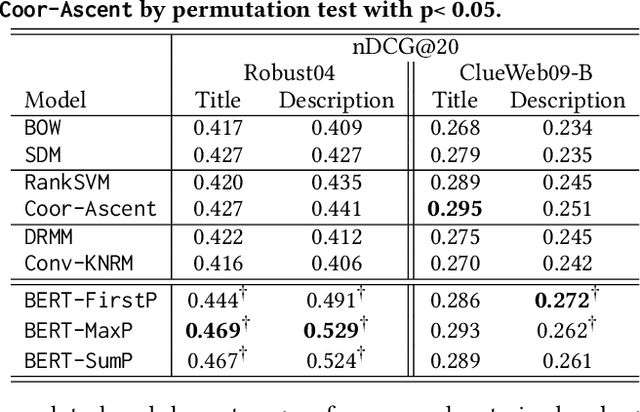
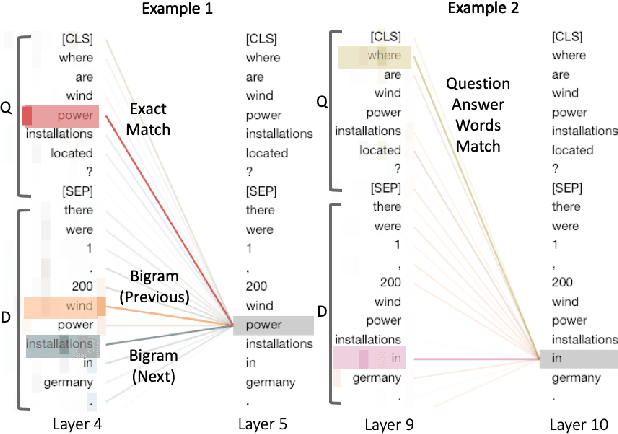
Neural networks provide new possibilities to automatically learn complex language patterns and query-document relations. Neural IR models have achieved promising results in learning query-document relevance patterns, but few explorations have been done on understanding the text content of a query or a document. This paper studies leveraging a recently-proposed contextual neural language model, BERT, to provide deeper text understanding for IR. Experimental results demonstrate that the contextual text representations from BERT are more effective than traditional word embeddings. Compared to bag-of-words retrieval models, the contextual language model can better leverage language structures, bringing large improvements on queries written in natural languages. Combining the text understanding ability with search knowledge leads to an enhanced pre-trained BERT model that can benefit related search tasks where training data are limited.
Consistency and Variation in Kernel Neural Ranking Model
Sep 27, 2018


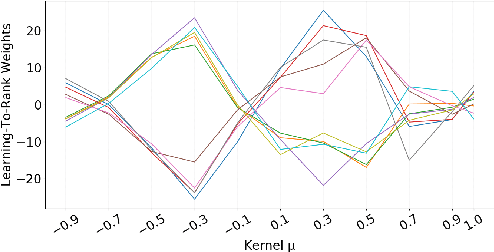
This paper studies the consistency of the kernel-based neural ranking model K-NRM, a recent state-of-the-art neural IR model, which is important for reproducible research and deployment in the industry. We find that K-NRM has low variance on relevance-based metrics across experimental trials. In spite of this low variance in overall performance, different trials produce different document rankings for individual queries. The main source of variance in our experiments was found to be different latent matching patterns captured by K-NRM. In the IR-customized word embeddings learned by K-NRM, the query-document word pairs follow two different matching patterns that are equally effective, but align word pairs differently in the embedding space. The different latent matching patterns enable a simple yet effective approach to construct ensemble rankers, which improve K-NRM's effectiveness and generalization abilities.
* 4 pages, 4 figures, 2 tables
Towards Better Text Understanding and Retrieval through Kernel Entity Salience Modeling
May 03, 2018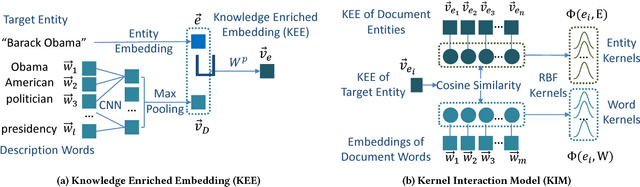
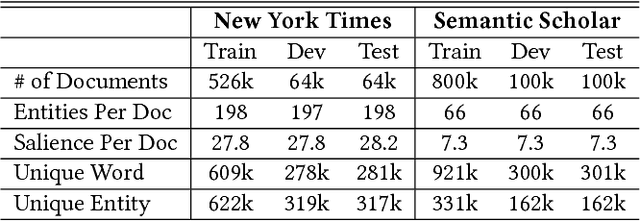
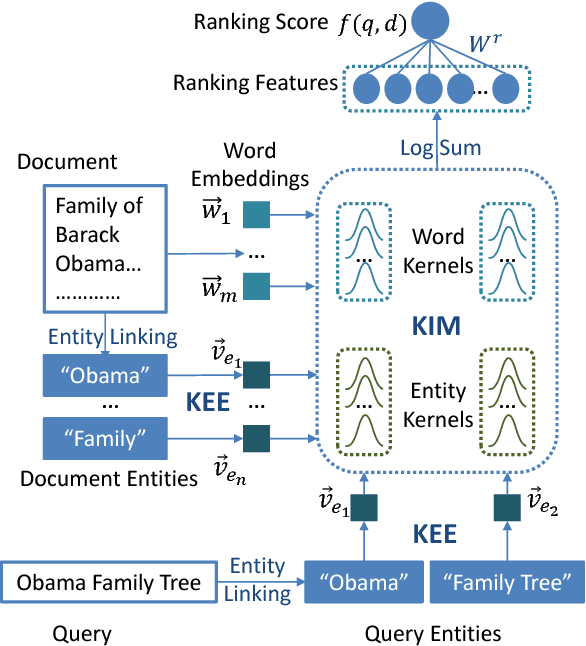

This paper presents a Kernel Entity Salience Model (KESM) that improves text understanding and retrieval by better estimating entity salience (importance) in documents. KESM represents entities by knowledge enriched distributed representations, models the interactions between entities and words by kernels, and combines the kernel scores to estimate entity salience. The whole model is learned end-to-end using entity salience labels. The salience model also improves ad hoc search accuracy, providing effective ranking features by modeling the salience of query entities in candidate documents. Our experiments on two entity salience corpora and two TREC ad hoc search datasets demonstrate the effectiveness of KESM over frequency-based and feature-based methods. We also provide examples showing how KESM conveys its text understanding ability learned from entity salience to search.