 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Neural Image Stitching With Enhanced and Blended Feature Reconstruction
Sep 12, 2023



Existing frameworks for image stitching often provide visually reasonable stitchings. However, they suffer from blurry artifacts and disparities in illumination, depth level, etc. Although the recent learning-based stitchings relax such disparities, the required methods impose sacrifice of image qualities failing to capture high-frequency details for stitched images. To address the problem, we propose a novel approach, implicit Neural Image Stitching (NIS) that extends arbitrary-scale super-resolution. Our method estimates Fourier coefficients of images for quality-enhancing warps. Then, the suggested model blends color mismatches and misalignment in the latent space and decodes the features into RGB values of stitched images. Our experiments show that our approach achieves improvement in resolving the low-definition imaging of the previous deep image stitching with favorable accelerated image-enhancing methods. Our source code is available at https://github.com/minshu-kim/NIS.
Semantic-Aware Implicit Template Learning via Part Deformation Consistency
Aug 23, 2023



Learning implicit templates as neural fields has recently shown impressive performance in unsupervised shape correspondence. Despite the success, we observe current approaches, which solely rely on geometric information, often learn suboptimal deformation across generic object shapes, which have high structural variability. In this paper, we highlight the importance of part deformation consistency and propose a semantic-aware implicit template learning framework to enable semantically plausible deformation. By leveraging semantic prior from a self-supervised feature extractor, we suggest local conditioning with novel semantic-aware deformation code and deformation consistency regularizations regarding part deformation, global deformation, and global scaling. Our extensive experiments demonstrate the superiority of the proposed method over baselines in various tasks: keypoint transfer, part label transfer, and texture transfer. More interestingly, our framework shows a larger performance gain under more challenging settings. We also provide qualitative analyses to validate the effectiveness of semantic-aware deformation. The code is available at https://github.com/mlvlab/PDC.
Chemical Property-Guided Neural Networks for Naphtha Composition Prediction
Jun 02, 2023



The naphtha cracking process heavily relies on the composition of naphtha, which is a complex blend of different hydrocarbons. Predicting the naphtha composition accurately is crucial for efficiently controlling the cracking process and achieving maximum performance. Traditional methods, such as gas chromatography and true boiling curve, are not feasible due to the need for pilot-plant-scale experiments or cost constraints. In this paper, we propose a neural network framework that utilizes chemical property information to improve the performance of naphtha composition prediction. Our proposed framework comprises two parts: a Watson K factor estimation network and a naphtha composition prediction network. Both networks share a feature extraction network based on Convolutional Neural Network (CNN) architecture, while the output layers use Multi-Layer Perceptron (MLP) based networks to generate two different outputs - Watson K factor and naphtha composition. The naphtha composition is expressed in percentages, and its sum should be 100%. To enhance the naphtha composition prediction, we utilize a distillation simulator to obtain the distillation curve from the naphtha composition, which is dependent on its chemical properties. By designing a loss function between the estimated and simulated Watson K factors, we improve the performance of both Watson K estimation and naphtha composition prediction. The experimental results show that our proposed framework can predict the naphtha composition accurately while reflecting real naphtha chemical properties.
Semantic-aware Occlusion Filtering Neural Radiance Fields in the Wild
Mar 05, 2023



We present a learning framework for reconstructing neural scene representations from a small number of unconstrained tourist photos. Since each image contains transient occluders, decomposing the static and transient components is necessary to construct radiance fields with such in-the-wild photographs where existing methods require a lot of training data. We introduce SF-NeRF, aiming to disentangle those two components with only a few images given, which exploits semantic information without any supervision. The proposed method contains an occlusion filtering module that predicts the transient color and its opacity for each pixel, which enables the NeRF model to solely learn the static scene representation. This filtering module learns the transient phenomena guided by pixel-wise semantic features obtained by a trainable image encoder that can be trained across multiple scenes to learn the prior of transient objects. Furthermore, we present two techniques to prevent ambiguous decomposition and noisy results of the filtering module. We demonstrate that our method outperforms state-of-the-art novel view synthesis methods on Phototourism dataset in a few-shot setting.
Robust Camera Pose Refinement for Multi-Resolution Hash Encoding
Feb 03, 2023



Multi-resolution hash encoding has recently been proposed to reduce the computational cost of neural renderings, such as NeRF. This method requires accurate camera poses for the neural renderings of given scenes. However, contrary to previous methods jointly optimizing camera poses and 3D scenes, the naive gradient-based camera pose refinement method using multi-resolution hash encoding severely deteriorates performance. We propose a joint optimization algorithm to calibrate the camera pose and learn a geometric representation using efficient multi-resolution hash encoding. Showing that the oscillating gradient flows of hash encoding interfere with the registration of camera poses, our method addresses the issue by utilizing smooth interpolation weighting to stabilize the gradient oscillation for the ray samplings across hash grids. Moreover, the curriculum training procedure helps to learn the level-wise hash encoding, further increasing the pose refinement. Experiments on the novel-view synthesis datasets validate that our learning frameworks achieve state-of-the-art performance and rapid convergence of neural rendering, even when initial camera poses are unknown.
Domain Generalization Emerges from Dreaming
Feb 02, 2023



Recent studies have proven that DNNs, unlike human vision, tend to exploit texture information rather than shape. Such texture bias is one of the factors for the poor generalization performance of DNNs. We observe that the texture bias negatively affects not only in-domain generalization but also out-of-distribution generalization, i.e., Domain Generalization. Motivated by the observation, we propose a new framework to reduce the texture bias of a model by a novel optimization-based data augmentation, dubbed Stylized Dream. Our framework utilizes adaptive instance normalization (AdaIN) to augment the style of an original image yet preserve the content. We then adopt a regularization loss to predict consistent outputs between Stylized Dream and original images, which encourages the model to learn shape-based representations. Extensive experiments show that the proposed method achieves state-of-the-art performance in out-of-distribution settings on public benchmark datasets: PACS, VLCS, OfficeHome, TerraIncognita, and DomainNet.
Learning Local Implicit Fourier Representation for Image Warping
Jul 05, 2022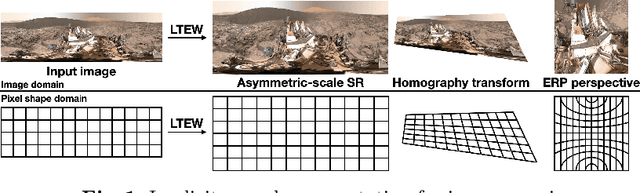
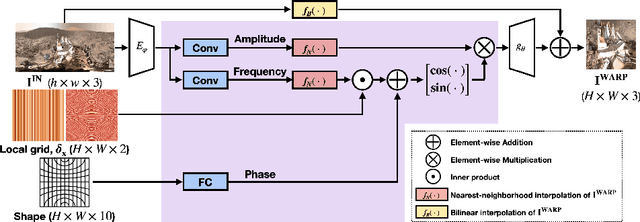
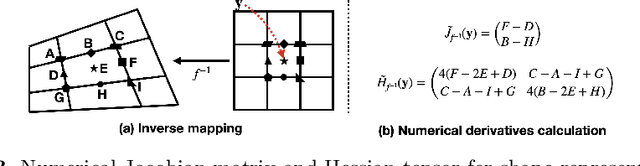
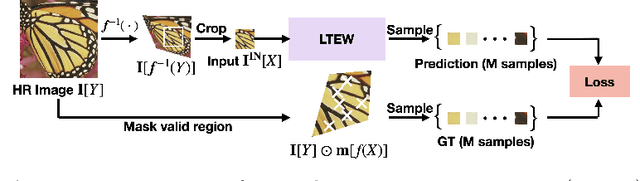
Image warping aims to reshape images defined on rectangular grids into arbitrary shapes. Recently, implicit neural functions have shown remarkable performances in representing images in a continuous manner. However, a standalone multi-layer perceptron suffers from learning high-frequency Fourier coefficients. In this paper, we propose a local texture estimator for image warping (LTEW) followed by an implicit neural representation to deform images into continuous shapes. Local textures estimated from a deep super-resolution (SR) backbone are multiplied by locally-varying Jacobian matrices of a coordinate transformation to predict Fourier responses of a warped image. Our LTEW-based neural function outperforms existing warping methods for asymmetric-scale SR and homography transform. Furthermore, our algorithm well generalizes arbitrary coordinate transformations, such as homography transform with a large magnification factor and equirectangular projection (ERP) perspective transform, which are not provided in training.
Building a Performance Model for Deep Learning Recommendation Model Training on GPUs
Jan 19, 2022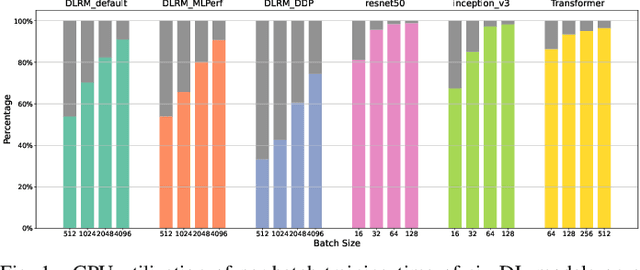
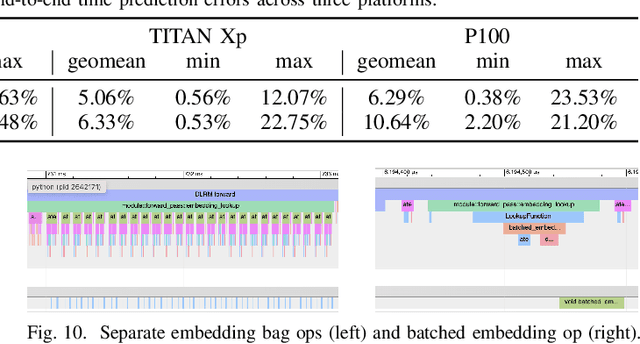

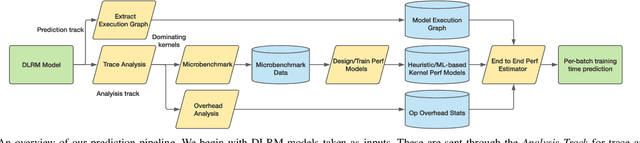
We devise a performance model for GPU training of Deep Learning Recommendation Models (DLRM), whose GPU utilization is low compared to other well-optimized CV and NLP models. We show that both the device active time (the sum of kernel runtimes) and the device idle time are important components of the overall device time. We therefore tackle them separately by (1) flexibly adopting heuristic-based and ML-based kernel performance models for operators that dominate the device active time, and (2) categorizing operator overheads into five types to determine quantitatively their contribution to the device active time. Combining these two parts, we propose a critical-path-based algorithm to predict the per-batch training time of DLRM by traversing its execution graph. We achieve less than 10% geometric mean average error (GMAE) in all kernel performance modeling, and 5.23% and 7.96% geomean errors for GPU active time and overall end-to-end per-batch training time prediction, respectively. We show that our general performance model not only achieves low prediction error on DLRM, which has highly customized configurations and is dominated by multiple factors, but also yields comparable accuracy on other compute-bound ML models targeted by most previous methods. Using this performance model and graph-level data and task dependency analyses, we show our system can provide more general model-system co-design than previous methods.
Local Texture Estimator for Implicit Representation Function
Nov 21, 2021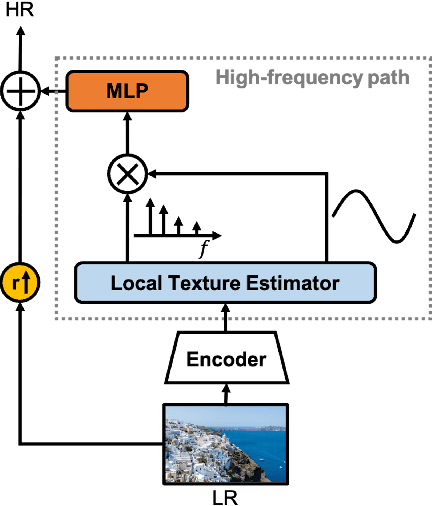
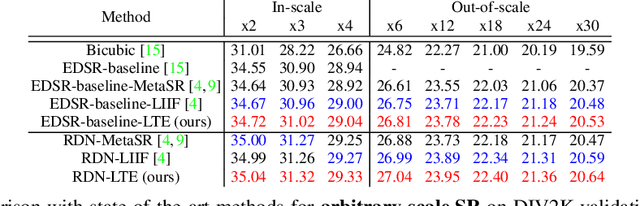
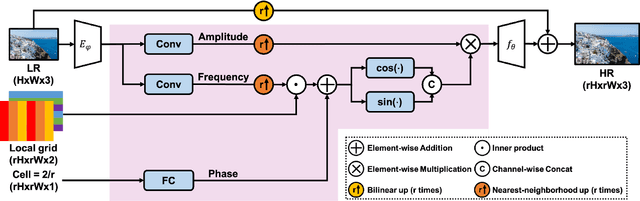

Recent works with an implicit neural function shed light on representing images in arbitrary resolution. However, a standalone multi-layer perceptron (MLP) shows limited performance in learning high-frequency components. In this paper, we propose a Local Texture Estimator (LTE), a dominant-frequency estimator for natural images, enabling an implicit function to capture fine details while reconstructing images in a continuous manner. When jointly trained with a deep super-resolution (SR) architecture, LTE is capable of characterizing image textures in 2D Fourier space. We show that an LTE-based neural function outperforms existing deep SR methods within an arbitrary-scale for all datasets and all scale factors. Furthermore, we demonstrate that our implementation takes the shortest running time compared to previous works. Source code will be open.
Point Cloud Augmentation with Weighted Local Transformations
Oct 11, 2021
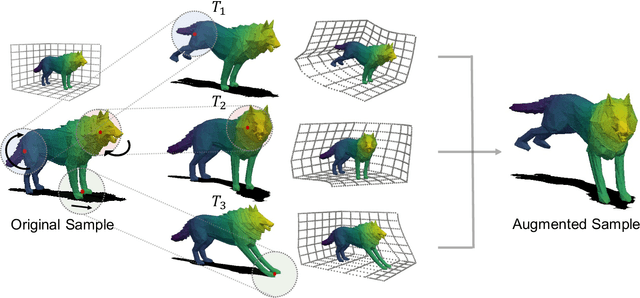
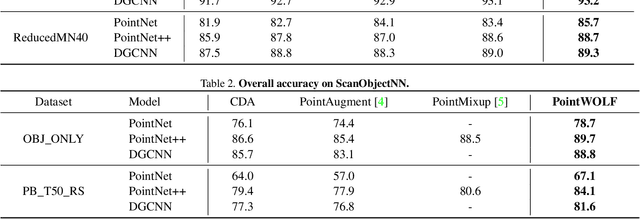
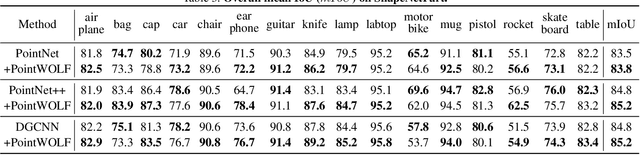
Despite the extensive usage of point clouds in 3D vision, relatively limited data are available for training deep neural networks. Although data augmentation is a standard approach to compensate for the scarcity of data, it has been less explored in the point cloud literature. In this paper, we propose a simple and effective augmentation method called PointWOLF for point cloud augmentation. The proposed method produces smoothly varying non-rigid deformations by locally weighted transformations centered at multiple anchor points. The smooth deformations allow diverse and realistic augmentations. Furthermore, in order to minimize the manual efforts to search the optimal hyperparameters for augmentation, we present AugTune, which generates augmented samples of desired difficulties producing targeted confidence scores. Our experiments show our framework consistently improves the performance for both shape classification and part segmentation tasks. Particularly, with PointNet++, PointWOLF achieves the state-of-the-art 89.7 accuracy on shape classification with the real-world ScanObjectNN dataset.