 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Refinement of Flow Matching with Divergence-based Sampling
Apr 06, 2026Flow-based models learn a target distribution by modeling a marginal velocity field, defined as the average of sample-wise velocities connecting each sample from a simple prior to the target data. When sample-wise velocities conflict at the same intermediate state, however, this averaged velocity can misguide samples toward low-density regions, degrading generation quality. To address this issue, we propose the Flow Divergence Sampler (FDS), a training-free framework that refines intermediate states before each solver step. Our key finding reveals that the severity of this misguidance is quantified by the divergence of the marginal velocity field that is readily computable during inference with a well-optimized model. FDS exploits this signal to steer states toward less ambiguous regions. As a plug-and-play framework compatible with standard solvers and off-the-shelf flow backbones, FDS consistently improves fidelity across various generation tasks including text-to-image synthesis, and inverse problems.
FlowBind: Efficient Any-to-Any Generation with Bidirectional Flows
Dec 17, 2025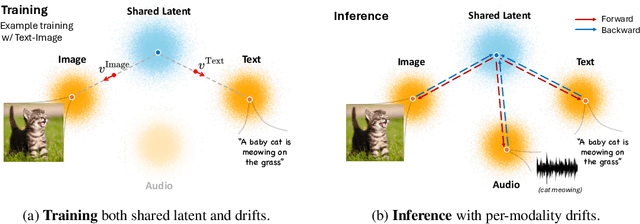

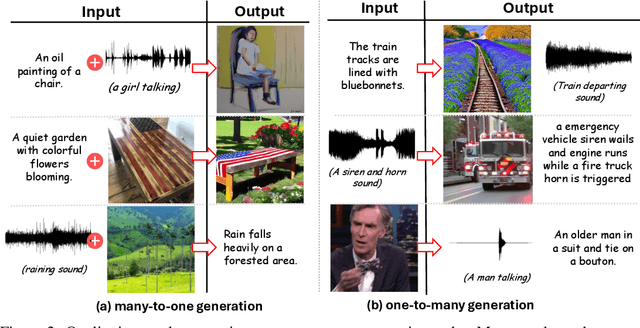
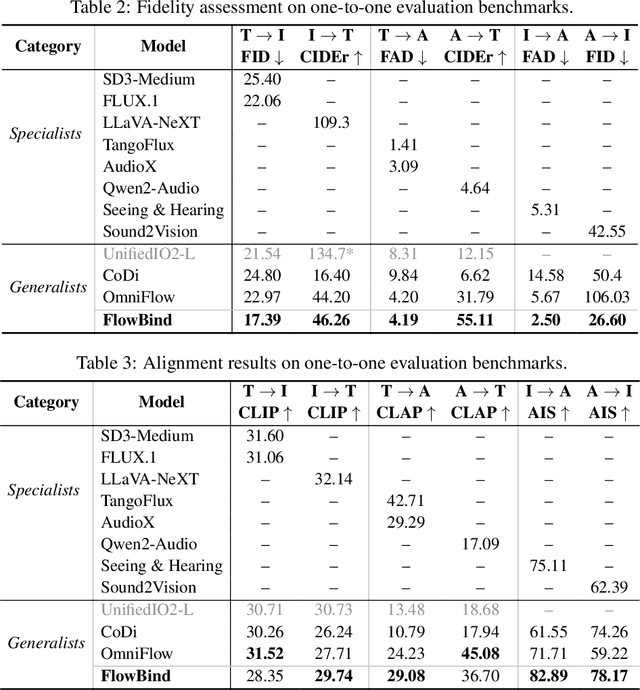
Any-to-any generation seeks to translate between arbitrary subsets of modalities, enabling flexible cross-modal synthesis. Despite recent success, existing flow-based approaches are challenged by their inefficiency, as they require large-scale datasets often with restrictive pairing constraints, incur high computational cost from modeling joint distribution, and rely on complex multi-stage training. We propose FlowBind, an efficient framework for any-to-any generation. Our approach is distinguished by its simplicity: it learns a shared latent space capturing cross-modal information, with modality-specific invertible flows bridging this latent to each modality. Both components are optimized jointly under a single flow-matching objective, and at inference the invertible flows act as encoders and decoders for direct translation across modalities. By factorizing interactions through the shared latent, FlowBind naturally leverages arbitrary subsets of modalities for training, and achieves competitive generation quality while substantially reducing data requirements and computational cost. Experiments on text, image, and audio demonstrate that FlowBind attains comparable quality while requiring up to 6x fewer parameters and training 10x faster than prior methods. The project page with code is available at https://yeonwoo378.github.io/official_flowbind.