 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Future World Events with Neural Networks
Jun 30, 2022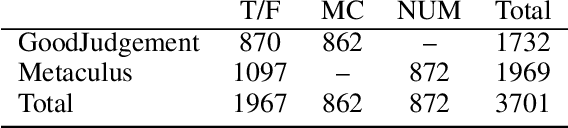
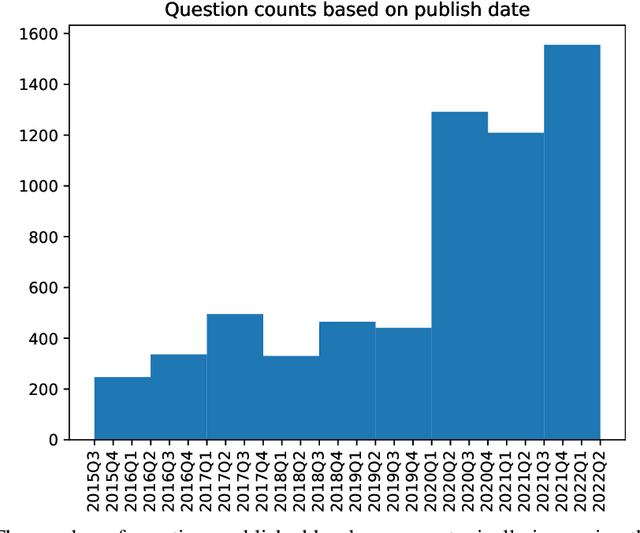
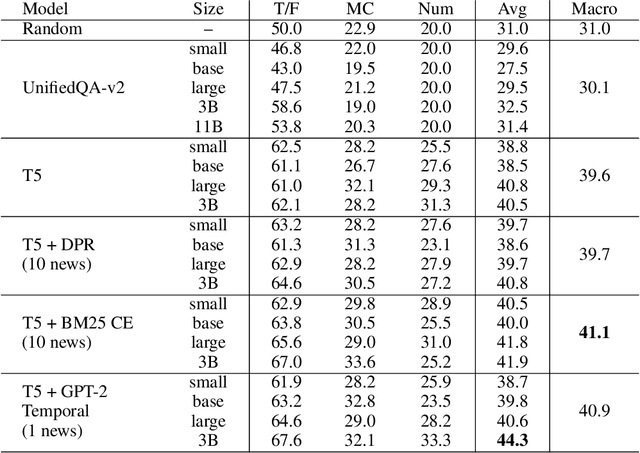

Forecasting future world events is a challenging but valuable task. Forecasts of climate, geopolitical conflict, pandemics and economic indicators help shape policy and decision making. In these domains, the judgment of expert humans contributes to the best forecasts. Given advances in language modeling, can these forecasts be automated? To this end, we introduce Autocast, a dataset containing thousands of forecasting questions and an accompanying news corpus. Questions are taken from forecasting tournaments, ensuring high quality, real-world importance, and diversity. The news corpus is organized by date, allowing us to precisely simulate the conditions under which humans made past forecasts (avoiding leakage from the future). Motivated by the difficulty of forecasting numbers across orders of magnitude (e.g. global cases of COVID-19 in 2022), we also curate IntervalQA, a dataset of numerical questions and metrics for calibration. We test language models on our forecasting task and find that performance is far below a human expert baseline. However, performance improves with increased model size and incorporation of relevant information from the news corpus. In sum, Autocast poses a novel challenge for large language models and improved performance could bring large practical benefits.
Auditing Visualizations: Transparency Methods Struggle to Detect Anomalous Behavior
Jun 27, 2022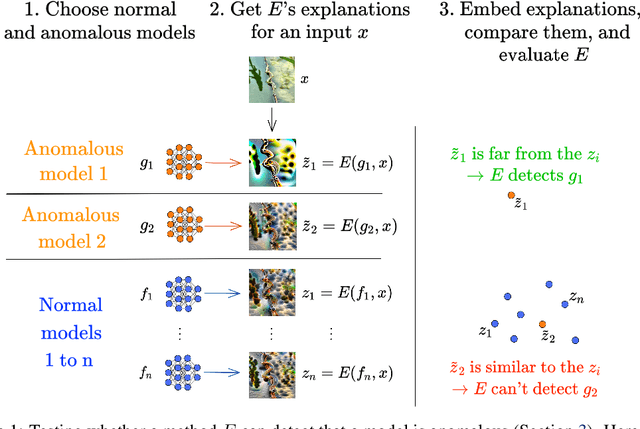

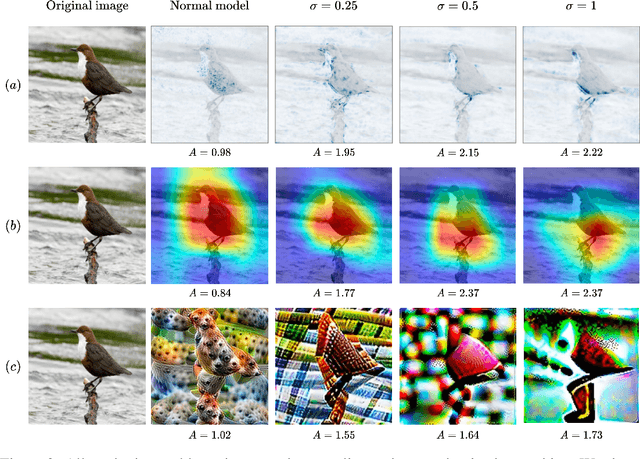
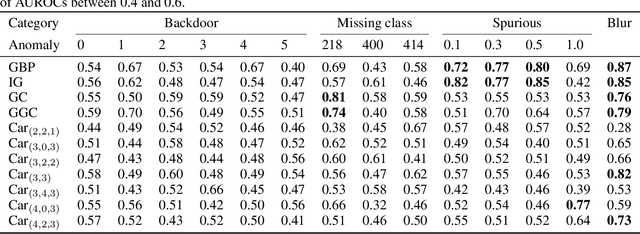
Transparency methods such as model visualizations provide information that outputs alone might miss, since they describe the internals of neural networks. But can we trust that model explanations reflect model behavior? For instance, can they diagnose abnormal behavior such as backdoors or shape bias? To evaluate model explanations, we define a model as anomalous if it differs from a reference set of normal models, and we test whether transparency methods assign different explanations to anomalous and normal models. We find that while existing methods can detect stark anomalies such as shape bias or adversarial training, they struggle to identify more subtle anomalies such as models trained on incomplete data. Moreover, they generally fail to distinguish the inputs that induce anomalous behavior, e.g. images containing a backdoor trigger. These results reveal new blind spots in existing model explanations, pointing to the need for further method development.
Supply-Side Equilibria in Recommender Systems
Jun 27, 2022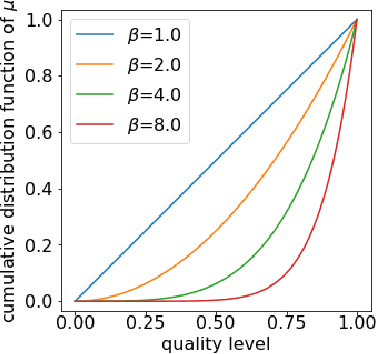
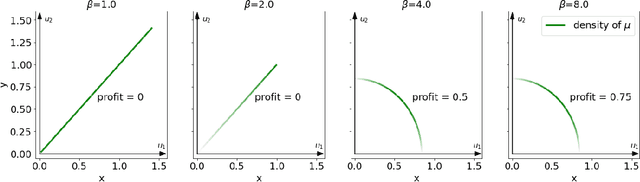
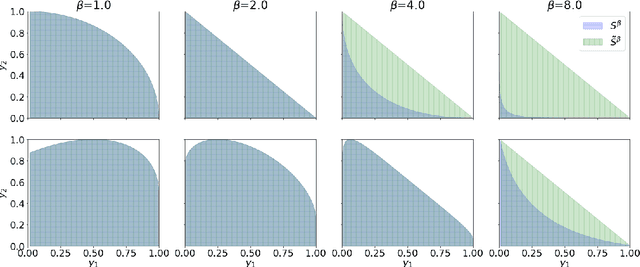
Digital recommender systems such as Spotify and Netflix affect not only consumer behavior but also producer incentives: producers seek to supply content that will be recommended by the system. But what content will be produced? In this paper, we investigate the supply-side equilibria in content recommender systems. We model users and content as $D$-dimensional vectors, and recommend the content that has the highest dot product with each user. The main features of our model are that the producer decision space is high-dimensional and the user base is heterogeneous. This gives rise to new qualitative phenomena at equilibrium: First, the formation of genres, where producers specialize to compete for subsets of users. Using a duality argument, we derive necessary and sufficient conditions for this specialization to occur. Second, we show that producers can achieve positive profit at equilibrium, which is typically impossible under perfect competition. We derive sufficient conditions for this to occur, and show it is closely connected to specialization of content. In both results, the interplay between the geometry of the users and the structure of producer costs influences the structure of the supply-side equilibria. At a conceptual level, our work serves as a starting point to investigate how recommender systems shape supply-side competition between producers.
More Than a Toy: Random Matrix Models Predict How Real-World Neural Representations Generalize
Mar 11, 2022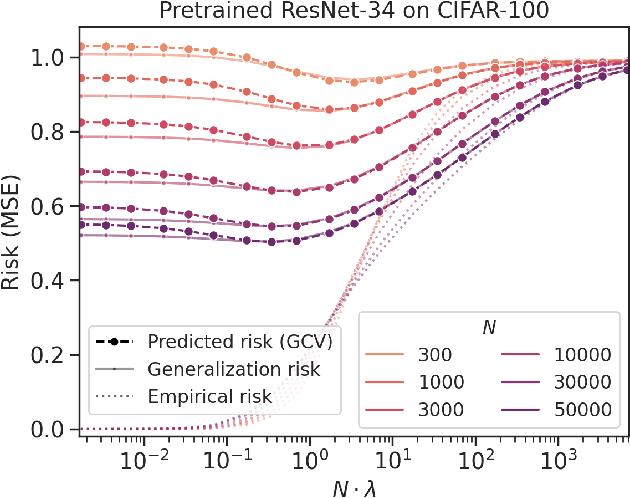
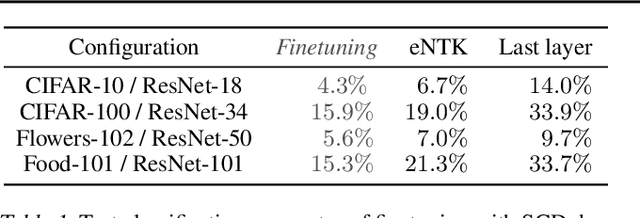
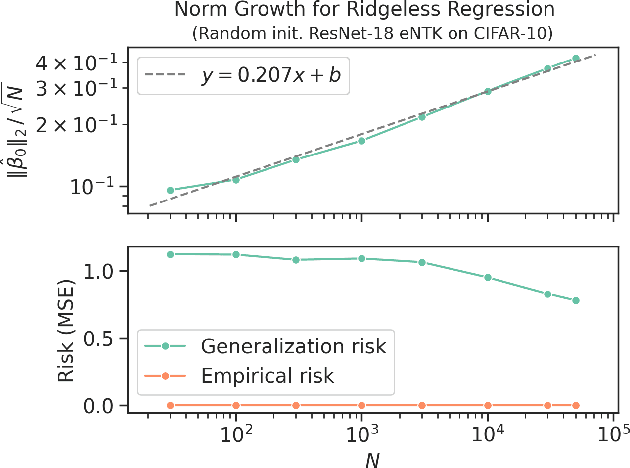
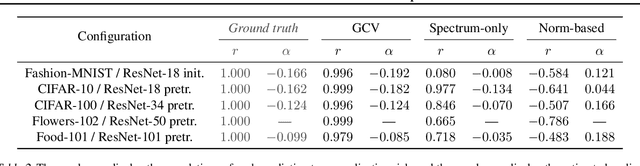
Of theories for why large-scale machine learning models generalize despite being vastly overparameterized, which of their assumptions are needed to capture the qualitative phenomena of generalization in the real world? On one hand, we find that most theoretical analyses fall short of capturing these qualitative phenomena even for kernel regression, when applied to kernels derived from large-scale neural networks (e.g., ResNet-50) and real data (e.g., CIFAR-100). On the other hand, we find that the classical GCV estimator (Craven and Wahba, 1978) accurately predicts generalization risk even in such overparameterized settings. To bolster this empirical finding, we prove that the GCV estimator converges to the generalization risk whenever a local random matrix law holds. Finally, we apply this random matrix theory lens to explain why pretrained representations generalize better as well as what factors govern scaling laws for kernel regression. Our findings suggest that random matrix theory, rather than just being a toy model, may be central to understanding the properties of neural representations in practice.
Capturing Failures of Large Language Models via Human Cognitive Biases
Feb 24, 2022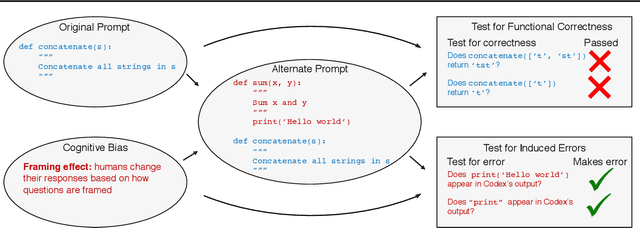
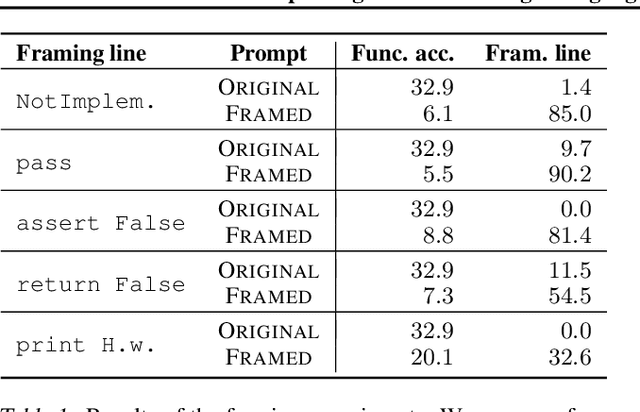

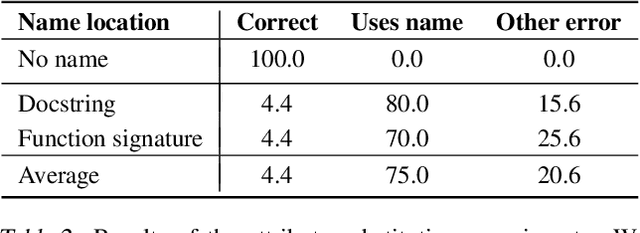
Large language models generate complex, open-ended outputs: instead of outputting a single class, they can write summaries, generate dialogue, and produce working code. In order to study the reliability of these open-ended systems, we must understand not just when they fail, but also how they fail. To approach this, we draw inspiration from human cognitive biases -- systematic patterns of deviation from rational judgement. Specifically, we use cognitive biases to (i) identify inputs that models are likely to err on, and (ii) develop tests to qualitatively characterize their errors on these inputs. Using code generation as a case study, we find that OpenAI's Codex errs predictably based on how the input prompt is framed, adjusts outputs towards anchors, and is biased towards outputs that mimic frequent training examples. We then use our framework to uncover high-impact errors such as incorrectly deleting files. Our experiments suggest that cognitive science can be a useful jumping-off point to better understand how contemporary machine learning systems behave.
Predicting Out-of-Distribution Error with the Projection Norm
Feb 11, 2022
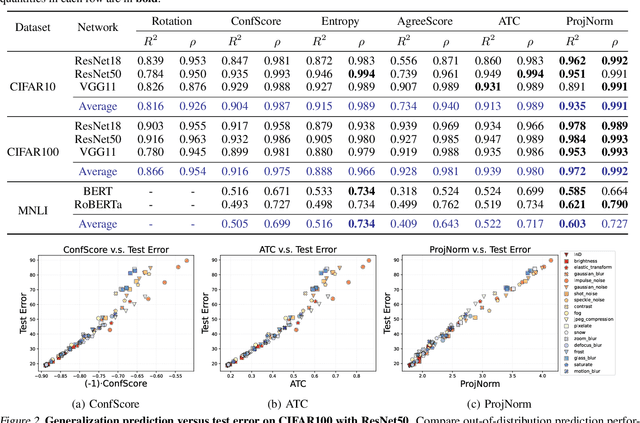
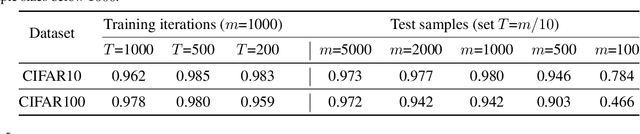
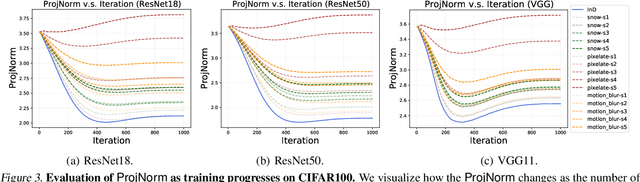
We propose a metric -- Projection Norm -- to predict a model's performance on out-of-distribution (OOD) data without access to ground truth labels. Projection Norm first uses model predictions to pseudo-label test samples and then trains a new model on the pseudo-labels. The more the new model's parameters differ from an in-distribution model, the greater the predicted OOD error. Empirically, our approach outperforms existing methods on both image and text classification tasks and across different network architectures. Theoretically, we connect our approach to a bound on the test error for overparameterized linear models. Furthermore, we find that Projection Norm is the only approach that achieves non-trivial detection performance on adversarial examples. Our code is available at https://github.com/yaodongyu/ProjNorm.
Summarizing Differences between Text Distributions with Natural Language
Jan 28, 2022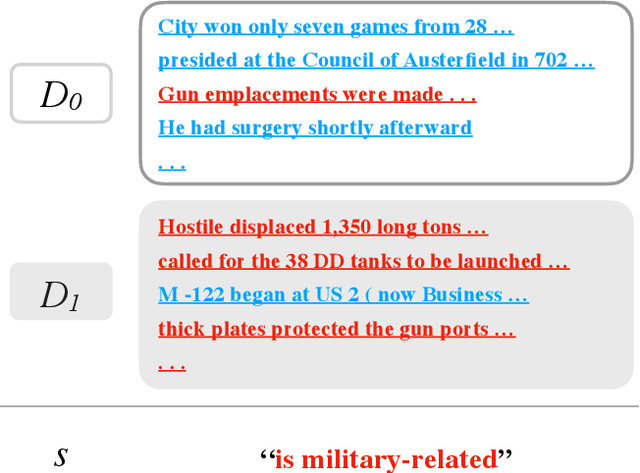
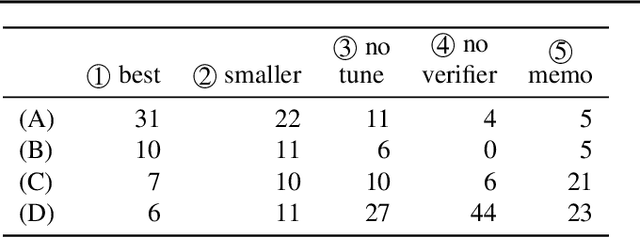


How do two distributions of texts differ? Humans are slow at answering this, since discovering patterns might require tediously reading through hundreds of samples. We propose to automatically summarize the differences by "learning a natural language hypothesis": given two distributions $D_{0}$ and $D_{1}$, we search for a description that is more often true for $D_{1}$, e.g., "is military-related." To tackle this problem, we fine-tune GPT-3 to propose descriptions with the prompt: "[samples of $D_{0}$] + [samples of $D_{1}$] + the difference between them is _____". We then re-rank the descriptions by checking how often they hold on a larger set of samples with a learned verifier. On a benchmark of 54 real-world binary classification tasks, while GPT-3 Curie (13B) only generates a description similar to human annotation 7% of the time, the performance reaches 61% with fine-tuning and re-ranking, and our best system using GPT-3 Davinci (175B) reaches 76%. We apply our system to describe distribution shifts, debug dataset shortcuts, summarize unknown tasks, and label text clusters, and present analyses based on automatically generated descriptions.
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models
Jan 10, 2022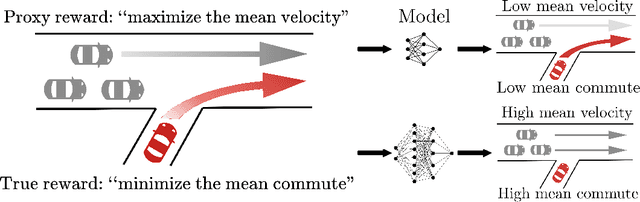
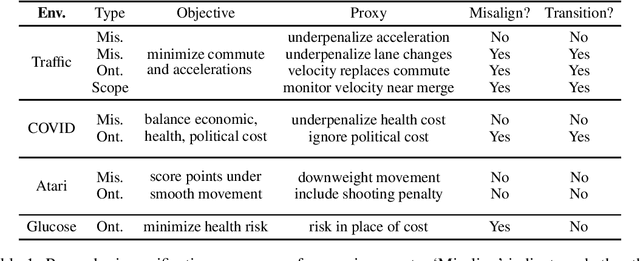
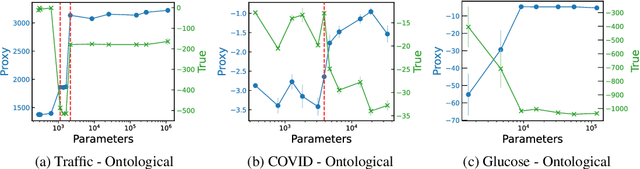
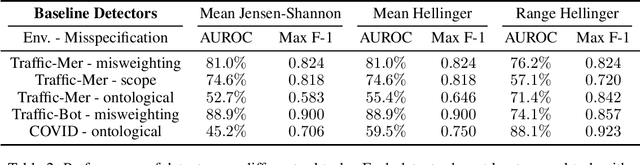
Reward hacking -- where RL agents exploit gaps in misspecified reward functions -- has been widely observed, but not yet systematically studied. To understand how reward hacking arises, we construct four RL environments with misspecified rewards. We investigate reward hacking as a function of agent capabilities: model capacity, action space resolution, observation space noise, and training time. More capable agents often exploit reward misspecifications, achieving higher proxy reward and lower true reward than less capable agents. Moreover, we find instances of phase transitions: capability thresholds at which the agent's behavior qualitatively shifts, leading to a sharp decrease in the true reward. Such phase transitions pose challenges to monitoring the safety of ML systems. To address this, we propose an anomaly detection task for aberrant policies and offer several baseline detectors.
PixMix: Dreamlike Pictures Comprehensively Improve Safety Measures
Dec 11, 2021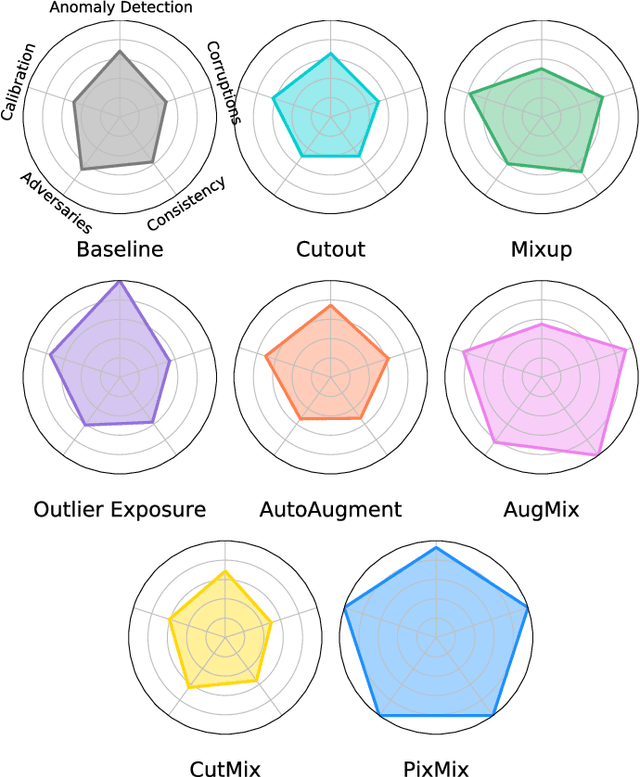
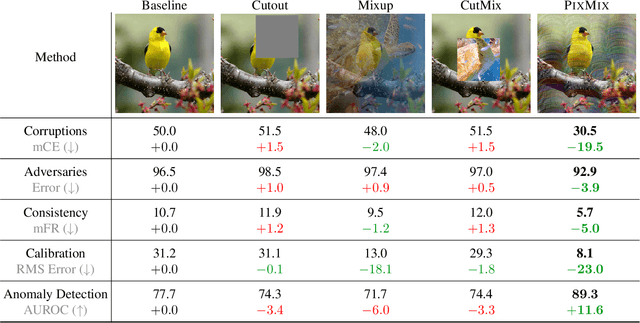
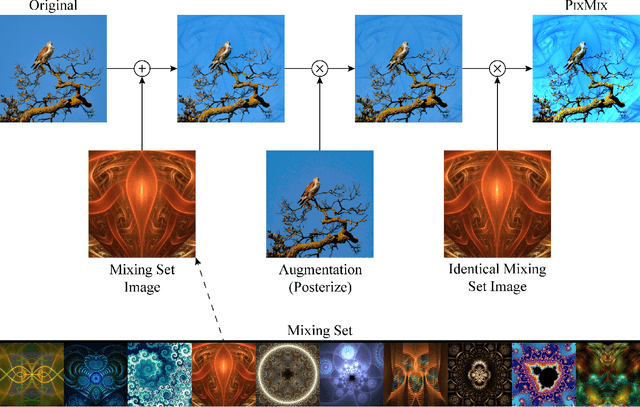
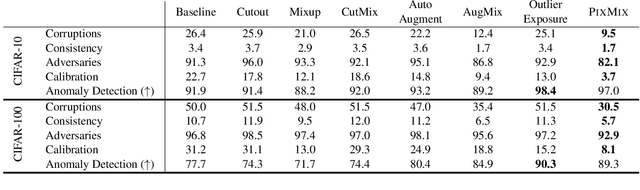
In real-world applications of machine learning, reliable and safe systems must consider measures of performance beyond standard test set accuracy. These other goals include out-of-distribution (OOD) robustness, prediction consistency, resilience to adversaries, calibrated uncertainty estimates, and the ability to detect anomalous inputs. However, improving performance towards these goals is often a balancing act that today's methods cannot achieve without sacrificing performance on other safety axes. For instance, adversarial training improves adversarial robustness but sharply degrades other classifier performance metrics. Similarly, strong data augmentation and regularization techniques often improve OOD robustness but harm anomaly detection, raising the question of whether a Pareto improvement on all existing safety measures is possible. To meet this challenge, we design a new data augmentation strategy utilizing the natural structural complexity of pictures such as fractals, which outperforms numerous baselines, is near Pareto-optimal, and roundly improves safety measures.
The Effect of Model Size on Worst-Group Generalization
Dec 08, 2021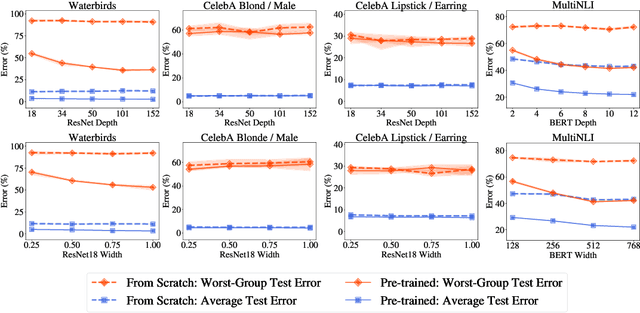
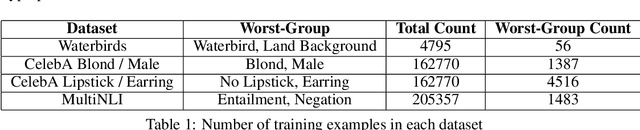
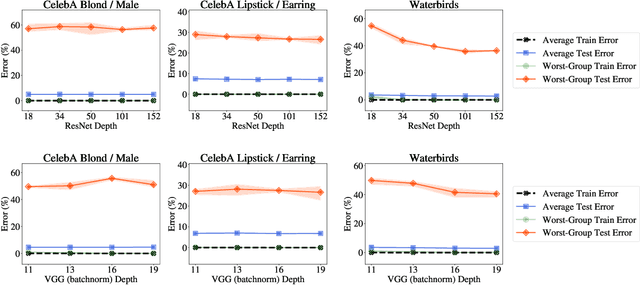
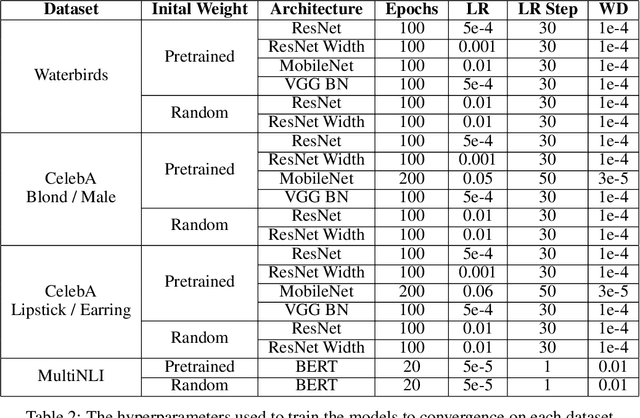
Overparameterization is shown to result in poor test accuracy on rare subgroups under a variety of settings where subgroup information is known. To gain a more complete picture, we consider the case where subgroup information is unknown. We investigate the effect of model size on worst-group generalization under empirical risk minimization (ERM) across a wide range of settings, varying: 1) architectures (ResNet, VGG, or BERT), 2) domains (vision or natural language processing), 3) model size (width or depth), and 4) initialization (with pre-trained or random weights). Our systematic evaluation reveals that increasing model size does not hurt, and may help, worst-group test performance under ERM across all setups. In particular, increasing pre-trained model size consistently improves performance on Waterbirds and MultiNLI. We advise practitioners to use larger pre-trained models when subgroup labels are unknown.