 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimicking Word Embeddings using Subword RNNs
Jul 21, 2017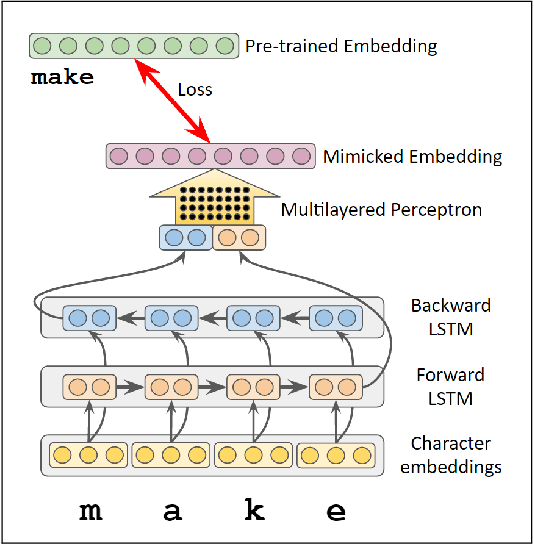


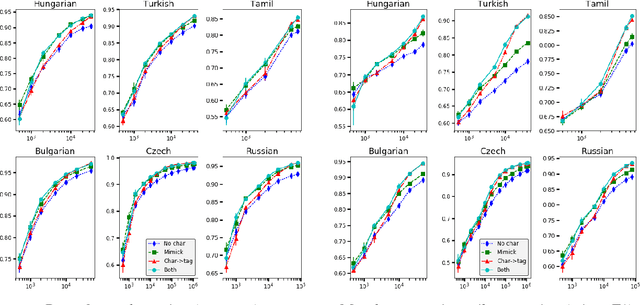
Word embeddings improve generalization over lexical features by placing each word in a lower-dimensional space, using distributional information obtained from unlabeled data. However, the effectiveness of word embeddings for downstream NLP tasks is limited by out-of-vocabulary (OOV) words, for which embeddings do not exist. In this paper, we present MIMICK, an approach to generating OOV word embeddings compositionally, by learning a function from spellings to distributional embeddings. Unlike prior work, MIMICK does not require re-training on the original word embedding corpus; instead, learning is performed at the type level. Intrinsic and extrinsic evaluations demonstrate the power of this simple approach. On 23 languages, MIMICK improves performance over a word-based baseline for tagging part-of-speech and morphosyntactic attributes. It is competitive with (and complementary to) a supervised character-based model in low-resource settings.
Unsupervised Learning for Lexicon-Based Classification
Nov 21, 2016
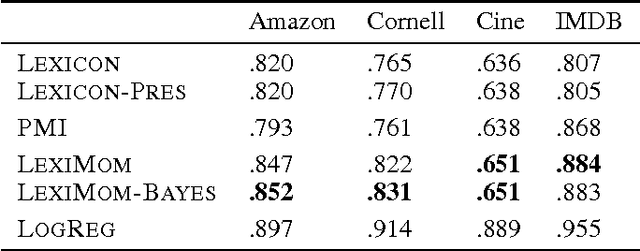
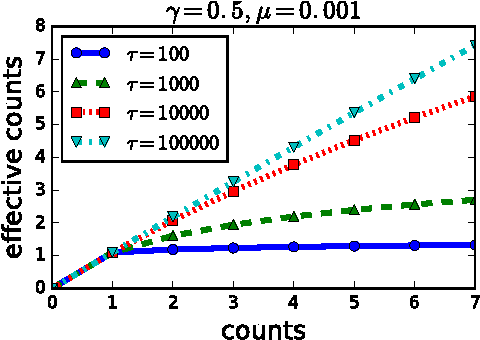
In lexicon-based classification, documents are assigned labels by comparing the number of words that appear from two opposed lexicons, such as positive and negative sentiment. Creating such words lists is often easier than labeling instances, and they can be debugged by non-experts if classification performance is unsatisfactory. However, there is little analysis or justification of this classification heuristic. This paper describes a set of assumptions that can be used to derive a probabilistic justification for lexicon-based classification, as well as an analysis of its expected accuracy. One key assumption behind lexicon-based classification is that all words in each lexicon are equally predictive. This is rarely true in practice, which is why lexicon-based approaches are usually outperformed by supervised classifiers that learn distinct weights on each word from labeled instances. This paper shows that it is possible to learn such weights without labeled data, by leveraging co-occurrence statistics across the lexicons. This offers the best of both worlds: light supervision in the form of lexicons, and data-driven classification with higher accuracy than traditional word-counting heuristics.
Toward Socially-Infused Information Extraction: Embedding Authors, Mentions, and Entities
Sep 26, 2016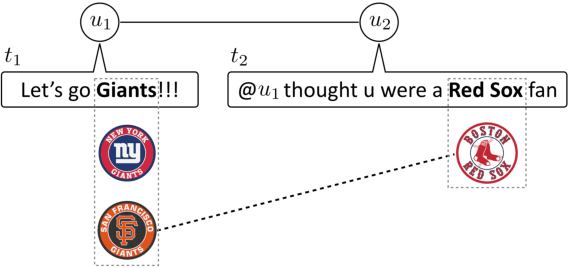

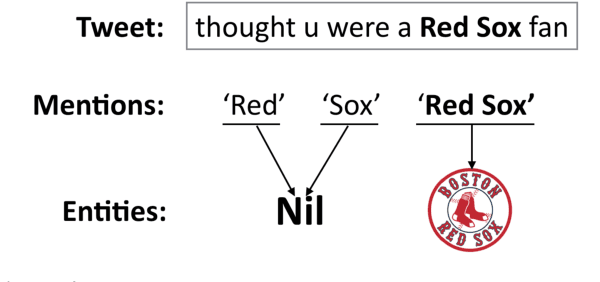
Entity linking is the task of identifying mentions of entities in text, and linking them to entries in a knowledge base. This task is especially difficult in microblogs, as there is little additional text to provide disambiguating context; rather, authors rely on an implicit common ground of shared knowledge with their readers. In this paper, we attempt to capture some of this implicit context by exploiting the social network structure in microblogs. We build on the theory of homophily, which implies that socially linked individuals share interests, and are therefore likely to mention the same sorts of entities. We implement this idea by encoding authors, mentions, and entities in a continuous vector space, which is constructed so that socially-connected authors have similar vector representations. These vectors are incorporated into a neural structured prediction model, which captures structural constraints that are inherent in the entity linking task. Together, these design decisions yield F1 improvements of 1%-5% on benchmark datasets, as compared to the previous state-of-the-art.
Nonparametric Bayesian Storyline Detection from Microtexts
Sep 24, 2016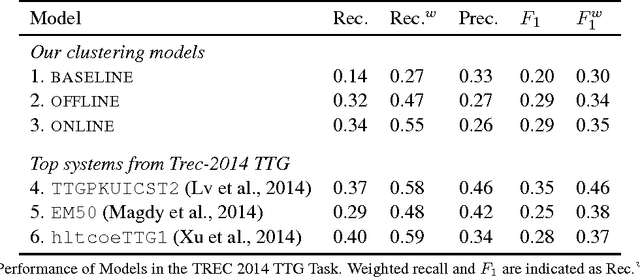
News events and social media are composed of evolving storylines, which capture public attention for a limited period of time. Identifying storylines requires integrating temporal and linguistic information, and prior work takes a largely heuristic approach. We present a novel online non-parametric Bayesian framework for storyline detection, using the distance-dependent Chinese Restaurant Process (dd-CRP). To ensure efficient linear-time inference, we employ a fixed-lag Gibbs sampling procedure, which is novel for the dd-CRP. We evaluate on the TREC Twitter Timeline Generation (TTG), obtaining encouraging results: despite using a weak baseline retrieval model, the dd-CRP story clustering method is competitive with the best entries in the 2014 TTG task.
Morphological Priors for Probabilistic Neural Word Embeddings
Sep 24, 2016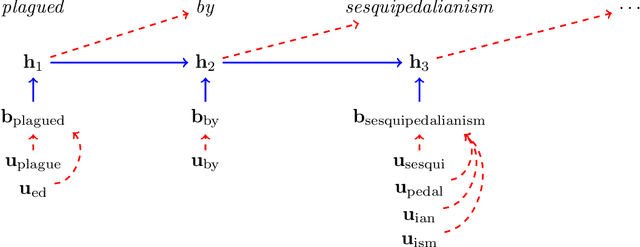
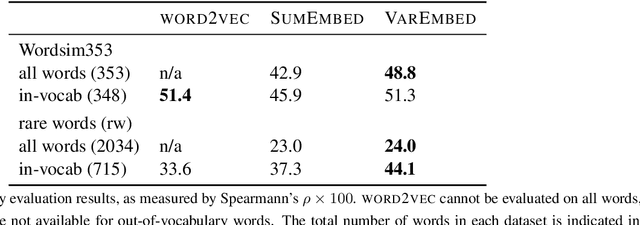
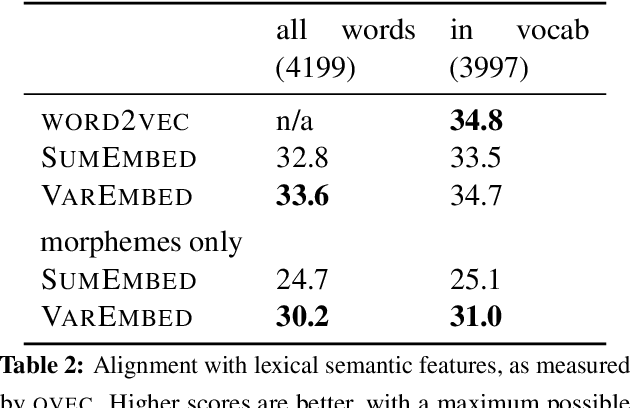
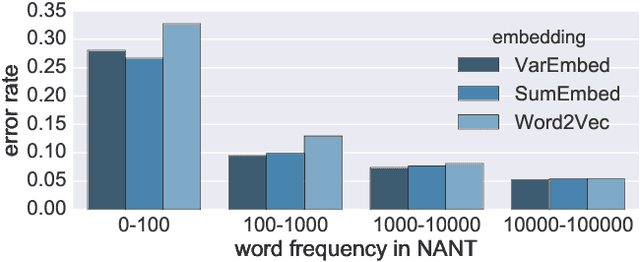
Word embeddings allow natural language processing systems to share statistical information across related words. These embeddings are typically based on distributional statistics, making it difficult for them to generalize to rare or unseen words. We propose to improve word embeddings by incorporating morphological information, capturing shared sub-word features. Unlike previous work that constructs word embeddings directly from morphemes, we combine morphological and distributional information in a unified probabilistic framework, in which the word embedding is a latent variable. The morphological information provides a prior distribution on the latent word embeddings, which in turn condition a likelihood function over an observed corpus. This approach yields improvements on intrinsic word similarity evaluations, and also in the downstream task of part-of-speech tagging.
The Social Dynamics of Language Change in Online Networks
Sep 07, 2016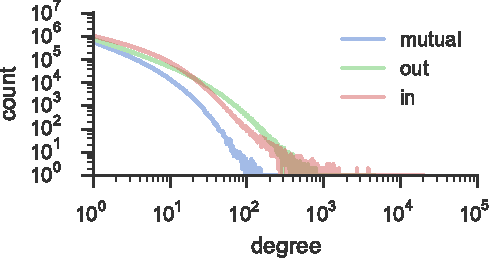
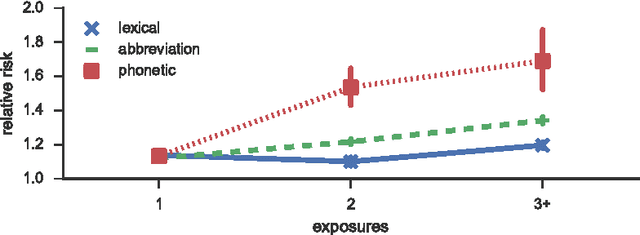
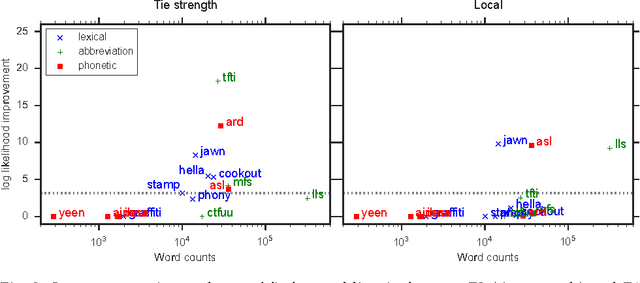
Language change is a complex social phenomenon, revealing pathways of communication and sociocultural influence. But, while language change has long been a topic of study in sociolinguistics, traditional linguistic research methods rely on circumstantial evidence, estimating the direction of change from differences between older and younger speakers. In this paper, we use a data set of several million Twitter users to track language changes in progress. First, we show that language change can be viewed as a form of social influence: we observe complex contagion for phonetic spellings and "netspeak" abbreviations (e.g., lol), but not for older dialect markers from spoken language. Next, we test whether specific types of social network connections are more influential than others, using a parametric Hawkes process model. We find that tie strength plays an important role: densely embedded social ties are significantly better conduits of linguistic influence. Geographic locality appears to play a more limited role: we find relatively little evidence to support the hypothesis that individuals are more influenced by geographically local social ties, even in their usage of geographical dialect markers.
A Kernel Independence Test for Geographical Language Variation
Aug 29, 2016Quantifying the degree of spatial dependence for linguistic variables is a key task for analyzing dialectal variation. However, existing approaches have important drawbacks. First, they are based on parametric models of dependence, which limits their power in cases where the underlying parametric assumptions are violated. Second, they are not applicable to all types of linguistic data: some approaches apply only to frequencies, others to boolean indicators of whether a linguistic variable is present. We present a new method for measuring geographical language variation, which solves both of these problems. Our approach builds on Reproducing Kernel Hilbert space (RKHS) representations for nonparametric statistics, and takes the form of a test statistic that is computed from pairs of individual geotagged observations without aggregation into predefined geographical bins. We compare this test with prior work using synthetic data as well as a diverse set of real datasets: a corpus of Dutch tweets, a Dutch syntactic atlas, and a dataset of letters to the editor in North American newspapers. Our proposed test is shown to support robust inferences across a broad range of scenarios and types of data.
Shallow Discourse Parsing Using Distributed Argument Representations and Bayesian Optimization
Jun 14, 2016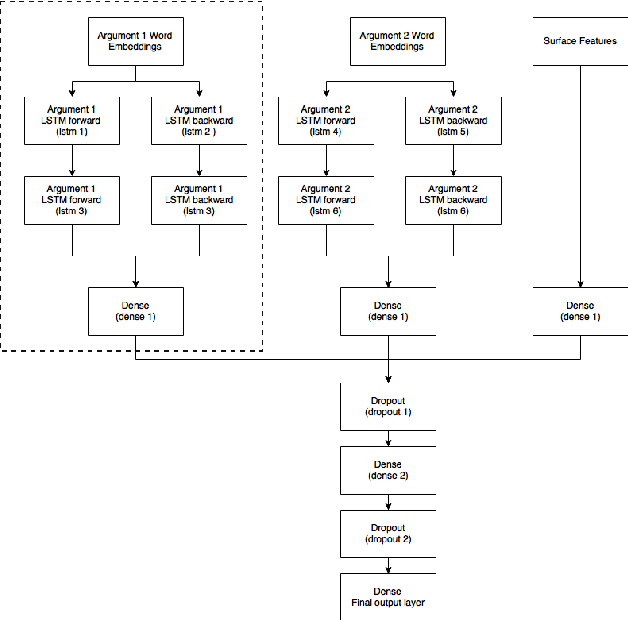
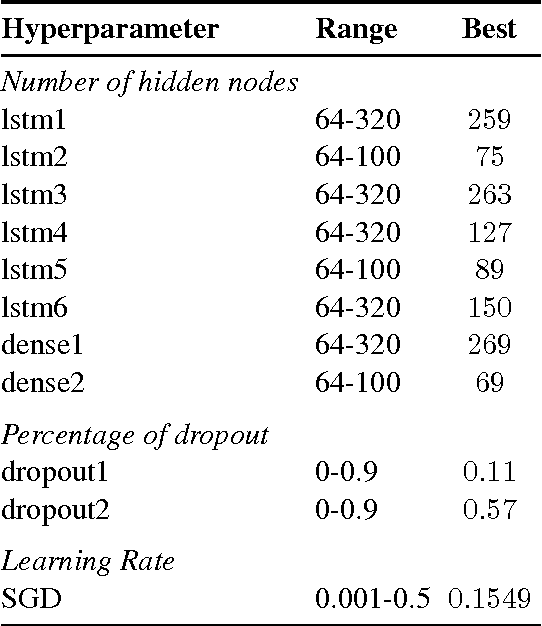
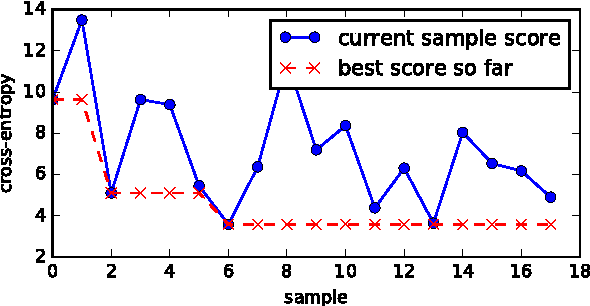
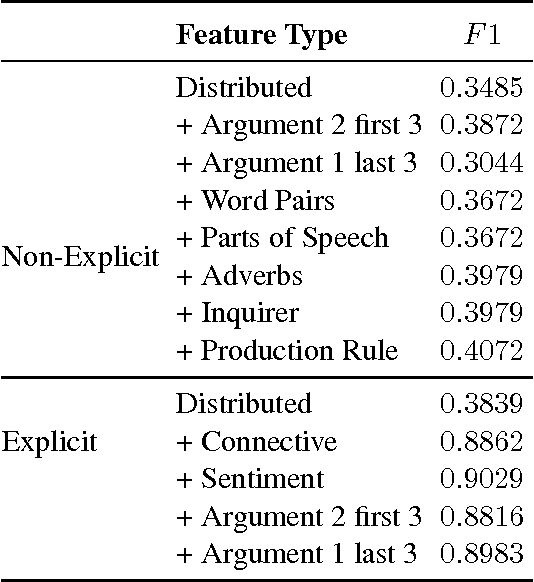
This paper describes the Georgia Tech team's approach to the CoNLL-2016 supplementary evaluation on discourse relation sense classification. We use long short-term memories (LSTM) to induce distributed representations of each argument, and then combine these representations with surface features in a neural network. The architecture of the neural network is determined by Bayesian hyperparameter search.
A Latent Variable Recurrent Neural Network for Discourse Relation Language Models
Apr 05, 2016
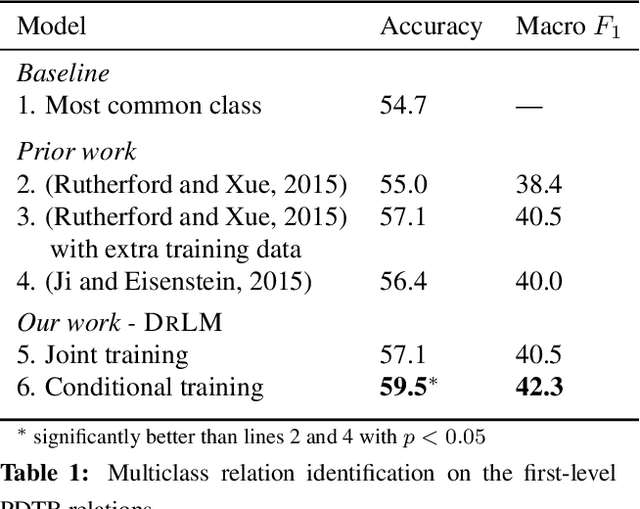
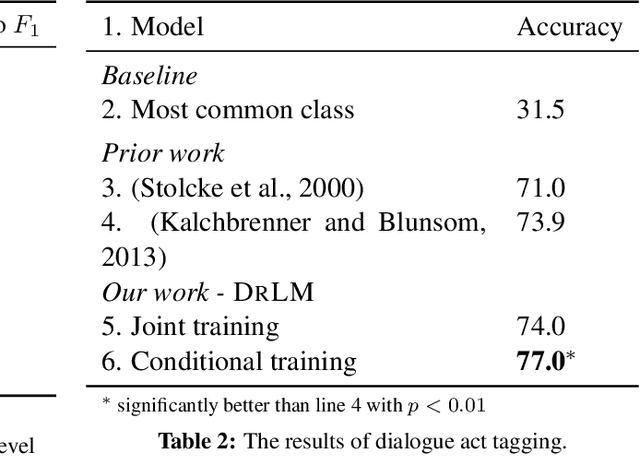
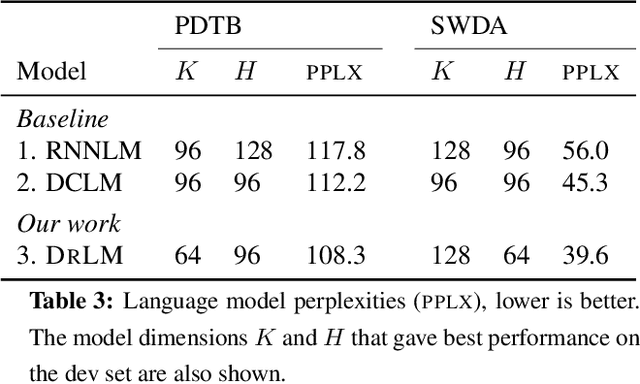
This paper presents a novel latent variable recurrent neural network architecture for jointly modeling sequences of words and (possibly latent) discourse relations between adjacent sentences. A recurrent neural network generates individual words, thus reaping the benefits of discriminatively-trained vector representations. The discourse relations are represented with a latent variable, which can be predicted or marginalized, depending on the task. The resulting model can therefore employ a training objective that includes not only discourse relation classification, but also word prediction. As a result, it outperforms state-of-the-art alternatives for two tasks: implicit discourse relation classification in the Penn Discourse Treebank, and dialog act classification in the Switchboard corpus. Furthermore, by marginalizing over latent discourse relations at test time, we obtain a discourse informed language model, which improves over a strong LSTM baseline.
Part-of-Speech Tagging for Historical English
Apr 04, 2016
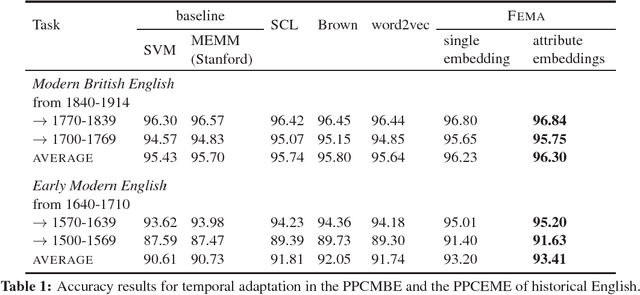
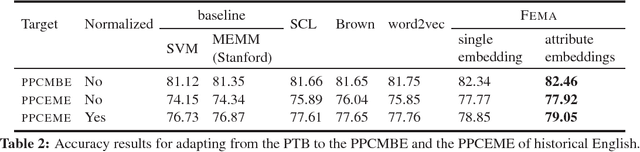
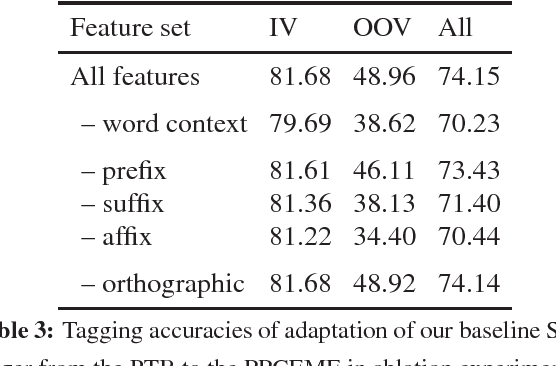
As more historical texts are digitized, there is interest in applying natural language processing tools to these archives. However, the performance of these tools is often unsatisfactory, due to language change and genre differences. Spelling normalization heuristics are the dominant solution for dealing with historical texts, but this approach fails to account for changes in usage and vocabulary. In this empirical paper, we assess the capability of domain adaptation techniques to cope with historical texts, focusing on the classic benchmark task of part-of-speech tagging. We evaluate several domain adaptation methods on the task of tagging Early Modern English and Modern British English texts in the Penn Corpora of Historical English. We demonstrate that the Feature Embedding method for unsupervised domain adaptation outperforms word embeddings and Brown clusters, showing the importance of embedding the entire feature space, rather than just individual words. Feature Embeddings also give better performance than spelling normalization, but the combination of the two methods is better still, yielding a 5% raw improvement in tagging accuracy on Early Modern English texts.