 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperSound: Generating Implicit Neural Representations of Audio Signals with Hypernetworks
Nov 03, 2022


Implicit neural representations (INRs) are a rapidly growing research field, which provides alternative ways to represent multimedia signals. Recent applications of INRs include image super-resolution, compression of high-dimensional signals, or 3D rendering. However, these solutions usually focus on visual data, and adapting them to the audio domain is not trivial. Moreover, it requires a separately trained model for every data sample. To address this limitation, we propose HyperSound, a meta-learning method leveraging hypernetworks to produce INRs for audio signals unseen at training time. We show that our approach can reconstruct sound waves with quality comparable to other state-of-the-art models.
Hypernetwork approach to Bayesian MAML
Oct 06, 2022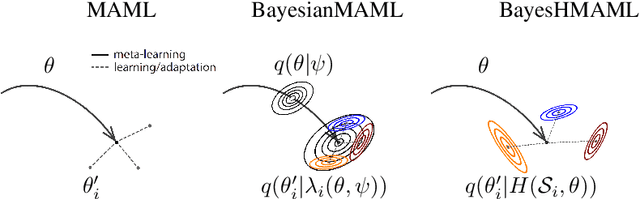
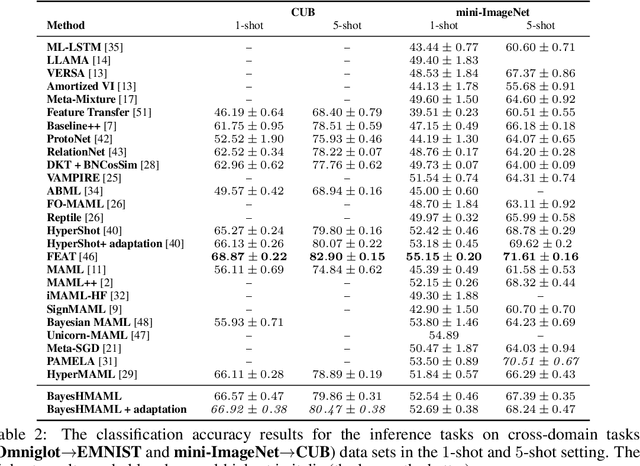
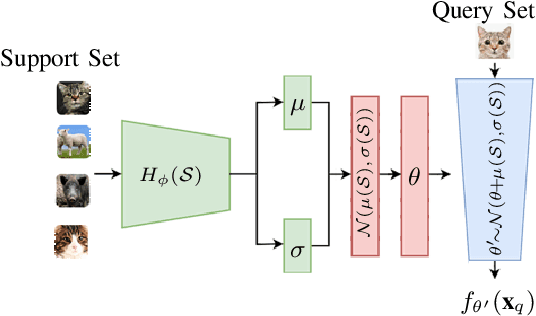
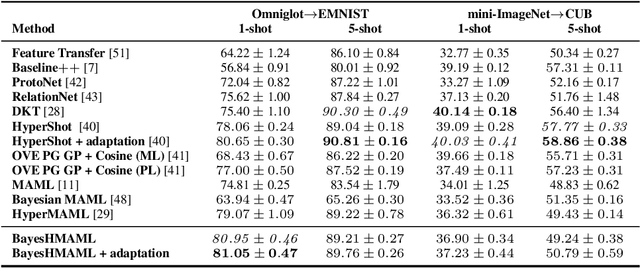
The main goal of Few-Shot learning algorithms is to enable learning from small amounts of data. One of the most popular and elegant Few-Shot learning approaches is Model-Agnostic Meta-Learning (MAML). The main idea behind this method is to learn shared universal weights of a meta-model, which then are adapted for specific tasks. However, due to limited data size, the method suffers from over-fitting and poorly quantifies uncertainty. Bayesian approaches could, in principle, alleviate these shortcomings by learning weight distributions in place of point-wise weights. Unfortunately, previous Bayesian modifications of MAML are limited in a way similar to the classic MAML, e.g., task-specific adaptations must share the same structure and can not diverge much from the universal meta-model. Additionally, task-specific distributions are considered as posteriors to the universal distributions working as priors, and optimizing them jointly with gradients is hard and poses a risk of getting stuck in local optima. In this paper, we propose BayesianHyperShot, a novel generalization of Bayesian MAML, which employs Bayesian principles along with Hypernetworks for MAML. We achieve better convergence than the previous methods by classically learning universal weights. Furthermore, Bayesian treatment of the specific tasks enables uncertainty quantification, and high flexibility of task adaptations is achieved using Hypernetworks instead of gradient-based updates. Consequently, the proposed approach not only improves over the previous methods, both classic and Bayesian MAML in several standard Few-Shot learning benchmarks but also benefits from the properties of the Bayesian framework.
ProPaLL: Probabilistic Partial Label Learning
Aug 21, 2022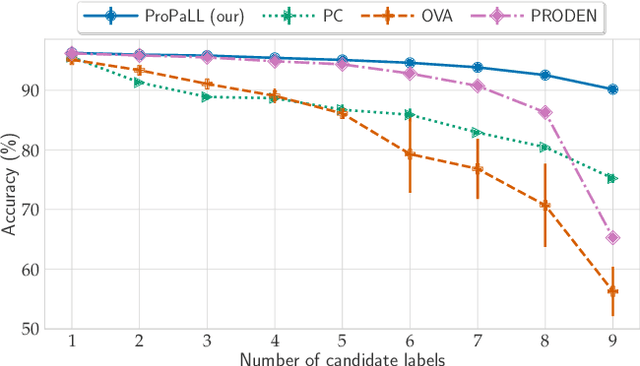
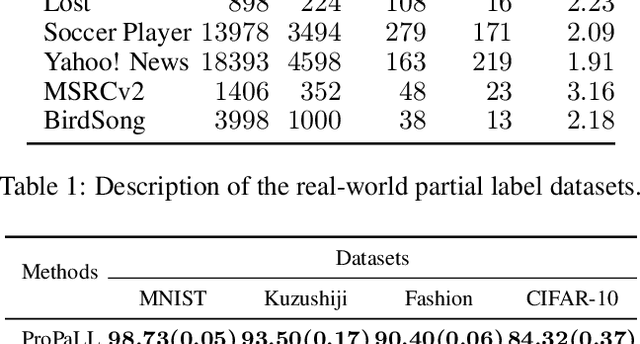
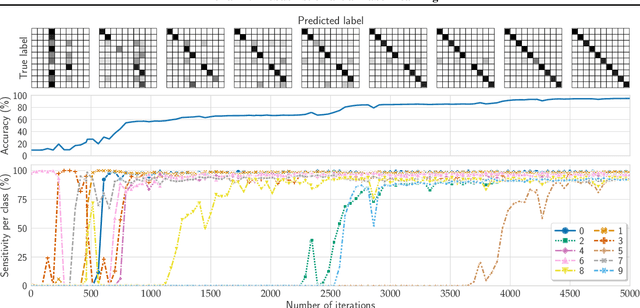
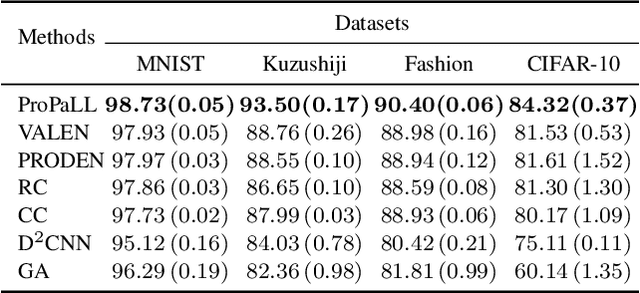
Partial label learning is a type of weakly supervised learning, where each training instance corresponds to a set of candidate labels, among which only one is true. In this paper, we introduce ProPaLL, a novel probabilistic approach to this problem, which has at least three advantages compared to the existing approaches: it simplifies the training process, improves performance, and can be applied to any deep architecture. Experiments conducted on artificial and real-world datasets indicate that ProPaLL outperforms the existing approaches.
LIDL: Local Intrinsic Dimension Estimation Using Approximate Likelihood
Jun 29, 2022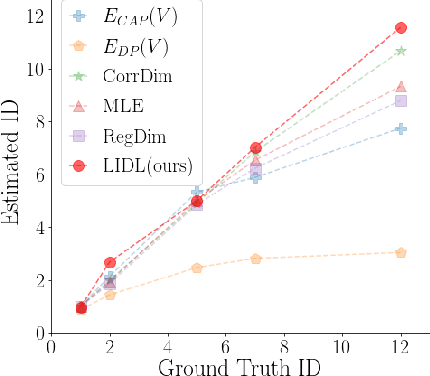

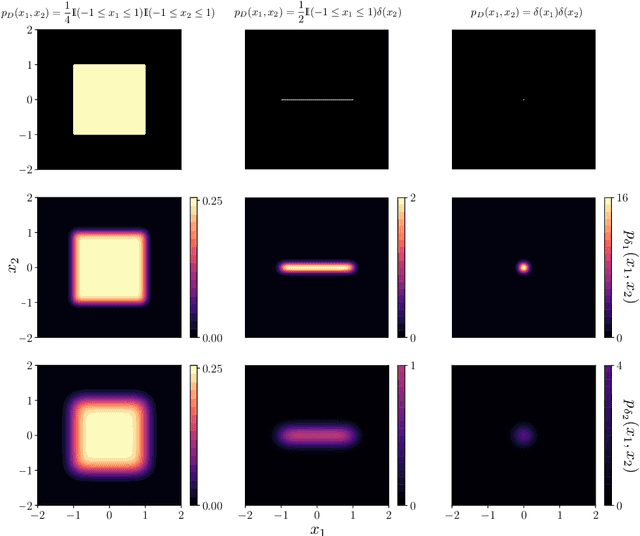
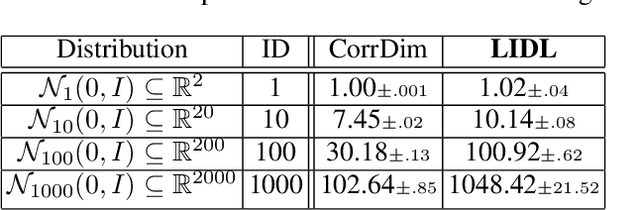
Most of the existing methods for estimating the local intrinsic dimension of a data distribution do not scale well to high-dimensional data. Many of them rely on a non-parametric nearest neighbors approach which suffers from the curse of dimensionality. We attempt to address that challenge by proposing a novel approach to the problem: Local Intrinsic Dimension estimation using approximate Likelihood (LIDL). Our method relies on an arbitrary density estimation method as its subroutine and hence tries to sidestep the dimensionality challenge by making use of the recent progress in parametric neural methods for likelihood estimation. We carefully investigate the empirical properties of the proposed method, compare them with our theoretical predictions, and show that LIDL yields competitive results on the standard benchmarks for this problem and that it scales to thousands of dimensions. What is more, we anticipate this approach to improve further with the continuing advances in the density estimation literature.
SLOVA: Uncertainty Estimation Using Single Label One-Vs-All Classifier
Jun 28, 2022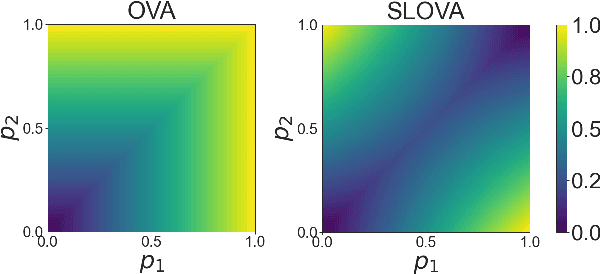
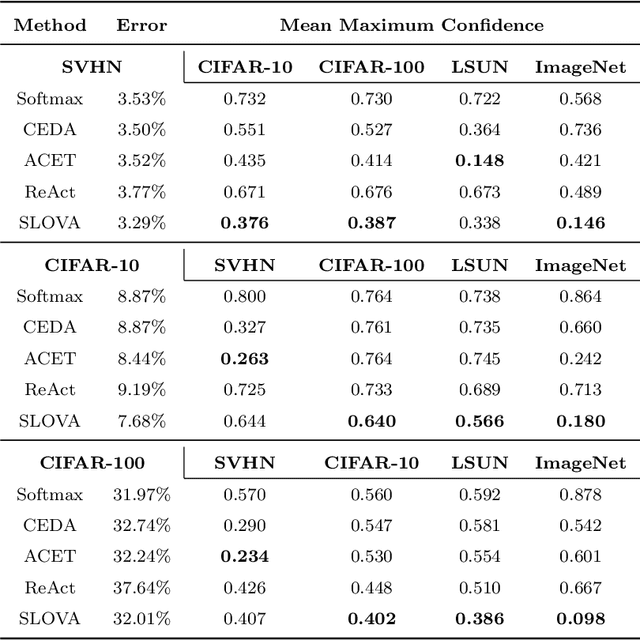
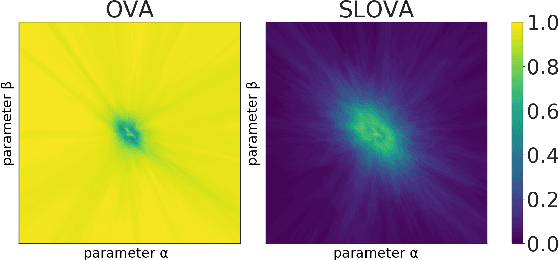
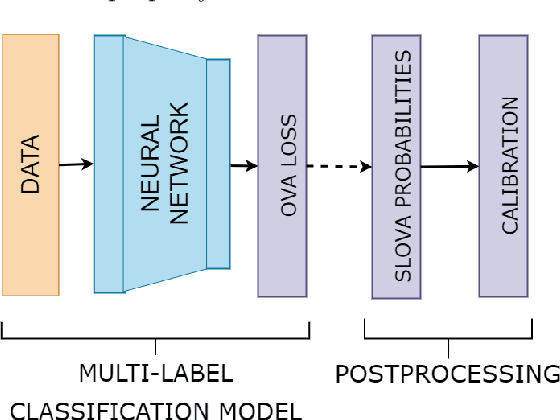
Deep neural networks present impressive performance, yet they cannot reliably estimate their predictive confidence, limiting their applicability in high-risk domains. We show that applying a multi-label one-vs-all loss reveals classification ambiguity and reduces model overconfidence. The introduced SLOVA (Single Label One-Vs-All) model redefines typical one-vs-all predictive probabilities to a single label situation, where only one class is the correct answer. The proposed classifier is confident only if a single class has a high probability and other probabilities are negligible. Unlike the typical softmax function, SLOVA naturally detects out-of-distribution samples if the probabilities of all other classes are small. The model is additionally fine-tuned with exponential calibration, which allows us to precisely align the confidence score with model accuracy. We verify our approach on three tasks. First, we demonstrate that SLOVA is competitive with the state-of-the-art on in-distribution calibration. Second, the performance of SLOVA is robust under dataset shifts. Finally, our approach performs extremely well in the detection of out-of-distribution samples. Consequently, SLOVA is a tool that can be used in various applications where uncertainty modeling is required.
Bounding Evidence and Estimating Log-Likelihood in VAE
Jun 19, 2022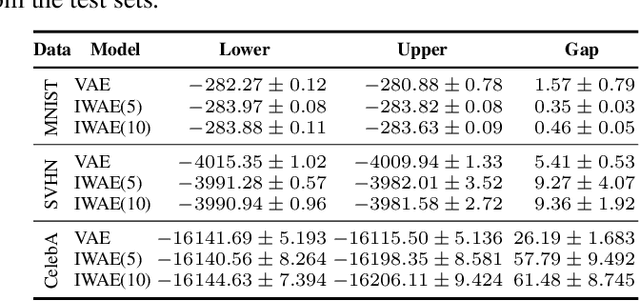
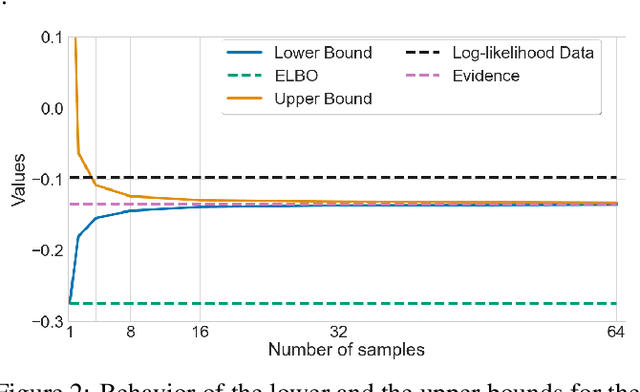
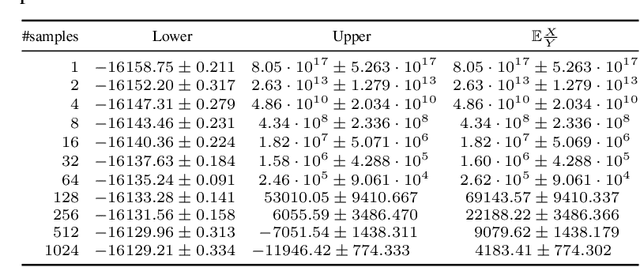

Many crucial problems in deep learning and statistics are caused by a variational gap, i.e., a difference between evidence and evidence lower bound (ELBO). As a consequence, in the classical VAE model, we obtain only the lower bound on the log-likelihood since ELBO is used as a cost function, and therefore we cannot compare log-likelihood between models. In this paper, we present a general and effective upper bound of the variational gap, which allows us to efficiently estimate the true evidence. We provide an extensive theoretical study of the proposed approach. Moreover, we show that by applying our estimation, we can easily obtain lower and upper bounds for the log-likelihood of VAE models.
Continual Learning with Guarantees via Weight Interval Constraints
Jun 16, 2022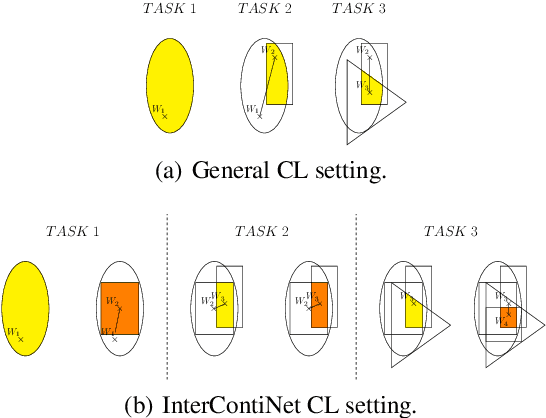
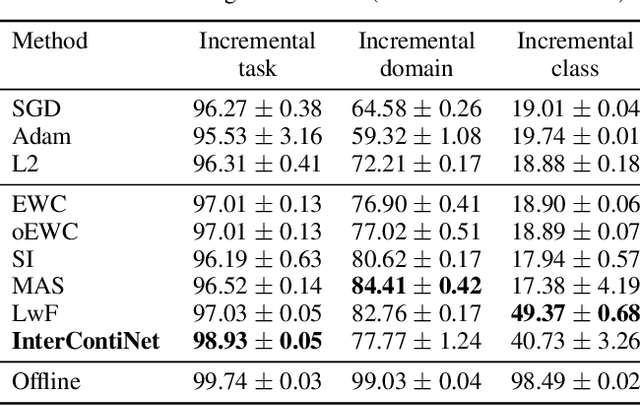
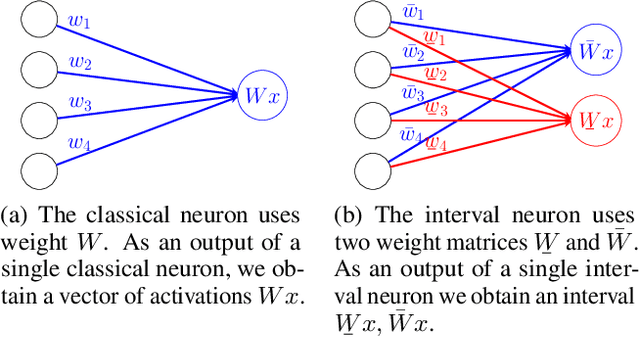
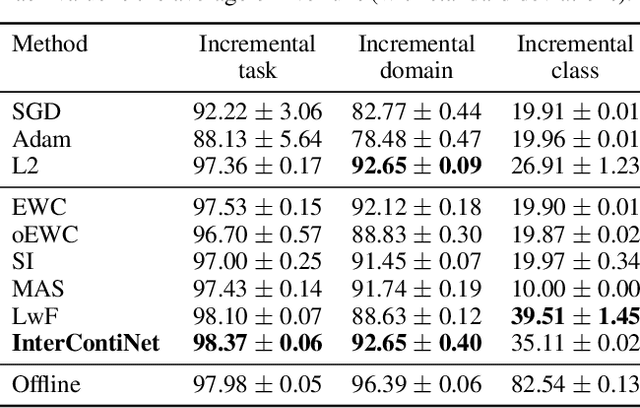
We introduce a new training paradigm that enforces interval constraints on neural network parameter space to control forgetting. Contemporary Continual Learning (CL) methods focus on training neural networks efficiently from a stream of data, while reducing the negative impact of catastrophic forgetting, yet they do not provide any firm guarantees that network performance will not deteriorate uncontrollably over time. In this work, we show how to put bounds on forgetting by reformulating continual learning of a model as a continual contraction of its parameter space. To that end, we propose Hyperrectangle Training, a new training methodology where each task is represented by a hyperrectangle in the parameter space, fully contained in the hyperrectangles of the previous tasks. This formulation reduces the NP-hard CL problem back to polynomial time while providing full resilience against forgetting. We validate our claim by developing InterContiNet (Interval Continual Learning) algorithm which leverages interval arithmetic to effectively model parameter regions as hyperrectangles. Through experimental results, we show that our approach performs well in a continual learning setup without storing data from previous tasks.
HyperShot: Few-Shot Learning by Kernel HyperNetworks
Mar 21, 2022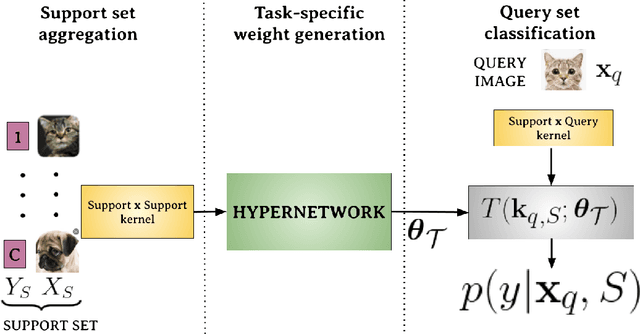
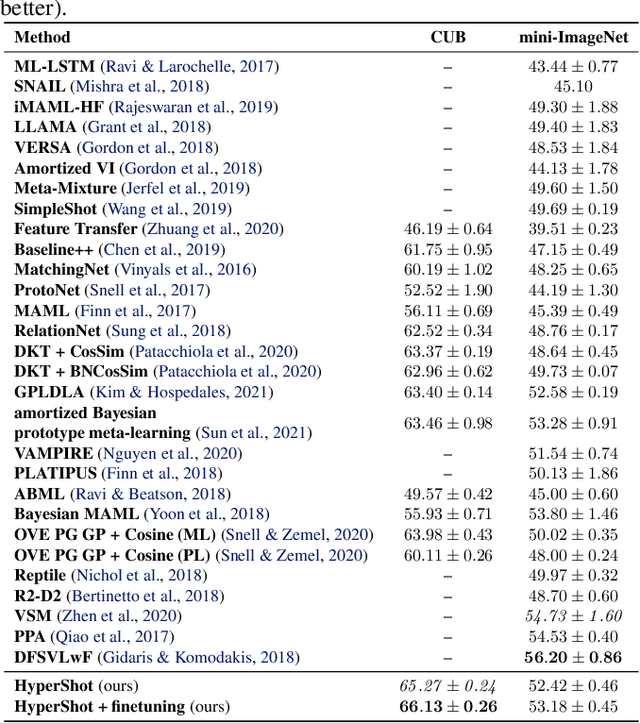
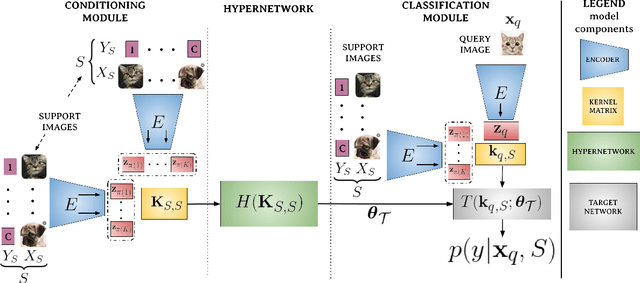
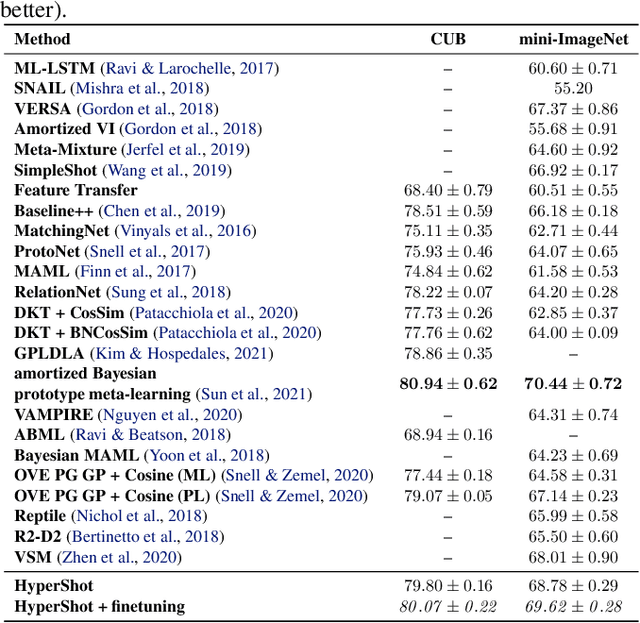
Few-shot models aim at making predictions using a minimal number of labeled examples from a given task. The main challenge in this area is the one-shot setting where only one element represents each class. We propose HyperShot - the fusion of kernels and hypernetwork paradigm. Compared to reference approaches that apply a gradient-based adjustment of the parameters, our model aims to switch the classification module parameters depending on the task's embedding. In practice, we utilize a hypernetwork, which takes the aggregated information from support data and returns the classifier's parameters handcrafted for the considered problem. Moreover, we introduce the kernel-based representation of the support examples delivered to hypernetwork to create the parameters of the classification module. Consequently, we rely on relations between embeddings of the support examples instead of direct feature values provided by the backbone models. Thanks to this approach, our model can adapt to highly different tasks.
Interpretable Image Classification with Differentiable Prototypes Assignment
Dec 06, 2021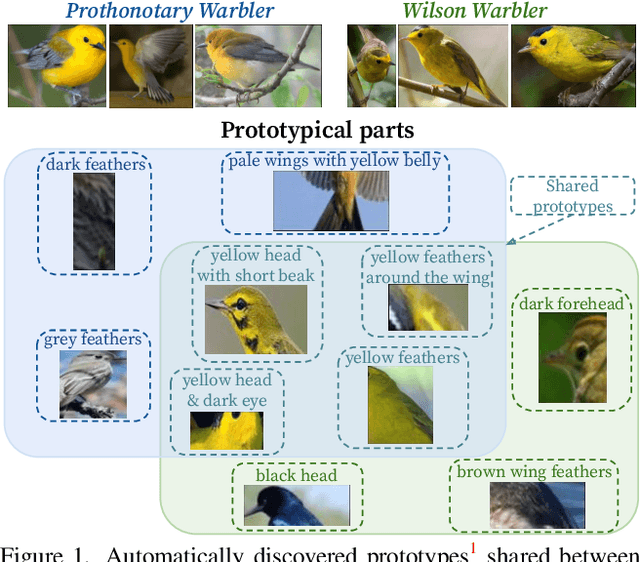
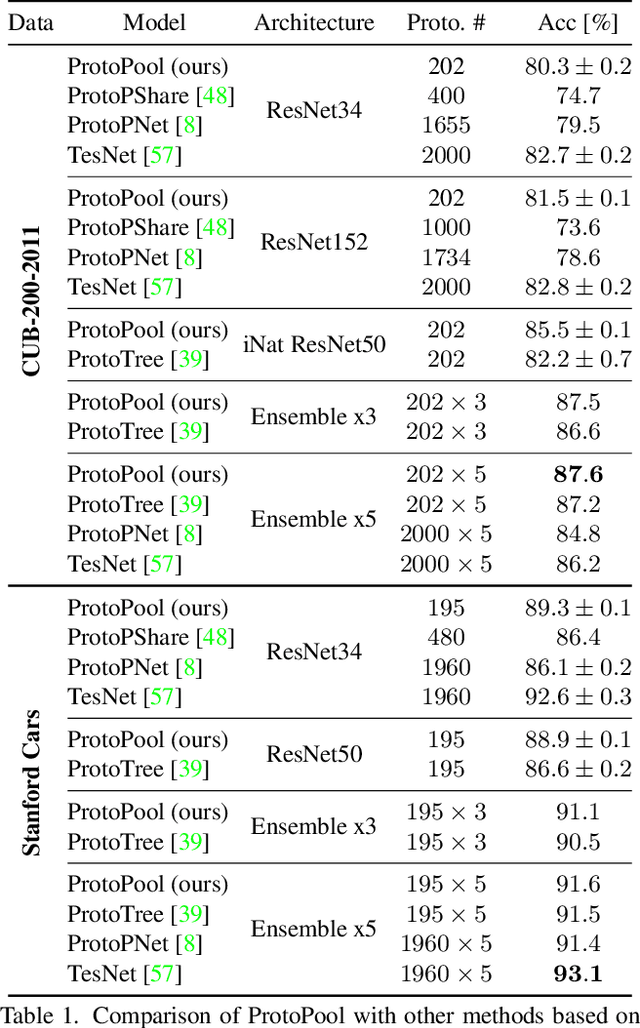
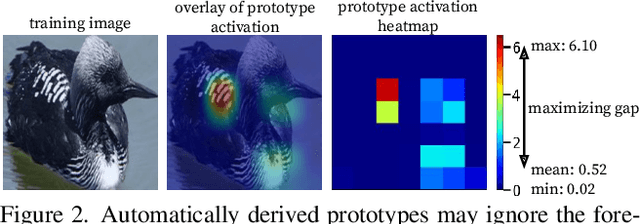

We introduce ProtoPool, an interpretable image classification model with a pool of prototypes shared by the classes. The training is more straightforward than in the existing methods because it does not require the pruning stage. It is obtained by introducing a fully differentiable assignment of prototypes to particular classes. Moreover, we introduce a novel focal similarity function to focus the model on the rare foreground features. We show that ProtoPool obtains state-of-the-art accuracy on the CUB-200-2011 and the Stanford Cars datasets, substantially reducing the number of prototypes. We provide a theoretical analysis of the method and a user study to show that our prototypes are more distinctive than those obtained with competitive methods.
MisConv: Convolutional Neural Networks for Missing Data
Oct 29, 2021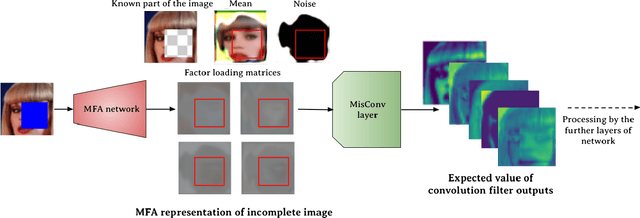
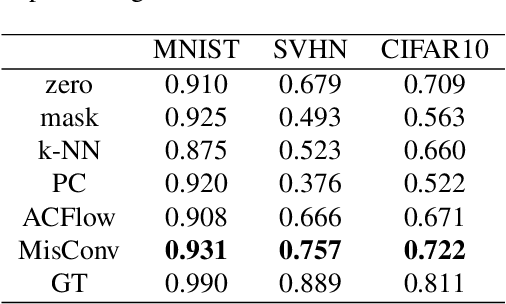
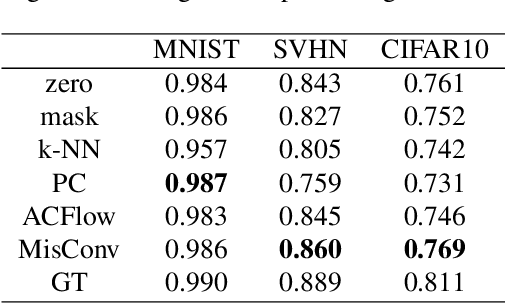

Processing of missing data by modern neural networks, such as CNNs, remains a fundamental, yet unsolved challenge, which naturally arises in many practical applications, like image inpainting or autonomous vehicles and robots. While imputation-based techniques are still one of the most popular solutions, they frequently introduce unreliable information to the data and do not take into account the uncertainty of estimation, which may be destructive for a machine learning model. In this paper, we present MisConv, a general mechanism, for adapting various CNN architectures to process incomplete images. By modeling the distribution of missing values by the Mixture of Factor Analyzers, we cover the spectrum of possible replacements and find an analytical formula for the expected value of convolution operator applied to the incomplete image. The whole framework is realized by matrix operations, which makes MisConv extremely efficient in practice. Experiments performed on various image processing tasks demonstrate that MisConv achieves superior or comparable performance to the state-of-the-art methods.