 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListening with Attention: Entropy-Guided Explainability for Transformer-Based Audio Models
Jun 12, 2026Transformer-based automatic speech recognition (ASR) models such as Whisper are highly accurate, but their predictions remain difficult to interpret. Existing explainable AI (XAI) methods often lack faithfulness and precise temporal grounding. We propose Listening with Entropy-guided Attention for Faithful explainability (LEAF-X), a model-intrinsic XAI framework for transformer-based ASR. LEAF-X combines entropy-guided attention weighting, multi-layer attention rollout, and optional causal ablations to identify low-entropy, high-impact heads and layers, producing sparse token-to-frame attributions. Unlike perturbation-based explainers or raw attention maps, LEAF-X exploits the internal structure of encoder-decoder and speech-augmented decoder-only models to generate explanations that better reflect model computation. Results show 32% improved faithfulness, 35-39% stronger locality/sparsity, and the most stable attributions, supporting more transparent and auditable ASR.
VLA-Forget: Vision-Language-Action Unlearning for Embodied Foundation Models
Apr 05, 2026Vision-language-action (VLA) models are emerging as embodied foundation models for robotic manipulation, but their deployment introduces a new unlearning challenge: removing unsafe, spurious, or privacy-sensitive behaviors without degrading perception, language grounding, and action control. In OpenVLA-style policies, behavior is produced through a fused visual encoder, a cross-modal projector, and a language backbone that predicts tokenized robot actions, so undesirable knowledge can be distributed across perception, alignment, and reasoning/action layers rather than confined to a single module. Consequently, partial unlearning applied only to the vision stack or only to the language backbone is often insufficient, while conventional unlearning baselines designed for standalone vision or language models may leave residual forgetting or incur unnecessary utility loss in embodied settings. We propose VLA-Forget, a hybrid unlearning framework that combines ratio-aware selective editing for perception and cross-modal specificity with layer-selective reasoning/action unlearning for utility-preserving forgetting. VLA-Forget jointly optimizes three objectives: targeted forgetting, perceptual preservation, and reasoning retention, through staged updates over the visual encoder, projector, and upper action-generating transformer blocks. Across forget-set behavior probes and retain-task evaluations, VLA-Forget improves forgetting efficacy by 10%, preserves perceptual specificity by 22%, retains reasoning and task success by 9%, and reduces post-quantization recovery by 55% relative to strong unlearning baselines.
G-Drift MIA: Membership Inference via Gradient-Induced Feature Drift in LLMs
Apr 01, 2026Large language models (LLMs) are trained on massive web-scale corpora, raising growing concerns about privacy and copyright. Membership inference attacks (MIAs) aim to determine whether a given example was used during training. Existing LLM MIAs largely rely on output probabilities or loss values and often perform only marginally better than random guessing when members and non-members are drawn from the same distribution. We introduce G-Drift MIA, a white-box membership inference method based on gradient-induced feature drift. Given a candidate (x,y), we apply a single targeted gradient-ascent step that increases its loss and measure the resulting changes in internal representations, including logits, hidden-layer activations, and projections onto fixed feature directions, before and after the update. These drift signals are used to train a lightweight logistic classifier that effectively separates members from non-members. Across multiple transformer-based LLMs and datasets derived from realistic MIA benchmarks, G-Drift substantially outperforms confidence-based, perplexity-based, and reference-based attacks. We further show that memorized training samples systematically exhibit smaller and more structured feature drift than non-members, providing a mechanistic link between gradient geometry, representation stability, and memorization. In general, our results demonstrate that small, controlled gradient interventions offer a practical tool for auditing the membership of training-data and assessing privacy risks in LLMs.
CatRAG: Functor-Guided Structural Debiasing with Retrieval Augmentation for Fair LLMs
Mar 23, 2026Large Language Models (LLMs) are deployed in high-stakes settings but can show demographic, gender, and geographic biases that undermine fairness and trust. Prior debiasing methods, including embedding-space projections, prompt-based steering, and causal interventions, often act at a single stage of the pipeline, resulting in incomplete mitigation and brittle utility trade-offs under distribution shifts. We propose CatRAG Debiasing, a dual-pronged framework that integrates functor with Retrieval-Augmented Generation (RAG) guided structural debiasing. The functor component leverages category-theoretic structure to induce a principled, structure-preserving projection that suppresses bias-associated directions in the embedding space while retaining task-relevant semantics. On the Bias Benchmark for Question Answering (BBQ) across three open-source LLMs (Meta Llama-3, OpenAI GPT-OSS, and Google Gemma-3), CatRAG achieves state-of-the-art results, improving accuracy by up to 40% over the corresponding base models and by more than 10% over prior debiasing methods, while reducing bias scores to near zero (from 60% for the base models) across gender, nationality, race, and intersectional subgroups.
Embodied Foundation Models at the Edge: A Survey of Deployment Constraints and Mitigation Strategies
Mar 19, 2026Deploying foundation models in embodied edge systems is fundamentally a systems problem, not just a problem of model compression. Real-time control must operate within strict size, weight, and power constraints, where memory traffic, compute latency, timing variability, and safety margins interact directly. The Deployment Gauntlet organizes these constraints into eight coupled barriers that determine whether embodied foundation models can run reliably in practice. Across representative edge workloads, autoregressive Vision-Language-Action policies are constrained primarily by memory bandwidth, whereas diffusion-based controllers are limited more by compute latency and sustained execution cost. Reliable deployment therefore depends on system-level co-design across memory, scheduling, communication, and model architecture, including decompositions that separate fast control from slower semantic reasoning.
RAZOR: Ratio-Aware Layer Editing for Targeted Unlearning in Vision Transformers and Diffusion Models
Mar 16, 2026Transformer based diffusion and vision-language models have achieved remarkable success; yet, efficiently removing undesirable or sensitive information without retraining remains a central challenge for model safety and compliance. We introduce Ratio-Aware Zero/One-step Optimized Retentive unlearning (RAZOR), a lightweight, model-agnostic unlearning framework that generalizes forgetting updates to coordinated multi-layer and multi-head edits within transformer backbones. RAZOR identifies the most important layers and attention heads by measuring how much they contribute to forgetting the target data while preserving useful knowledge. Then, it updates these parts of the model using a carefully regularized rule to avoid harming overall performance. The set of edited components grows gradually, ensuring precise unlearning without over-editing or damaging unrelated capabilities. We evaluate RAZOR on CLIP, Stable Diffusion, and vision-language models (VLMs) using widely adopted unlearning benchmarks covering identity, style, and object erasure tasks. Our results show that RAZOR achieves highly accurate and stable forgetting, even under quantization. This approach offers stronger retention and better efficiency than prior methods. Notably, it also operates significant faster than conventional techniques. These results demonstrate that RAZOR is a practical and scalable solution for safe, adaptive unlearning in transformer-based vision models.
How Good Are Large Language Models for Course Recommendation in MOOCs?
Apr 11, 2025



Large Language Models (LLMs) have made significant strides in natural language processing and are increasingly being integrated into recommendation systems. However, their potential in educational recommendation systems has yet to be fully explored. This paper investigates the use of LLMs as a general-purpose recommendation model, leveraging their vast knowledge derived from large-scale corpora for course recommendation tasks. We explore a variety of approaches, ranging from prompt-based methods to more advanced fine-tuning techniques, and compare their performance against traditional recommendation models. Extensive experiments were conducted on a real-world MOOC dataset, evaluating using LLMs as course recommendation systems across key dimensions such as accuracy, diversity, and novelty. Our results demonstrate that LLMs can achieve good performance comparable to traditional models, highlighting their potential to enhance educational recommendation systems. These findings pave the way for further exploration and development of LLM-based approaches in the context of educational recommendations.
FaiREO: User Group Fairness for Equality of Opportunity in Course Recommendation
Sep 13, 2021

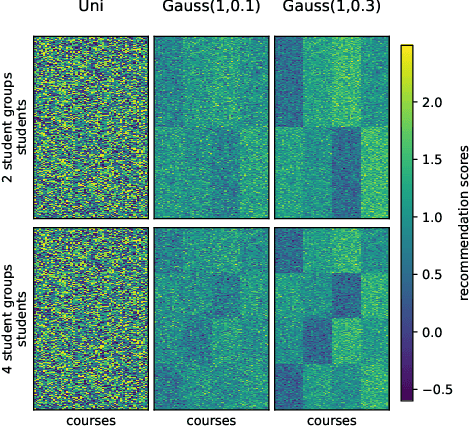
Course selection is challenging for students in higher educational institutions. Existing course recommendation systems make relevant suggestions to the students and help them in exploring the available courses. The recommended courses can influence students' choice of degree program, future employment, and even their socioeconomic status. This paper focuses on identifying and alleviating biases that might be present in a course recommender system. We strive to promote balanced opportunities with our suggestions to all groups of students. At the same time, we need to make recommendations of good quality to all protected groups. We formulate our approach as a multi-objective optimization problem and study the trade-offs between equal opportunity and quality. We evaluate our methods using both real-world and synthetic datasets. The results indicate that we can considerably improve fairness regarding equality of opportunity, but we will introduce some quality loss. Out of the four methods we tested, GHC-Inc and GHC-Tabu are the best performing ones with different advantageous characteristics.