 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-view Multi-task Learning Framework for Multi-variate Time Series Forecasting
Sep 02, 2021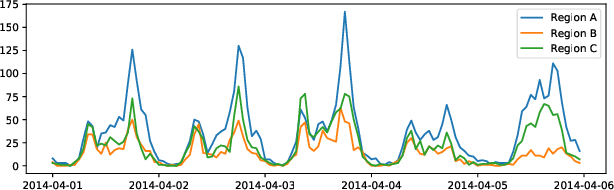

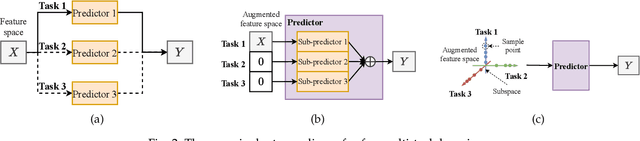

Multi-variate time series (MTS) data is a ubiquitous class of data abstraction in the real world. Any instance of MTS is generated from a hybrid dynamical system and their specific dynamics are usually unknown. The hybrid nature of such a dynamical system is a result of complex external attributes, such as geographic location and time of day, each of which can be categorized into either spatial attributes or temporal attributes. Therefore, there are two fundamental views which can be used to analyze MTS data, namely the spatial view and the temporal view. Moreover, from each of these two views, we can partition the set of data samples of MTS into disjoint forecasting tasks in accordance with their associated attribute values. Then, samples of the same task will manifest similar forthcoming pattern, which is less sophisticated to be predicted in comparison with the original single-view setting. Considering this insight, we propose a novel multi-view multi-task (MVMT) learning framework for MTS forecasting. Instead of being explicitly presented in most scenarios, MVMT information is deeply concealed in the MTS data, which severely hinders the model from capturing it naturally. To this end, we develop two kinds of basic operations, namely task-wise affine transformation and task-wise normalization, respectively. Applying these two operations with prior knowledge on the spatial and temporal view allows the model to adaptively extract MVMT information while predicting. Extensive experiments on three datasets are conducted to illustrate that canonical architectures can be greatly enhanced by the MVMT learning framework in terms of both effectiveness and efficiency. In addition, we design rich case studies to reveal the properties of representations produced at different phases in the entire prediction procedure.
Understand me, if you refer to Aspect Knowledge: Knowledge-aware Gated Recurrent Memory Network
Aug 05, 2021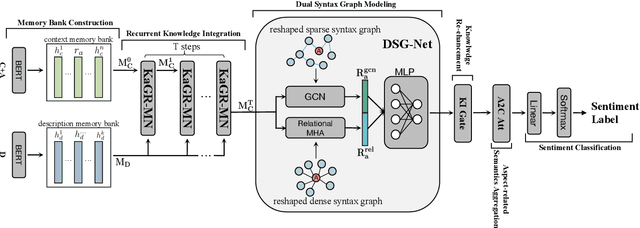
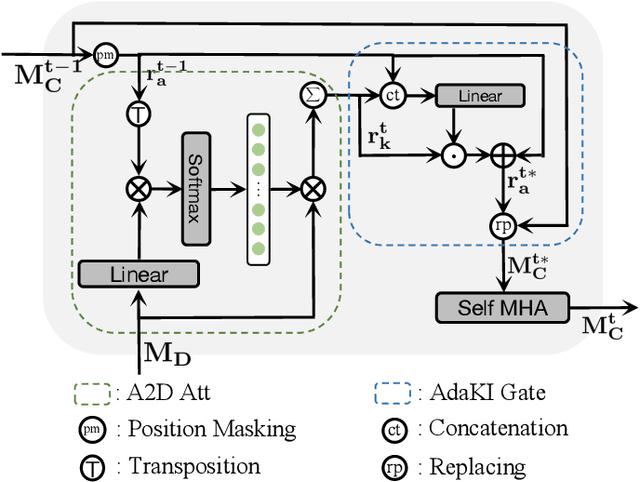
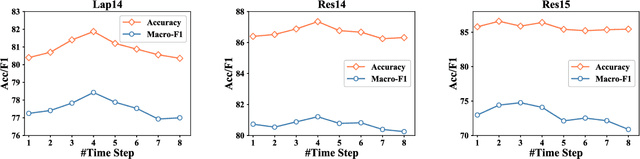
Aspect-level sentiment classification (ASC) aims to predict the fine-grained sentiment polarity towards a given aspect mentioned in a review. Despite recent advances in ASC, enabling machines to preciously infer aspect sentiments is still challenging. This paper tackles two challenges in ASC: (1) due to lack of aspect knowledge, aspect representation derived in prior works is inadequate to represent aspect's exact meaning and property information; (2) prior works only capture either local syntactic information or global relational information, thus missing either one of them leads to insufficient syntactic information. To tackle these challenges, we propose a novel ASC model which not only end-to-end embeds and leverages aspect knowledge but also marries the two kinds of syntactic information and lets them compensate for each other. Our model includes three key components: (1) a knowledge-aware gated recurrent memory network recurrently integrates dynamically summarized aspect knowledge; (2) a dual syntax graph network combines both kinds of syntactic information to comprehensively capture sufficient syntactic information; (3) a knowledge integrating gate re-enhances the final representation with further needed aspect knowledge; (4) an aspect-to-context attention mechanism aggregates the aspect-related semantics from all hidden states into the final representation. Experimental results on several benchmark datasets demonstrate the effectiveness of our model, which overpass previous state-of-the-art models by large margins in terms of both Accuracy and Macro-F1.
Differential-Critic GAN: Generating What You Want by a Cue of Preferences
Jul 14, 2021


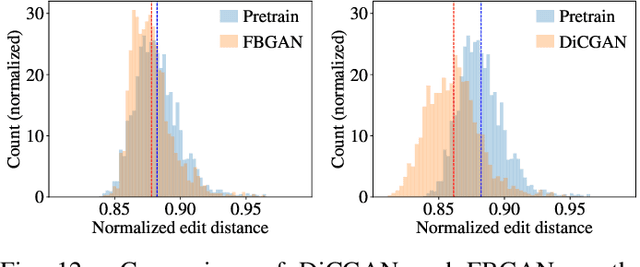
This paper proposes Differential-Critic Generative Adversarial Network (DiCGAN) to learn the distribution of user-desired data when only partial instead of the entire dataset possesses the desired property, which generates desired data that meets user's expectations and can assist in designing biological products with desired properties. Existing approaches select the desired samples first and train regular GANs on the selected samples to derive the user-desired data distribution. However, the selection of the desired data relies on an expert criterion and supervision over the entire dataset. DiCGAN introduces a differential critic that can learn the preference direction from the pairwise preferences, which is amateur knowledge and can be defined on part of the training data. The resultant critic guides the generation of the desired data instead of the whole data. Specifically, apart from the Wasserstein GAN loss, a ranking loss of the pairwise preferences is defined over the critic. It endows the difference of critic values between each pair of samples with the pairwise preference relation. The higher critic value indicates that the sample is preferred by the user. Thus training the generative model for higher critic values encourages the generation of user-preferred samples. Extensive experiments show that our DiCGAN achieves state-of-the-art performance in learning the user-desired data distributions, especially in the cases of insufficient desired data and limited supervision.
Online Multi-Agent Forecasting with Interpretable Collaborative Graph Neural Network
Jul 02, 2021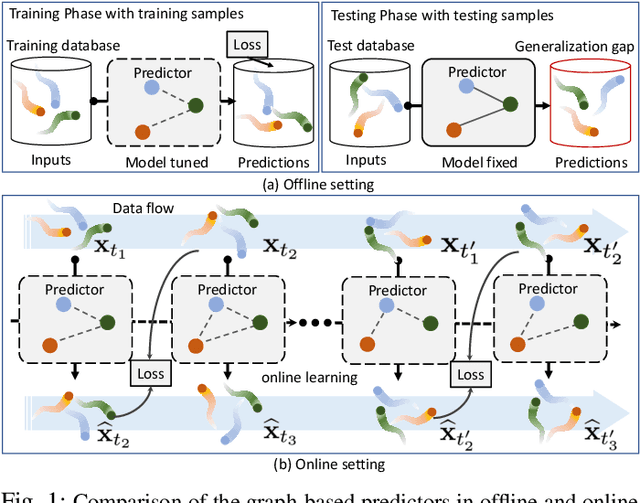
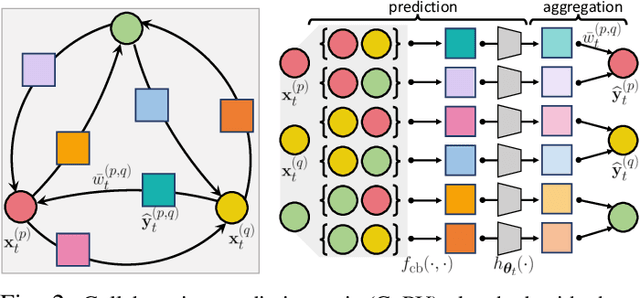

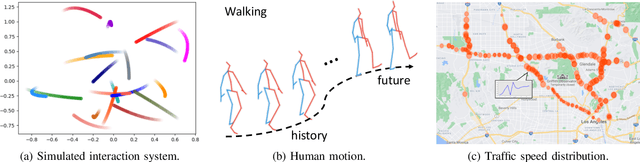
This paper considers predicting future statuses of multiple agents in an online fashion by exploiting dynamic interactions in the system. We propose a novel collaborative prediction unit (CoPU), which aggregates the predictions from multiple collaborative predictors according to a collaborative graph. Each collaborative predictor is trained to predict the status of an agent by considering the impact of another agent. The edge weights of the collaborative graph reflect the importance of each predictor. The collaborative graph is adjusted online by multiplicative update, which can be motivated by minimizing an explicit objective. With this objective, we also conduct regret analysis to indicate that, along with training, our CoPU achieves similar performance with the best individual collaborative predictor in hindsight. This theoretical interpretability distinguishes our method from many other graph networks. To progressively refine predictions, multiple CoPUs are stacked to form a collaborative graph neural network. Extensive experiments are conducted on three tasks: online simulated trajectory prediction, online human motion prediction and online traffic speed prediction, and our methods outperform state-of-the-art works on the three tasks by 28.6%, 17.4% and 21.0% on average, respectively.
Out of Context: A New Clue for Context Modeling of Aspect-based Sentiment Analysis
Jun 21, 2021
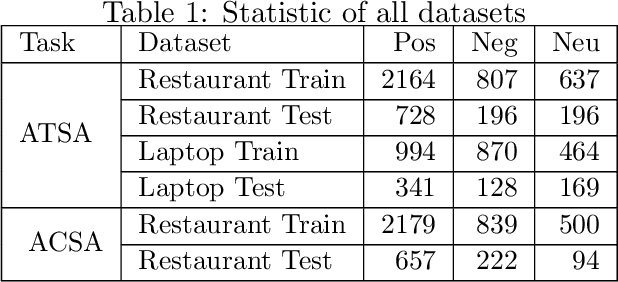

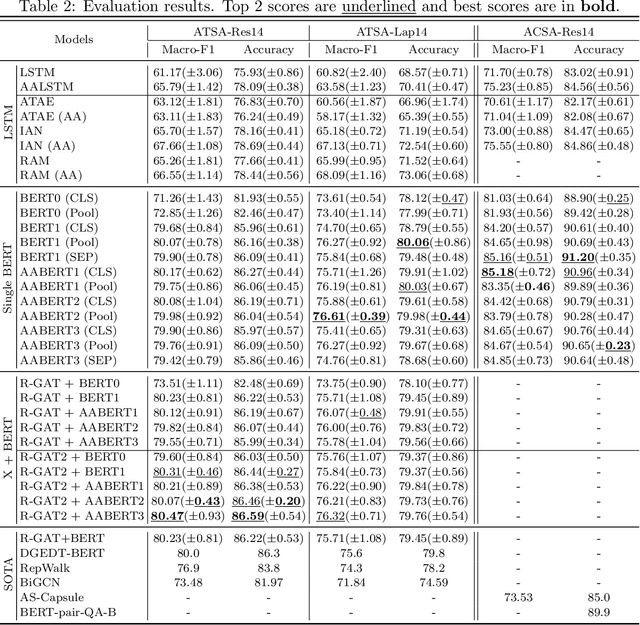
Aspect-based sentiment analysis (ABSA) aims to predict the sentiment expressed in a review with respect to a given aspect. The core of ABSA is to model the interaction between the context and given aspect to extract the aspect-related information. In prior work, attention mechanisms and dependency graph networks are commonly adopted to capture the relations between the context and given aspect. And the weighted sum of context hidden states is used as the final representation fed to the classifier. However, the information related to the given aspect may be already discarded and adverse information may be retained in the context modeling processes of existing models. This problem cannot be solved by subsequent modules and there are two reasons: first, their operations are conducted on the encoder-generated context hidden states, whose value cannot change after the encoder; second, existing encoders only consider the context while not the given aspect. To address this problem, we argue the given aspect should be considered as a new clue out of context in the context modeling process. As for solutions, we design several aspect-aware context encoders based on different backbones: an aspect-aware LSTM and three aspect-aware BERTs. They are dedicated to generate aspect-aware hidden states which are tailored for ABSA task. In these aspect-aware context encoders, the semantics of the given aspect is used to regulate the information flow. Consequently, the aspect-related information can be retained and aspect-irrelevant information can be excluded in the generated hidden states. We conduct extensive experiments on several benchmark datasets with empirical analysis, demonstrating the efficacies and advantages of our proposed aspect-aware context encoders.
Bayesian Active Learning by Disagreements: A Geometric Perspective
May 06, 2021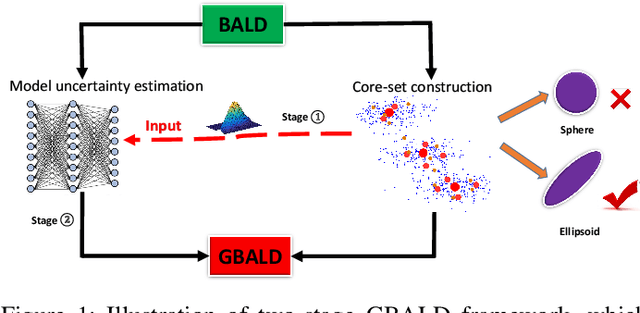

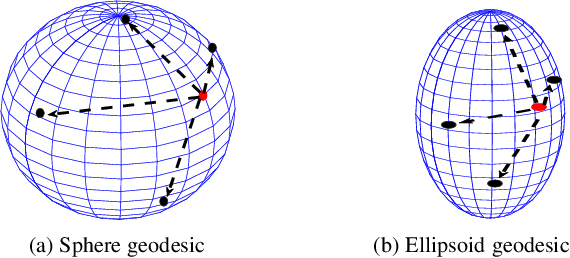
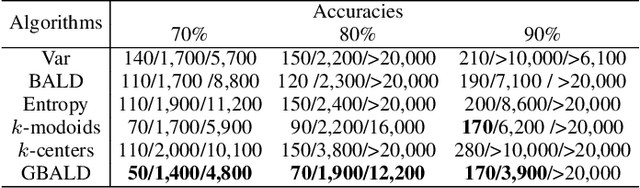
We present geometric Bayesian active learning by disagreements (GBALD), a framework that performs BALD on its core-set construction interacting with model uncertainty estimation. Technically, GBALD constructs core-set on ellipsoid, not typical sphere, preventing low-representative elements from spherical boundaries. The improvements are twofold: 1) relieve uninformative prior and 2) reduce redundant estimations. Theoretically, geodesic search with ellipsoid can derive tighter lower bound on error and easier to achieve zero error than with sphere. Experiments show that GBALD has slight perturbations to noisy and repeated samples, and outperforms BALD, BatchBALD and other existing deep active learning approaches.
Distribution Matching for Machine Teaching
May 06, 2021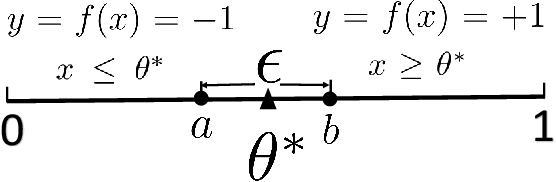
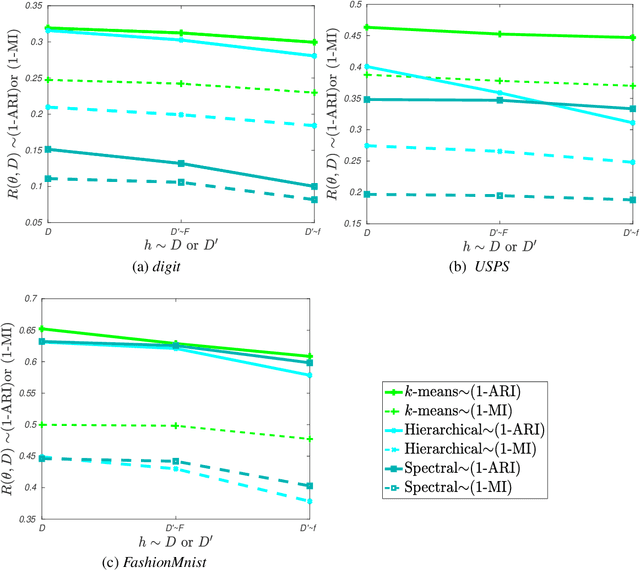
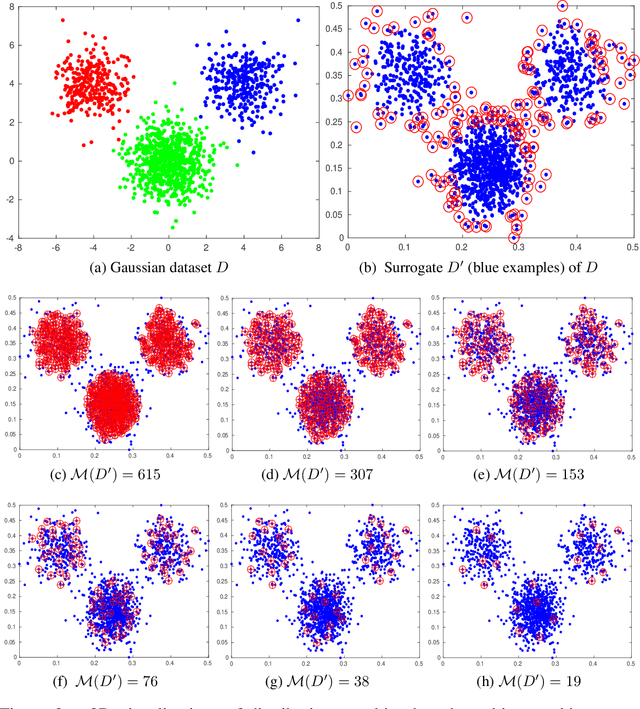
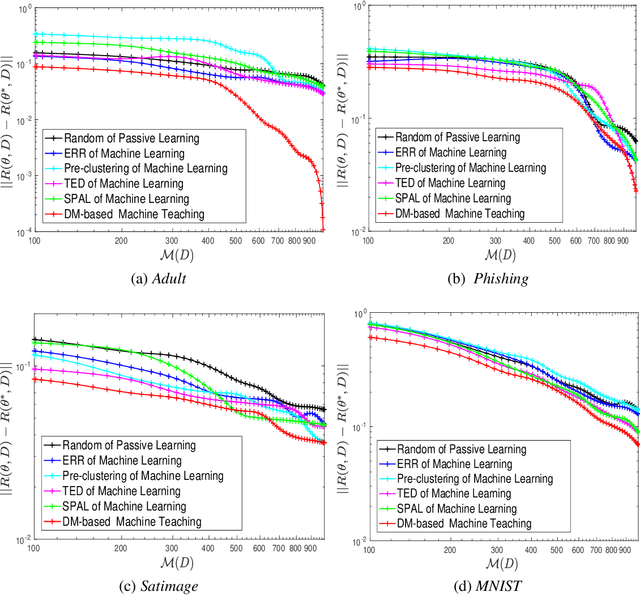
Machine teaching is an inverse problem of machine learning that aims at steering the student learner towards its target hypothesis, in which the teacher has already known the student's learning parameters. Previous studies on machine teaching focused on balancing the teaching risk and cost to find those best teaching examples deriving the student model. This optimization solver is in general ineffective when the student learner does not disclose any cue of the learning parameters. To supervise such a teaching scenario, this paper presents a distribution matching-based machine teaching strategy. Specifically, this strategy backwardly and iteratively performs the halving operation on the teaching cost to find a desired teaching set. Technically, our strategy can be expressed as a cost-controlled optimization process that finds the optimal teaching examples without further exploring in the parameter distribution of the student learner. Then, given any a limited teaching cost, the training examples will be closed-form. Theoretical analysis and experiment results demonstrate this strategy.
The Emerging Trends of Multi-Label Learning
Dec 02, 2020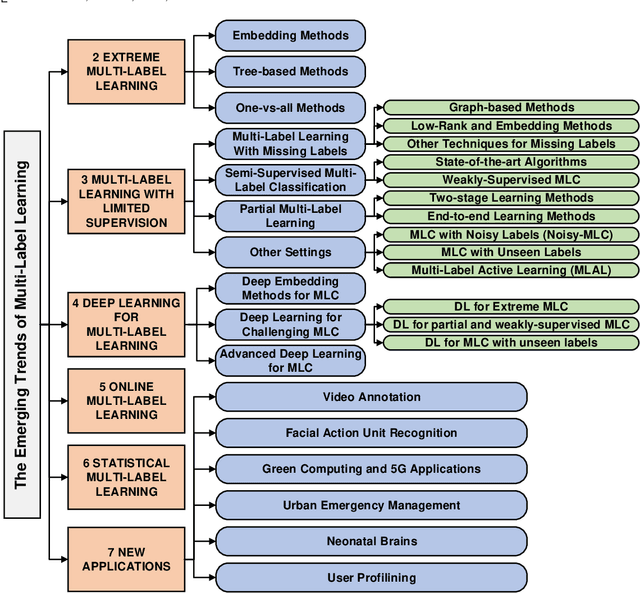
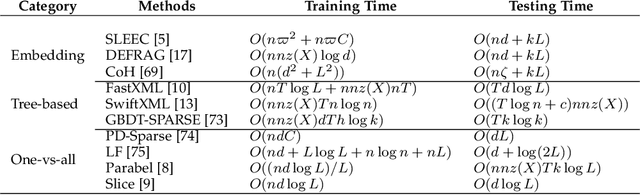


Exabytes of data are generated daily by humans, leading to the growing need for new efforts in dealing with the grand challenges for multi-label learning brought by big data. For example, extreme multi-label classification is an active and rapidly growing research area that deals with classification tasks with an extremely large number of classes or labels; utilizing massive data with limited supervision to build a multi-label classification model becomes valuable for practical applications, etc. Besides these, there are tremendous efforts on how to harvest the strong learning capability of deep learning to better capture the label dependencies in multi-label learning, which is the key for deep learning to address real-world classification tasks. However, it is noted that there has been a lack of systemic studies that focus explicitly on analyzing the emerging trends and new challenges of multi-label learning in the era of big data. It is imperative to call for a comprehensive survey to fulfill this mission and delineate future research directions and new applications.
A Survey of Label-noise Representation Learning: Past, Present and Future
Nov 09, 2020
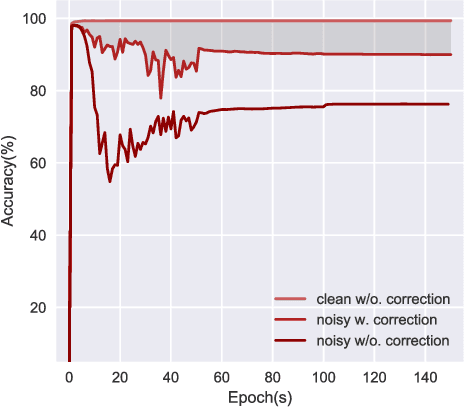
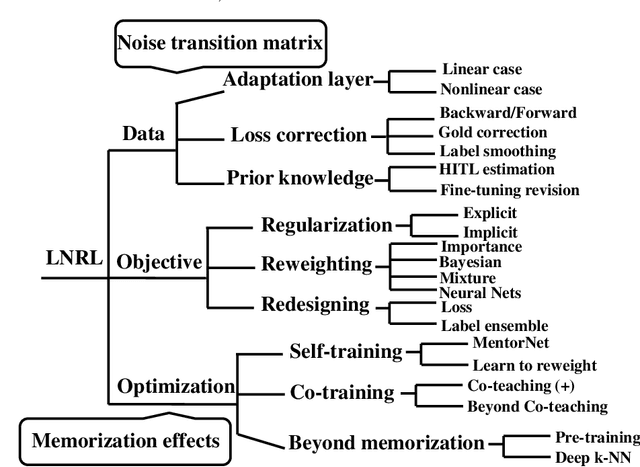
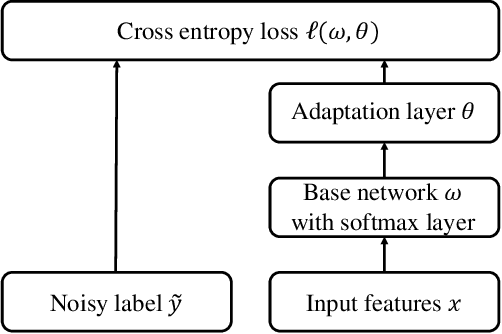
Classical machine learning implicitly assumes that labels of the training data are sampled from a clean distribution, which can be too restrictive for real-world scenarios. However, statistical learning-based methods may not train deep learning models robustly with these noisy labels. Therefore, it is urgent to design Label-Noise Representation Learning (LNRL) methods for robustly training deep models with noisy labels. To fully understand LNRL, we conduct a survey study. We first clarify a formal definition for LNRL from the perspective of machine learning. Then, via the lens of learning theory and empirical study, we figure out why noisy labels affect deep models' performance. Based on the theoretical guidance, we categorize different LNRL methods into three directions. Under this unified taxonomy, we provide a thorough discussion of the pros and cons of different categories. More importantly, we summarize the essential components of robust LNRL, which can spark new directions. Lastly, we propose possible research directions within LNRL, such as new datasets, instance-dependent LNRL, and adversarial LNRL. Finally, we envision potential directions beyond LNRL, such as learning with feature-noise, preference-noise, domain-noise, similarity-noise, graph-noise, and demonstration-noise.
Subgroup-based Rank-1 Lattice Quasi-Monte Carlo
Oct 29, 2020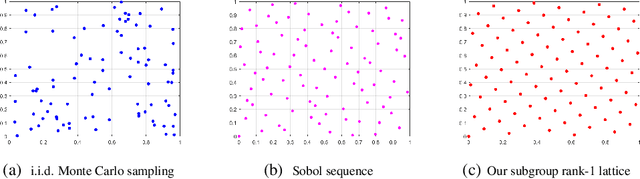
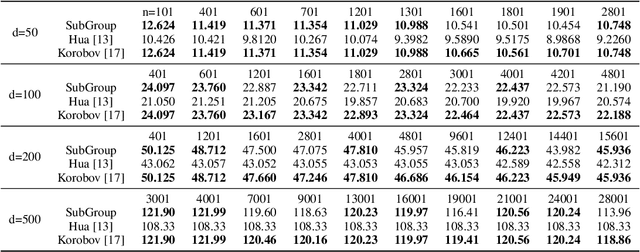
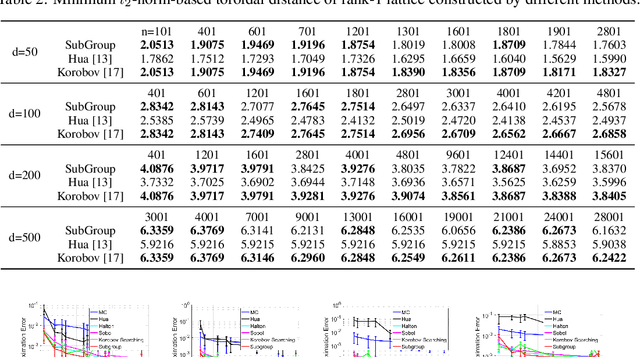
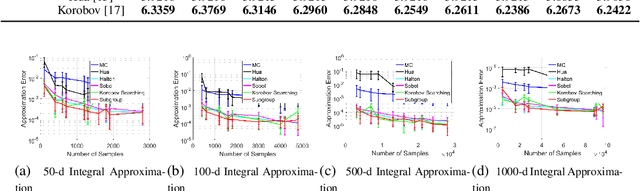
Quasi-Monte Carlo (QMC) is an essential tool for integral approximation, Bayesian inference, and sampling for simulation in science, etc. In the QMC area, the rank-1 lattice is important due to its simple operation, and nice properties for point set construction. However, the construction of the generating vector of the rank-1 lattice is usually time-consuming because of an exhaustive computer search. To address this issue, we propose a simple closed-form rank-1 lattice construction method based on group theory. Our method reduces the number of distinct pairwise distance values to generate a more regular lattice. We theoretically prove a lower and an upper bound of the minimum pairwise distance of any non-degenerate rank-1 lattice. Empirically, our methods can generate a near-optimal rank-1 lattice compared with the Korobov exhaustive search regarding the $l_1$-norm and $l_2$-norm minimum distance. Moreover, experimental results show that our method achieves superior approximation performance on benchmark integration test problems and kernel approximation problems.