 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenSelect: A Generative Approach to Best-of-N
Jul 23, 2025Generative reward models with parallel sampling have enabled effective test-time scaling for reasoning tasks. Current approaches employ pointwise scoring of individual solutions or pairwise comparisons. However, pointwise methods underutilize LLMs' comparative abilities, while pairwise methods scale inefficiently with larger sampling budgets. We introduce GenSelect, where the LLM uses long reasoning to select the best solution among N candidates. This leverages LLMs' comparative strengths while scaling efficiently across parallel sampling budgets. For math reasoning, we demonstrate that reasoning models, such as QwQ and DeepSeek-R1-0528, excel at GenSelect, outperforming existing scoring approaches with simple prompting.
AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset
Apr 23, 2025



This paper presents our winning submission to the AI Mathematical Olympiad - Progress Prize 2 (AIMO-2) competition. Our recipe for building state-of-the-art mathematical reasoning models relies on three key pillars. First, we create a large-scale dataset comprising 540K unique high-quality math problems, including olympiad-level problems, and their 3.2M long-reasoning solutions. Second, we develop a novel method to integrate code execution with long reasoning models through iterative training, generation, and quality filtering, resulting in 1.7M high-quality Tool-Integrated Reasoning solutions. Third, we create a pipeline to train models to select the most promising solution from many candidates. We show that such generative solution selection (GenSelect) can significantly improve upon majority voting baseline. Combining these ideas, we train a series of models that achieve state-of-the-art results on mathematical reasoning benchmarks. To facilitate further research, we release our code, models, and the complete OpenMathReasoning dataset under a commercially permissive license.
Winning Amazon KDD Cup'24
Aug 05, 2024



This paper describes the winning solution of all 5 tasks for the Amazon KDD Cup 2024 Multi Task Online Shopping Challenge for LLMs. The challenge was to build a useful assistant, answering questions in the domain of online shopping. The competition contained 57 diverse tasks, covering 5 different task types (e.g. multiple choice) and across 4 different tracks (e.g. multi-lingual). Our solution is a single model per track. We fine-tune Qwen2-72B-Instruct on our own training dataset. As the competition released only 96 example questions, we developed our own training dataset by processing multiple public datasets or using Large Language Models for data augmentation and synthetic data generation. We apply wise-ft to account for distribution shifts and ensemble multiple LoRA adapters in one model. We employed Logits Processors to constrain the model output on relevant tokens for the tasks. AWQ 4-bit Quantization and vLLM are used during inference to predict the test dataset in the time constraints of 20 to 140 minutes depending on the track. Our solution achieved the first place in each individual track and is the first place overall of Amazons KDD Cup 2024.
Target-Speaker Voice Activity Detection: a Novel Approach for Multi-Speaker Diarization in a Dinner Party Scenario
May 14, 2020
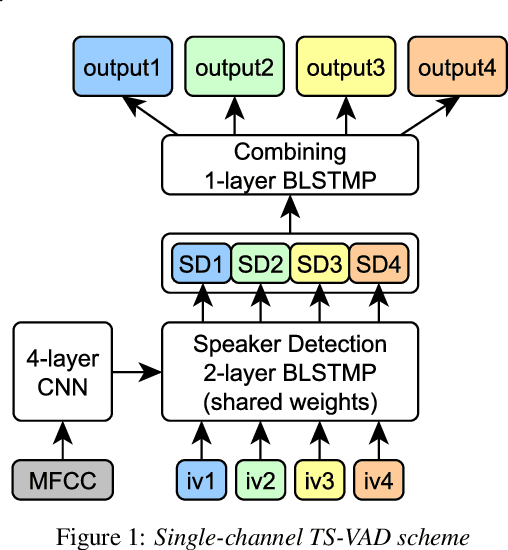
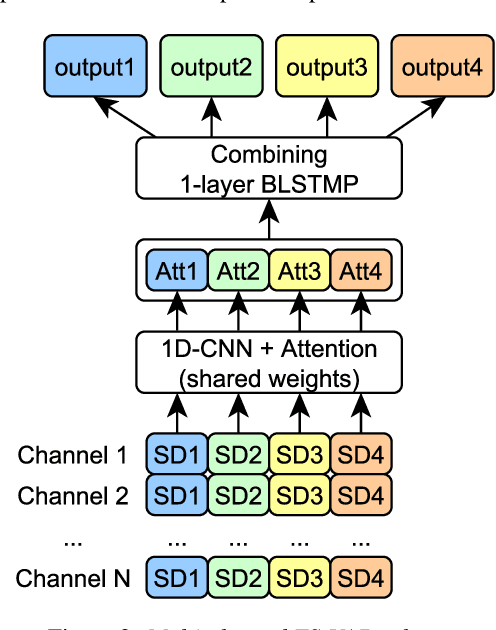
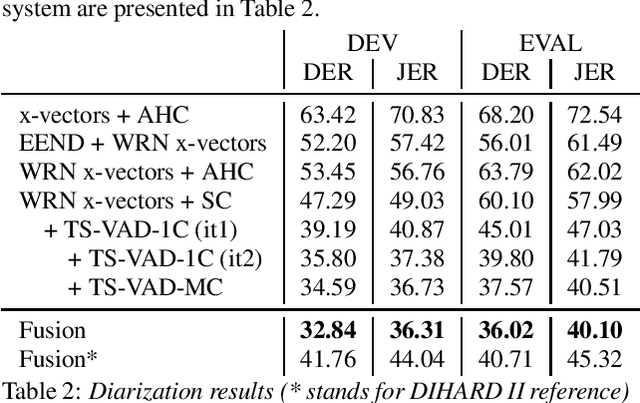
Speaker diarization for real-life scenarios is an extremely challenging problem. Widely used clustering-based diarization approaches perform rather poorly in such conditions, mainly due to the limited ability to handle overlapping speech. We propose a novel Target-Speaker Voice Activity Detection (TS-VAD) approach, which directly predicts an activity of each speaker on each time frame. TS-VAD model takes conventional speech features (e.g., MFCC) along with i-vectors for each speaker as inputs. A set of binary classification output layers produces activities of each speaker. I-vectors can be estimated iteratively, starting with a strong clustering-based diarization. We also extend the TS-VAD approach to the multi-microphone case using a simple attention mechanism on top of hidden representations extracted from the single-channel TS-VAD model. Moreover, post-processing strategies for the predicted speaker activity probabilities are investigated. Experiments on the CHiME-6 unsegmented data show that TS-VAD achieves state-of-the-art results outperforming the baseline x-vector-based system by more than 30% Diarization Error Rate (DER) abs.
Deep Attention Recurrent Q-Network
Dec 05, 2015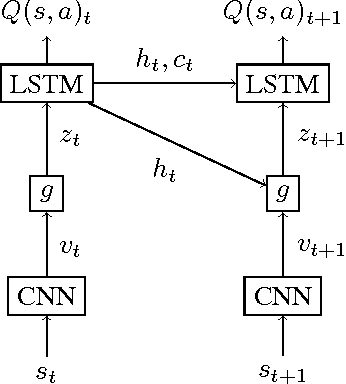
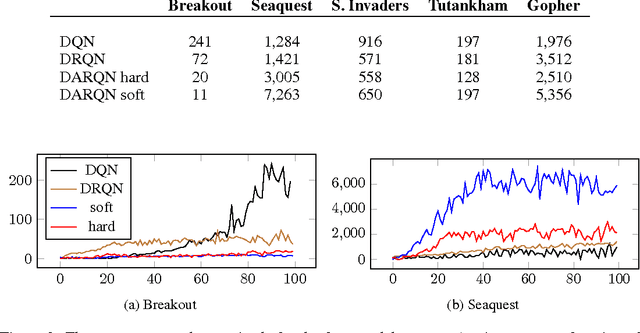


A deep learning approach to reinforcement learning led to a general learner able to train on visual input to play a variety of arcade games at the human and superhuman levels. Its creators at the Google DeepMind's team called the approach: Deep Q-Network (DQN). We present an extension of DQN by "soft" and "hard" attention mechanisms. Tests of the proposed Deep Attention Recurrent Q-Network (DARQN) algorithm on multiple Atari 2600 games show level of performance superior to that of DQN. Moreover, built-in attention mechanisms allow a direct online monitoring of the training process by highlighting the regions of the game screen the agent is focusing on when making decisions.