 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCryfish: On deep audio analysis with Large Language Models
Aug 18, 2025The recent revolutionary progress in text-based large language models (LLMs) has contributed to the growth of interest in extending capabilities of such models to multimodal perception and understanding tasks. Hearing is an essential capability that is highly desired to be integrated into LLMs. However, effective integrating listening capabilities into LLMs is a significant challenge lying in generalizing complex auditory tasks across speech and sounds. To address these issues, we introduce Cryfish, our version of auditory-capable LLM. The model integrates WavLM audio-encoder features into Qwen2 model using a transformer-based connector. Cryfish is adapted to various auditory tasks through a specialized training strategy. We evaluate the model on the new Dynamic SUPERB Phase-2 comprehensive multitask benchmark specifically designed for auditory-capable models. The paper presents an in-depth analysis and detailed comparison of Cryfish with the publicly available models.
STCON System for the CHiME-8 Challenge
Oct 17, 2024



This paper describes the STCON system for the CHiME-8 Challenge Task 1 (DASR) aimed at distant automatic speech transcription and diarization with multiple recording devices. Our main attention was paid to carefully trained and tuned diarization pipeline and speaker counting. This allowed to significantly reduce diarization error rate (DER) and obtain more reliable segments for speech separation and recognition. To improve source separation, we designed a Guided Target speaker Extraction (G-TSE) model and used it in conjunction with the traditional Guided Source Separation (GSS) method. To train various parts of our pipeline, we investigated several data augmentation and generation techniques, which helped us to improve the overall system quality.
Target-Speaker Voice Activity Detection: a Novel Approach for Multi-Speaker Diarization in a Dinner Party Scenario
May 14, 2020
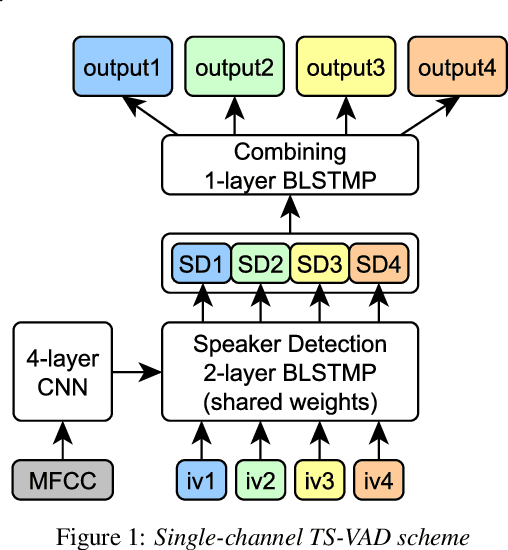
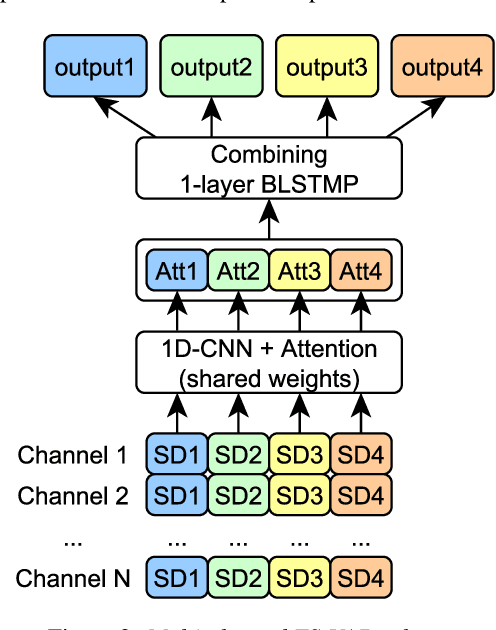
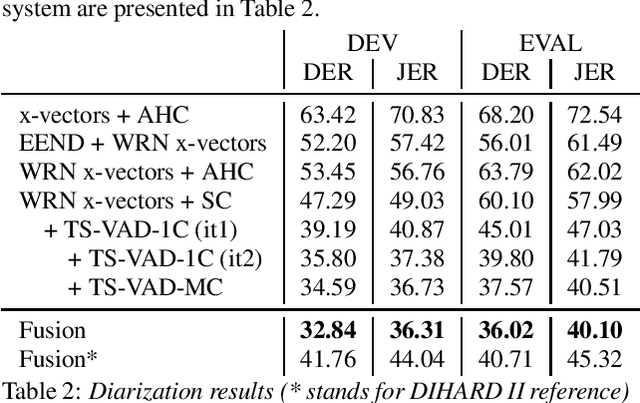
Speaker diarization for real-life scenarios is an extremely challenging problem. Widely used clustering-based diarization approaches perform rather poorly in such conditions, mainly due to the limited ability to handle overlapping speech. We propose a novel Target-Speaker Voice Activity Detection (TS-VAD) approach, which directly predicts an activity of each speaker on each time frame. TS-VAD model takes conventional speech features (e.g., MFCC) along with i-vectors for each speaker as inputs. A set of binary classification output layers produces activities of each speaker. I-vectors can be estimated iteratively, starting with a strong clustering-based diarization. We also extend the TS-VAD approach to the multi-microphone case using a simple attention mechanism on top of hidden representations extracted from the single-channel TS-VAD model. Moreover, post-processing strategies for the predicted speaker activity probabilities are investigated. Experiments on the CHiME-6 unsegmented data show that TS-VAD achieves state-of-the-art results outperforming the baseline x-vector-based system by more than 30% Diarization Error Rate (DER) abs.