 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReeM: Ensemble Building Thermodynamics Model for Efficient HVAC Control via Hierarchical Reinforcement Learning
May 05, 2025The building thermodynamics model, which predicts real-time indoor temperature changes under potential HVAC (Heating, Ventilation, and Air Conditioning) control operations, is crucial for optimizing HVAC control in buildings. While pioneering studies have attempted to develop such models for various building environments, these models often require extensive data collection periods and rely heavily on expert knowledge, making the modeling process inefficient and limiting the reusability of the models. This paper explores a model ensemble perspective that utilizes existing developed models as base models to serve a target building environment, thereby providing accurate predictions while reducing the associated efforts. Given that building data streams are non-stationary and the number of base models may increase, we propose a Hierarchical Reinforcement Learning (HRL) approach to dynamically select and weight the base models. Our approach employs a two-tiered decision-making process: the high-level focuses on model selection, while the low-level determines the weights of the selected models. We thoroughly evaluate the proposed approach through offline experiments and an on-site case study, and the experimental results demonstrate the effectiveness of our method.
A Unified Energy Management Framework for Multi-Timescale Forecasting in Smart Grids
Nov 22, 2024



Accurate forecasting of the electrical load, such as the magnitude and the timing of peak power, is crucial to successful power system management and implementation of smart grid strategies like demand response and peak shaving. In multi-time-scale optimization scheduling, rolling optimization is a common solution. However, rolling optimization needs to consider the coupling of different optimization objectives across time scales. It is challenging to accurately capture the mid- and long-term dependencies in time series data. This paper proposes Multi-pofo, a multi-scale power load forecasting framework, that captures such dependency via a novel architecture equipped with a temporal positional encoding layer. To validate the effectiveness of the proposed model, we conduct experiments on real-world electricity load data. The experimental results show that our approach outperforms compared to several strong baseline methods.
Improving Building Temperature Forecasting: A Data-driven Approach with System Scenario Clustering
Feb 21, 2024



Heat, Ventilation and Air Conditioning (HVAC) systems play a critical role in maintaining a comfortable thermal environment and cost approximately 40% of primary energy usage in the building sector. For smart energy management in buildings, usage patterns and their resulting profiles allow the improvement of control systems with prediction capabilities. However, for large-scale HVAC system management, it is difficult to construct a detailed model for each subsystem. In this paper, a new data-driven room temperature prediction model is proposed based on the k-means clustering method. The proposed data-driven temperature prediction approach extracts the system operation feature through historical data analysis and further simplifies the system-level model to improve generalization and computational efficiency. We evaluate the proposed approach in the real world. The results demonstrated that our approach can significantly reduce modeling time without reducing prediction accuracy.
Data-driven HVAC Control Using Symbolic Regression: Design and Implementation
Apr 06, 2023The large amount of data collected in buildings makes energy management smarter and more energy efficient. This study proposes a design and implementation methodology of data-driven heating, ventilation, and air conditioning (HVAC) control. Building thermodynamics is modeled using a symbolic regression model (SRM) built from the collected data. Additionally, an HVAC system model is also developed with a data-driven approach. A model predictive control (MPC) based HVAC scheduling is formulated with the developed models to minimize energy consumption and peak power demand and maximize thermal comfort. The performance of the proposed framework is demonstrated in the workspace in the actual campus building. The HVAC system using the proposed framework reduces the peak power by 16.1\% compared to the widely used thermostat controller.
A Picture May Be Worth a Hundred Words for Visual Question Answering
Jun 25, 2021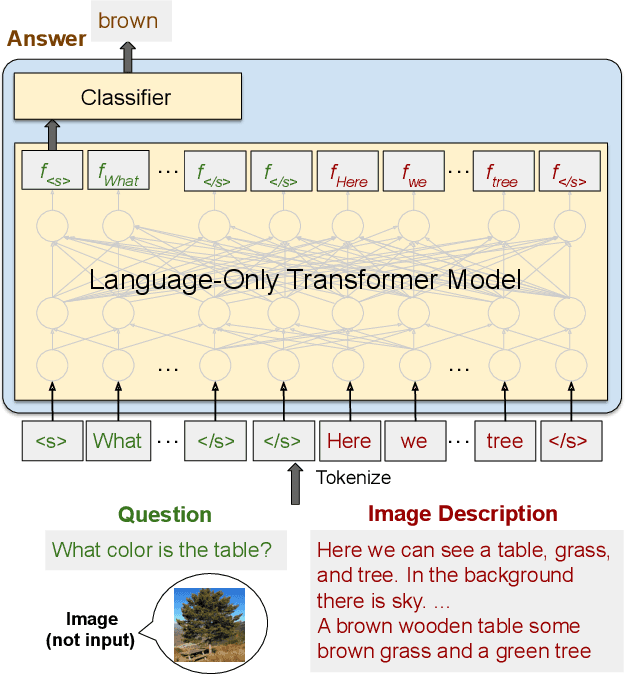

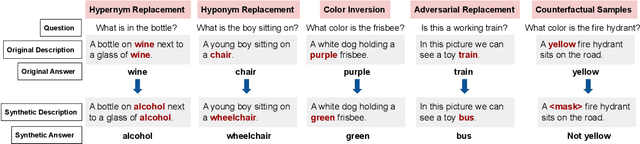
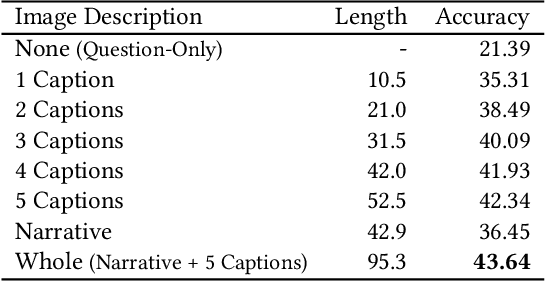
How far can we go with textual representations for understanding pictures? In image understanding, it is essential to use concise but detailed image representations. Deep visual features extracted by vision models, such as Faster R-CNN, are prevailing used in multiple tasks, and especially in visual question answering (VQA). However, conventional deep visual features may struggle to convey all the details in an image as we humans do. Meanwhile, with recent language models' progress, descriptive text may be an alternative to this problem. This paper delves into the effectiveness of textual representations for image understanding in the specific context of VQA. We propose to take description-question pairs as input, instead of deep visual features, and fed them into a language-only Transformer model, simplifying the process and the computational cost. We also experiment with data augmentation techniques to increase the diversity in the training set and avoid learning statistical bias. Extensive evaluations have shown that textual representations require only about a hundred words to compete with deep visual features on both VQA 2.0 and VQA-CP v2.