 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-oriented manipulation of speaker representations
Oct 10, 2023



Speaker embeddings are ubiquitous, with applications ranging from speaker recognition and diarization to speech synthesis and voice anonymisation. The amount of information held by these embeddings lends them versatility, but also raises privacy concerns. Speaker embeddings have been shown to contain information on age, sex, health and more, which speakers may want to keep private, especially when this information is not required for the target task. In this work, we propose a method for removing and manipulating private attributes from speaker embeddings that leverages a Vector-Quantized Variational Autoencoder architecture, combined with an adversarial classifier and a novel mutual information loss. We validate our model on two attributes, sex and age, and perform experiments with ignorant and fully-informed attackers, and with in-domain and out-of-domain data.
Simple LLM Prompting is State-of-the-Art for Robust and Multilingual Dialogue Evaluation
Sep 08, 2023



Despite significant research effort in the development of automatic dialogue evaluation metrics, little thought is given to evaluating dialogues other than in English. At the same time, ensuring metrics are invariant to semantically similar responses is also an overlooked topic. In order to achieve the desired properties of robustness and multilinguality for dialogue evaluation metrics, we propose a novel framework that takes advantage of the strengths of current evaluation models with the newly-established paradigm of prompting Large Language Models (LLMs). Empirical results show our framework achieves state of the art results in terms of mean Spearman correlation scores across several benchmarks and ranks first place on both the Robust and Multilingual tasks of the DSTC11 Track 4 "Automatic Evaluation Metrics for Open-Domain Dialogue Systems", proving the evaluation capabilities of prompted LLMs.
Towards Multilingual Automatic Dialogue Evaluation
Aug 31, 2023



The main limiting factor in the development of robust multilingual dialogue evaluation metrics is the lack of multilingual data and the limited availability of open sourced multilingual dialogue systems. In this work, we propose a workaround for this lack of data by leveraging a strong multilingual pretrained LLM and augmenting existing English dialogue data using Machine Translation. We empirically show that the naive approach of finetuning a pretrained multilingual encoder model with translated data is insufficient to outperform the strong baseline of finetuning a multilingual model with only source data. Instead, the best approach consists in the careful curation of translated data using MT Quality Estimation metrics, excluding low quality translations that hinder its performance.
Privacy-preserving Automatic Speaker Diarization
Oct 26, 2022Automatic Speaker Diarization (ASD) is an enabling technology with numerous applications, which deals with recordings of multiple speakers, raising special concerns in terms of privacy. In fact, in remote settings, where recordings are shared with a server, clients relinquish not only the privacy of their conversation, but also of all the information that can be inferred from their voices. However, to the best of our knowledge, the development of privacy-preserving ASD systems has been overlooked thus far. In this work, we tackle this problem using a combination of two cryptographic techniques, Secure Multiparty Computation (SMC) and Secure Modular Hashing, and apply them to the two main steps of a cascaded ASD system: speaker embedding extraction and agglomerative hierarchical clustering. Our system is able to achieve a reasonable trade-off between performance and efficiency, presenting real-time factors of 1.1 and 1.6, for two different SMC security settings.
Towards End-to-End Private Automatic Speaker Recognition
Jun 23, 2022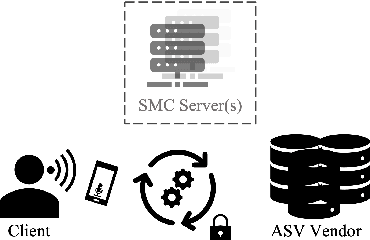

The development of privacy-preserving automatic speaker verification systems has been the focus of a number of studies with the intent of allowing users to authenticate themselves without risking the privacy of their voice. However, current privacy-preserving methods assume that the template voice representations (or speaker embeddings) used for authentication are extracted locally by the user. This poses two important issues: first, knowledge of the speaker embedding extraction model may create security and robustness liabilities for the authentication system, as this knowledge might help attackers in crafting adversarial examples able to mislead the system; second, from the point of view of a service provider the speaker embedding extraction model is arguably one of the most valuable components in the system and, as such, disclosing it would be highly undesirable. In this work, we show how speaker embeddings can be extracted while keeping both the speaker's voice and the service provider's model private, using Secure Multiparty Computation. Further, we show that it is possible to obtain reasonable trade-offs between security and computational cost. This work is complementary to those showing how authentication may be performed privately, and thus can be considered as another step towards fully private automatic speaker recognition.
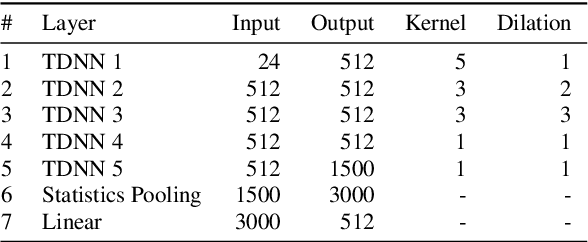
Using Self-Supervised Feature Extractors with Attention for Automatic COVID-19 Detection from Speech
Jun 30, 2021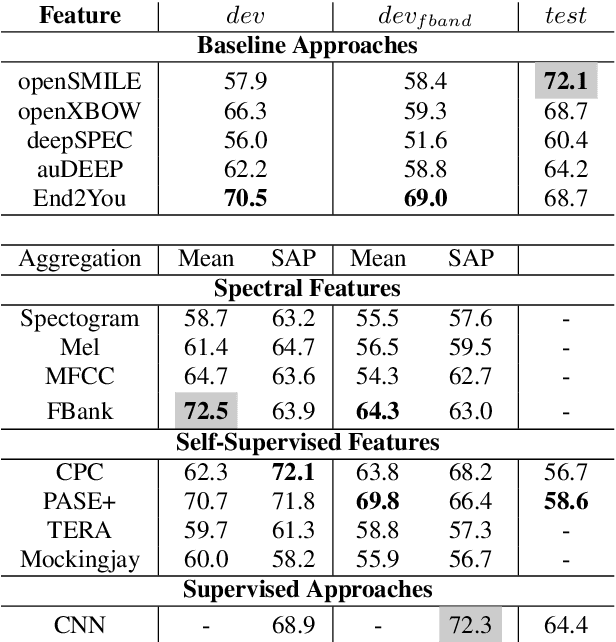
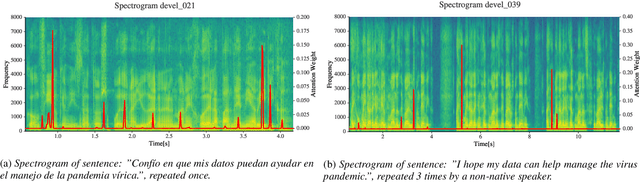
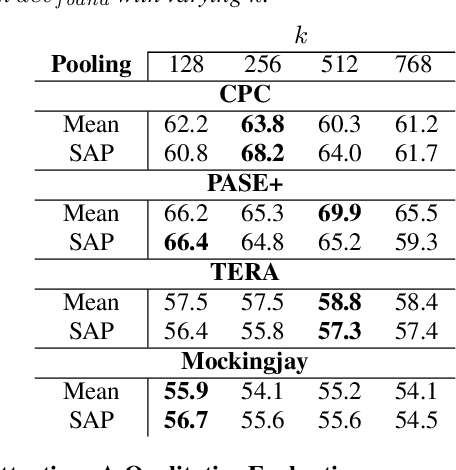
The ComParE 2021 COVID-19 Speech Sub-challenge provides a test-bed for the evaluation of automatic detectors of COVID-19 from speech. Such models can be of value by providing test triaging capabilities to health authorities, working alongside traditional testing methods. Herein, we leverage the usage of pre-trained, problem agnostic, speech representations and evaluate their use for this task. We compare the obtained results against a CNN architecture trained from scratch and traditional frequency-domain representations. We also evaluate the usage of Self-Attention Pooling as an utterance-level information aggregation method. Experimental results demonstrate that models trained on features extracted from self-supervised models perform similarly or outperform fully-supervised models and models based on handcrafted features. Our best model improves the Unweighted Average Recall (UAR) from 69.0\% to 72.3\% on a development set comprised of only full-band examples and achieves 64.4\% on the test set. Furthermore, we study where the network is attending, attempting to draw some conclusions regarding its explainability. In this relatively small dataset, we find the network attends especially to vowels and aspirates.
FoolHD: Fooling speaker identification by Highly imperceptible adversarial Disturbances
Nov 17, 2020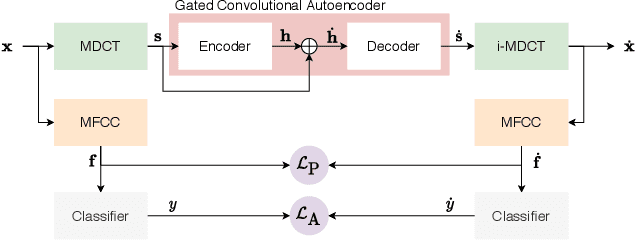
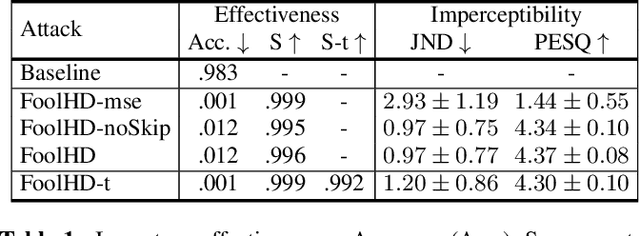
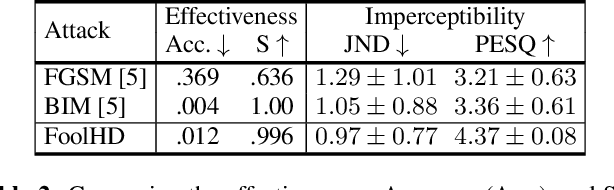
Speaker identification models are vulnerable to carefully designed adversarial perturbations of their input signals that induce misclassification. In this work, we propose a white-box steganography-inspired adversarial attack that generates imperceptible adversarial perturbations against a speaker identification model. Our approach, FoolHD, uses a Gated Convolutional Autoencoder that operates in the DCT domain and is trained with a multi-objective loss function, in order to generate and conceal the adversarial perturbation within the original audio files. In addition to hindering speaker identification performance, this multi-objective loss accounts for human perception through a frame-wise cosine similarity between MFCC feature vectors extracted from the original and adversarial audio files. We validate the effectiveness of FoolHD with a 250-speaker identification x-vector network, trained using VoxCeleb, in terms of accuracy, success rate, and imperceptibility. Our results show that FoolHD generates highly imperceptible adversarial audio files (average PESQ scores above 4.30), while achieving a success rate of 99.6% and 99.2% in misleading the speaker identification model, for untargeted and targeted settings, respectively.
Pathological speech detection using x-vector embeddings
Mar 03, 2020



The potential of speech as a non-invasive biomarker to assess a speaker's health has been repeatedly supported by the results of multiple works, for both physical and psychological conditions. Traditional systems for speech-based disease classification have focused on carefully designed knowledge-based features. However, these features may not represent the disease's full symptomatology, and may even overlook its more subtle manifestations. This has prompted researchers to move in the direction of general speaker representations that inherently model symptoms, such as Gaussian Supervectors, i-vectors and, x-vectors. In this work, we focus on the latter, to assess their applicability as a general feature extraction method to the detection of Parkinson's disease (PD) and obstructive sleep apnea (OSA). We test our approach against knowledge-based features and i-vectors, and report results for two European Portuguese corpora, for OSA and PD, as well as for an additional Spanish corpus for PD. Both x-vector and i-vector models were trained with an out-of-domain European Portuguese corpus. Our results show that x-vectors are able to perform better than knowledge-based features in same-language corpora. Moreover, while x-vectors performed similarly to i-vectors in matched conditions, they significantly outperform them when domain-mismatch occurs.
Assessing User Expertise in Spoken Dialog System Interactions
Jan 18, 2017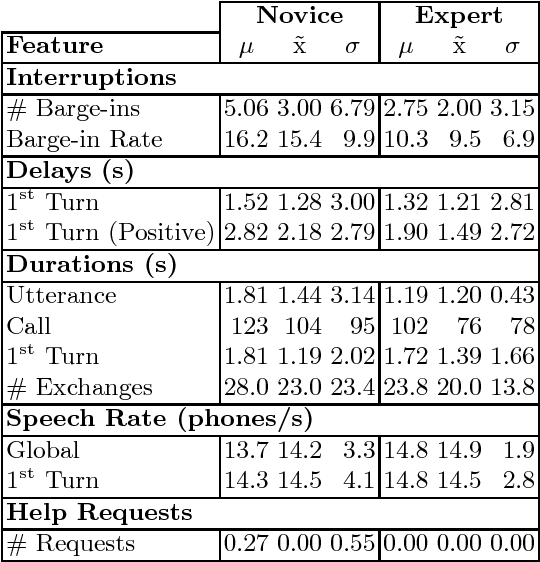
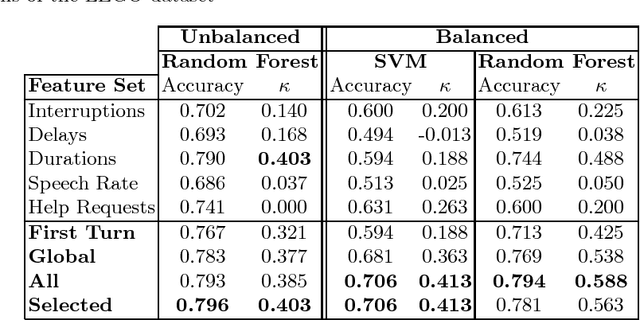
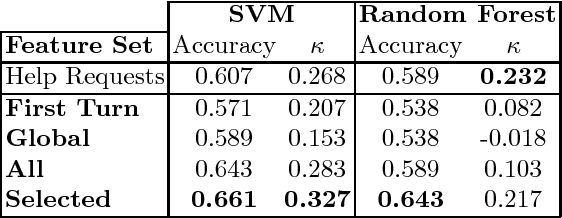
Identifying the level of expertise of its users is important for a system since it can lead to a better interaction through adaptation techniques. Furthermore, this information can be used in offline processes of root cause analysis. However, not much effort has been put into automatically identifying the level of expertise of an user, especially in dialog-based interactions. In this paper we present an approach based on a specific set of task related features. Based on the distribution of the features among the two classes - Novice and Expert - we used Random Forests as a classification approach. Furthermore, we used a Support Vector Machine classifier, in order to perform a result comparison. By applying these approaches on data from a real system, Let's Go, we obtained preliminary results that we consider positive, given the difficulty of the task and the lack of competing approaches for comparison.
* 10 pages
Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation
May 23, 2016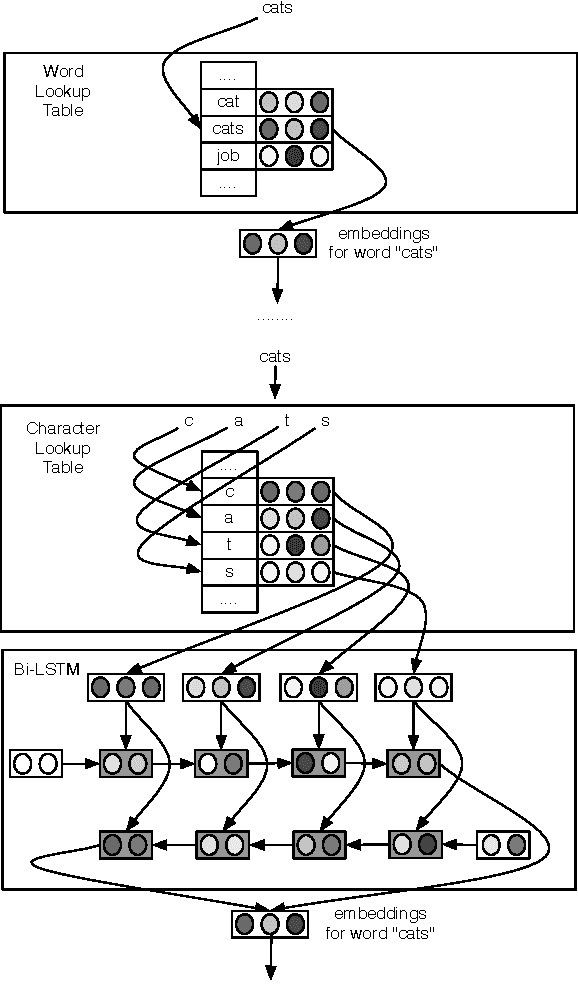
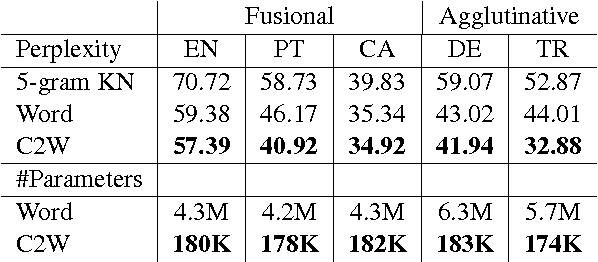
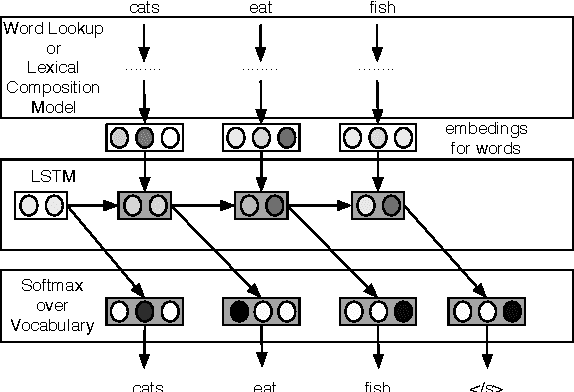

We introduce a model for constructing vector representations of words by composing characters using bidirectional LSTMs. Relative to traditional word representation models that have independent vectors for each word type, our model requires only a single vector per character type and a fixed set of parameters for the compositional model. Despite the compactness of this model and, more importantly, the arbitrary nature of the form-function relationship in language, our "composed" word representations yield state-of-the-art results in language modeling and part-of-speech tagging. Benefits over traditional baselines are particularly pronounced in morphologically rich languages (e.g., Turkish).