 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Quantum Classifier Based on Hamiltonian Representations
Apr 13, 2025



Quantum machine learning (QML) is a discipline that seeks to transfer the advantages of quantum computing to data-driven tasks. However, many studies rely on toy datasets or heavy feature reduction, raising concerns about their scalability. Progress is further hindered by hardware limitations and the significant costs of encoding dense vector representations on quantum devices. To address these challenges, we propose an efficient approach called Hamiltonian classifier that circumvents the costs associated with data encoding by mapping inputs to a finite set of Pauli strings and computing predictions as their expectation values. In addition, we introduce two classifier variants with different scaling in terms of parameters and sample complexity. We evaluate our approach on text and image classification tasks, against well-established classical and quantum models. The Hamiltonian classifier delivers performance comparable to or better than these methods. Notably, our method achieves logarithmic complexity in both qubits and quantum gates, making it well-suited for large-scale, real-world applications. We make our implementation available on GitHub.
Identifying Aspects in Peer Reviews
Apr 09, 2025



Peer review is central to academic publishing, but the growing volume of submissions is straining the process. This motivates the development of computational approaches to support peer review. While each review is tailored to a specific paper, reviewers often make assessments according to certain aspects such as Novelty, which reflect the values of the research community. This alignment creates opportunities for standardizing the reviewing process, improving quality control, and enabling computational support. While prior work has demonstrated the potential of aspect analysis for peer review assistance, the notion of aspect remains poorly formalized. Existing approaches often derive aspect sets from review forms and guidelines of major NLP venues, yet data-driven methods for aspect identification are largely underexplored. To address this gap, our work takes a bottom-up approach: we propose an operational definition of aspect and develop a data-driven schema for deriving fine-grained aspects from a corpus of peer reviews. We introduce a dataset of peer reviews augmented with aspects and show how it can be used for community-level review analysis. We further show how the choice of aspects can impact downstream applications, such as LLM-generated review detection. Our results lay a foundation for a principled and data-driven investigation of review aspects, and pave the path for new applications of NLP to support peer review.
Enhancing Depression Detection via Question-wise Modality Fusion
Mar 26, 2025



Depression is a highly prevalent and disabling condition that incurs substantial personal and societal costs. Current depression diagnosis involves determining the depression severity of a person through self-reported questionnaires or interviews conducted by clinicians. This often leads to delayed treatment and involves substantial human resources. Thus, several works try to automate the process using multimodal data. However, they usually overlook the following: i) The variable contribution of each modality for each question in the questionnaire and ii) Using ordinal classification for the task. This results in sub-optimal fusion and training methods. In this work, we propose a novel Question-wise Modality Fusion (QuestMF) framework trained with a novel Imbalanced Ordinal Log-Loss (ImbOLL) function to tackle these issues. The performance of our framework is comparable to the current state-of-the-art models on the E-DAIC dataset and enhances interpretability by predicting scores for each question. This will help clinicians identify an individual's symptoms, allowing them to customise their interventions accordingly. We also make the code for the QuestMF framework publicly available.
Aligned Probing: Relating Toxic Behavior and Model Internals
Mar 17, 2025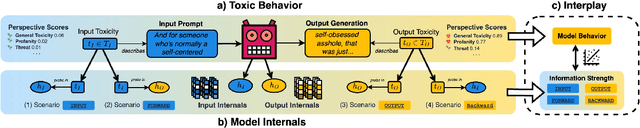

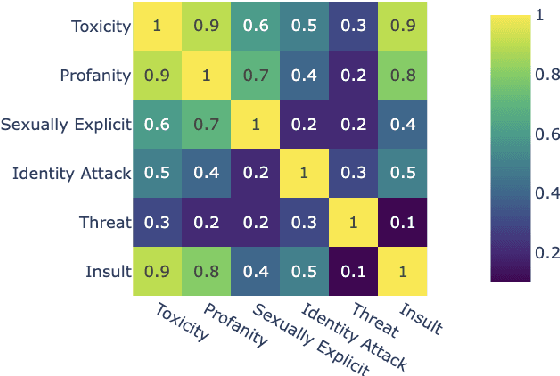
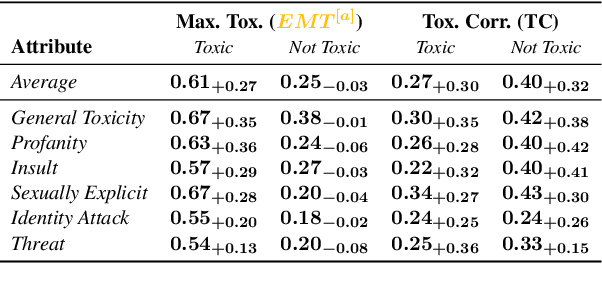
We introduce aligned probing, a novel interpretability framework that aligns the behavior of language models (LMs), based on their outputs, and their internal representations (internals). Using this framework, we examine over 20 OLMo, Llama, and Mistral models, bridging behavioral and internal perspectives for toxicity for the first time. Our results show that LMs strongly encode information about the toxicity level of inputs and subsequent outputs, particularly in lower layers. Focusing on how unique LMs differ offers both correlative and causal evidence that they generate less toxic output when strongly encoding information about the input toxicity. We also highlight the heterogeneity of toxicity, as model behavior and internals vary across unique attributes such as Threat. Finally, four case studies analyzing detoxification, multi-prompt evaluations, model quantization, and pre-training dynamics underline the practical impact of aligned probing with further concrete insights. Our findings contribute to a more holistic understanding of LMs, both within and beyond the context of toxicity.
Token Weighting for Long-Range Language Modeling
Mar 12, 2025



Many applications of large language models (LLMs) require long-context understanding, but models continue to struggle with such tasks. We hypothesize that conventional next-token prediction training could contribute to this, because each token is assigned equal weight. Yet, intuitively, the amount of context needed to predict the next token accurately varies greatly across different data. To reflect this, we propose various novel token-weighting schemes that assign different weights to each training token in the loss, thereby generalizing existing works. For this, we categorize token-weighting methods using a two-step framework which compares the confidences of a long-context and short-context model to score tokens. We evaluate all methods on multiple long-context understanding tasks and show that non-uniform loss weights are helpful to improve the long-context abilities of LLMs. Different short-context models can be used effectively for token scoring, including models that are much smaller than the long-context model that is trained. All in all, this work contributes to a better understanding of the trade-offs long-context language modeling faces and provides guidelines for model steering via loss-weighting based on empirical evidence. The code can be found on Github.
GRITHopper: Decomposition-Free Multi-Hop Dense Retrieval
Mar 10, 2025



Decomposition-based multi-hop retrieval methods rely on many autoregressive steps to break down complex queries, which breaks end-to-end differentiability and is computationally expensive. Decomposition-free methods tackle this, but current decomposition-free approaches struggle with longer multi-hop problems and generalization to out-of-distribution data. To address these challenges, we introduce GRITHopper-7B, a novel multi-hop dense retrieval model that achieves state-of-the-art performance on both in-distribution and out-of-distribution benchmarks. GRITHopper combines generative and representational instruction tuning by integrating causal language modeling with dense retrieval training. Through controlled studies, we find that incorporating additional context after the retrieval process, referred to as post-retrieval language modeling, enhances dense retrieval performance. By including elements such as final answers during training, the model learns to better contextualize and retrieve relevant information. GRITHopper-7B offers a robust, scalable, and generalizable solution for multi-hop dense retrieval, and we release it to the community for future research and applications requiring multi-hop reasoning and retrieval capabilities.
Uncertainty-Aware Decoding with Minimum Bayes Risk
Mar 07, 2025Despite their outstanding performance in the majority of scenarios, contemporary language models still occasionally generate undesirable outputs, for example, hallucinated text. While such behaviors have previously been linked to uncertainty, there is a notable lack of methods that actively consider uncertainty during text generation. In this work, we show how Minimum Bayes Risk (MBR) decoding, which selects model generations according to an expected risk, can be generalized into a principled uncertainty-aware decoding method. In short, we account for model uncertainty during decoding by incorporating a posterior over model parameters into MBR's computation of expected risk. We show that this modified expected risk is useful for both choosing outputs and deciding when to abstain from generation and can provide improvements without incurring overhead. We benchmark different methods for learning posteriors and show that performance improves with prediction diversity. We release our code publicly.
Protecting multimodal large language models against misleading visualizations
Feb 27, 2025



We assess the vulnerability of multimodal large language models to misleading visualizations - charts that distort the underlying data using techniques such as truncated or inverted axes, leading readers to draw inaccurate conclusions that may support misinformation or conspiracy theories. Our analysis shows that these distortions severely harm multimodal large language models, reducing their question-answering accuracy to the level of the random baseline. To mitigate this vulnerability, we introduce six inference-time methods to improve performance of MLLMs on misleading visualizations while preserving their accuracy on non-misleading ones. The most effective approach involves (1) extracting the underlying data table and (2) using a text-only large language model to answer questions based on the table. This method improves performance on misleading visualizations by 15.4 to 19.6 percentage points.
MathTutorBench: A Benchmark for Measuring Open-ended Pedagogical Capabilities of LLM Tutors
Feb 26, 2025Evaluating the pedagogical capabilities of AI-based tutoring models is critical for making guided progress in the field. Yet, we lack a reliable, easy-to-use, and simple-to-run evaluation that reflects the pedagogical abilities of models. To fill this gap, we present MathTutorBench, an open-source benchmark for holistic tutoring model evaluation. MathTutorBench contains a collection of datasets and metrics that broadly cover tutor abilities as defined by learning sciences research in dialog-based teaching. To score the pedagogical quality of open-ended teacher responses, we train a reward model and show it can discriminate expert from novice teacher responses with high accuracy. We evaluate a wide set of closed- and open-weight models on MathTutorBench and find that subject expertise, indicated by solving ability, does not immediately translate to good teaching. Rather, pedagogy and subject expertise appear to form a trade-off that is navigated by the degree of tutoring specialization of the model. Furthermore, tutoring appears to become more challenging in longer dialogs, where simpler questioning strategies begin to fail. We release the benchmark, code, and leaderboard openly to enable rapid benchmarking of future models.
PeerQA: A Scientific Question Answering Dataset from Peer Reviews
Feb 19, 2025We present PeerQA, a real-world, scientific, document-level Question Answering (QA) dataset. PeerQA questions have been sourced from peer reviews, which contain questions that reviewers raised while thoroughly examining the scientific article. Answers have been annotated by the original authors of each paper. The dataset contains 579 QA pairs from 208 academic articles, with a majority from ML and NLP, as well as a subset of other scientific communities like Geoscience and Public Health. PeerQA supports three critical tasks for developing practical QA systems: Evidence retrieval, unanswerable question classification, and answer generation. We provide a detailed analysis of the collected dataset and conduct experiments establishing baseline systems for all three tasks. Our experiments and analyses reveal the need for decontextualization in document-level retrieval, where we find that even simple decontextualization approaches consistently improve retrieval performance across architectures. On answer generation, PeerQA serves as a challenging benchmark for long-context modeling, as the papers have an average size of 12k tokens. Our code and data is available at https://github.com/UKPLab/peerqa.