 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Search with MCTSnets
Jul 17, 2018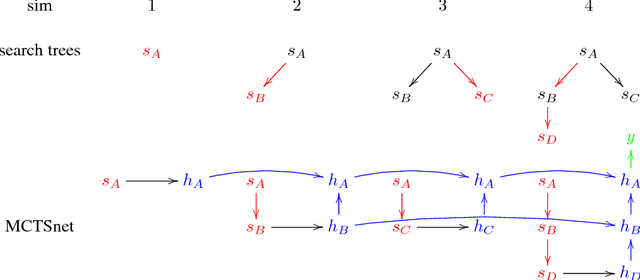
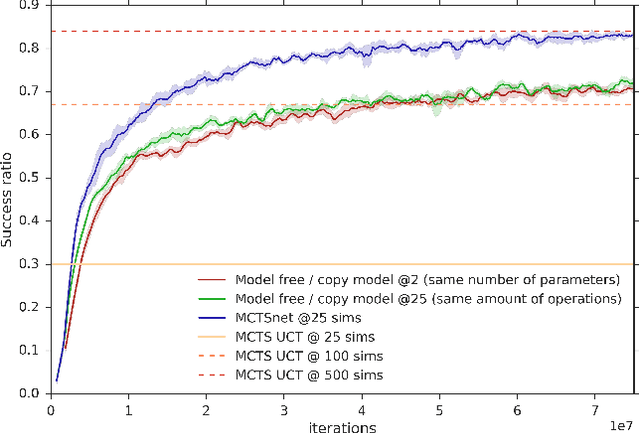
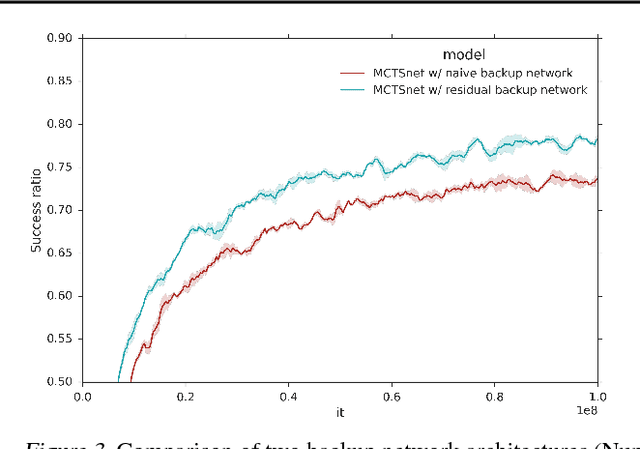
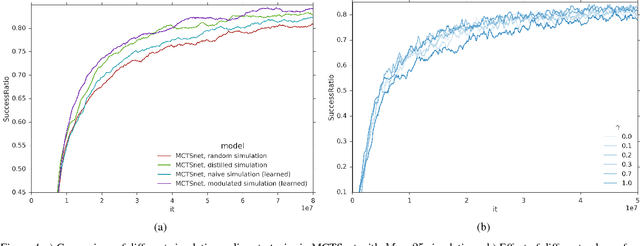
Planning problems are among the most important and well-studied problems in artificial intelligence. They are most typically solved by tree search algorithms that simulate ahead into the future, evaluate future states, and back-up those evaluations to the root of a search tree. Among these algorithms, Monte-Carlo tree search (MCTS) is one of the most general, powerful and widely used. A typical implementation of MCTS uses cleverly designed rules, optimized to the particular characteristics of the domain. These rules control where the simulation traverses, what to evaluate in the states that are reached, and how to back-up those evaluations. In this paper we instead learn where, what and how to search. Our architecture, which we call an MCTSnet, incorporates simulation-based search inside a neural network, by expanding, evaluating and backing-up a vector embedding. The parameters of the network are trained end-to-end using gradient-based optimisation. When applied to small searches in the well known planning problem Sokoban, the learned search algorithm significantly outperformed MCTS baselines.
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
Dec 05, 2017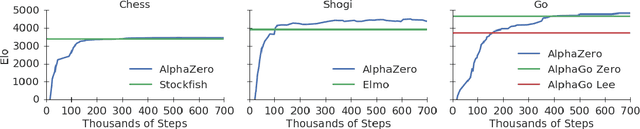
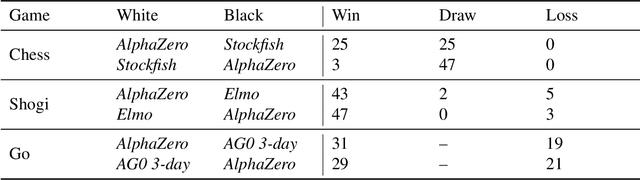
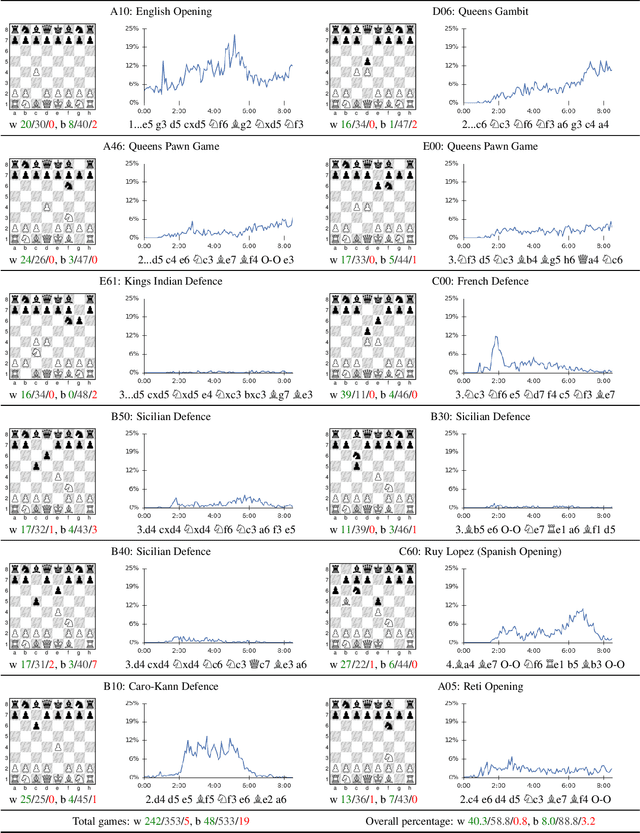
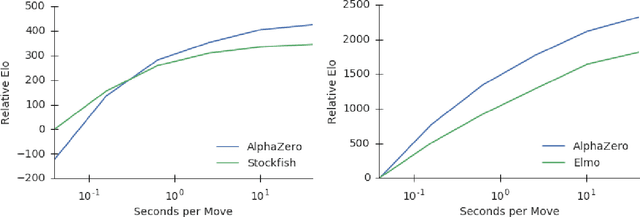
The game of chess is the most widely-studied domain in the history of artificial intelligence. The strongest programs are based on a combination of sophisticated search techniques, domain-specific adaptations, and handcrafted evaluation functions that have been refined by human experts over several decades. In contrast, the AlphaGo Zero program recently achieved superhuman performance in the game of Go, by tabula rasa reinforcement learning from games of self-play. In this paper, we generalise this approach into a single AlphaZero algorithm that can achieve, tabula rasa, superhuman performance in many challenging domains. Starting from random play, and given no domain knowledge except the game rules, AlphaZero achieved within 24 hours a superhuman level of play in the games of chess and shogi (Japanese chess) as well as Go, and convincingly defeated a world-champion program in each case.
Fast Non-Parametric Tests of Relative Dependency and Similarity
Nov 17, 2016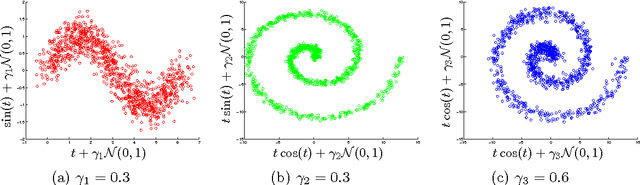
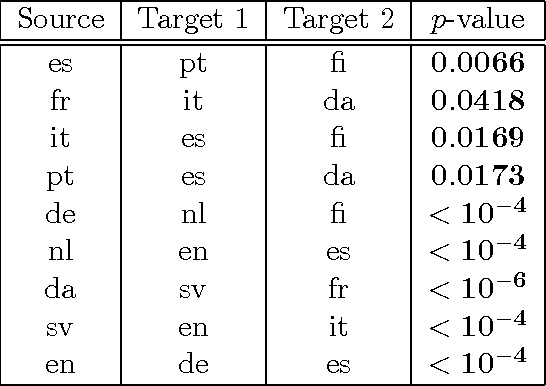
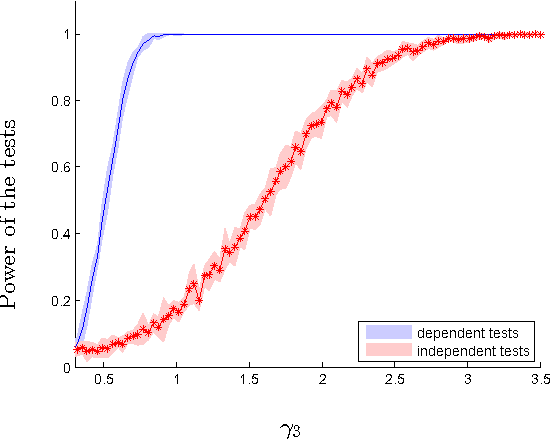
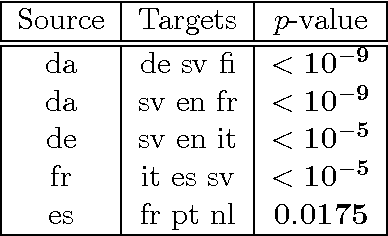
We introduce two novel non-parametric statistical hypothesis tests. The first test, called the relative test of dependency, enables us to determine whether one source variable is significantly more dependent on a first target variable or a second. Dependence is measured via the Hilbert-Schmidt Independence Criterion (HSIC). The second test, called the relative test of similarity, is use to determine which of the two samples from arbitrary distributions is significantly closer to a reference sample of interest and the relative measure of similarity is based on the Maximum Mean Discrepancy (MMD). To construct these tests, we have used as our test statistics the difference of HSIC statistics and of MMD statistics, respectively. The resulting tests are consistent and unbiased, and have favorable convergence properties. The effectiveness of the relative dependency test is demonstrated on several real-world problems: we identify languages groups from a multilingual parallel corpus, and we show that tumor location is more dependent on gene expression than chromosome imbalance. We also demonstrate the performance of the relative test of similarity over a broad selection of model comparisons problems in deep generative models.
Prioritized Experience Replay
Feb 25, 2016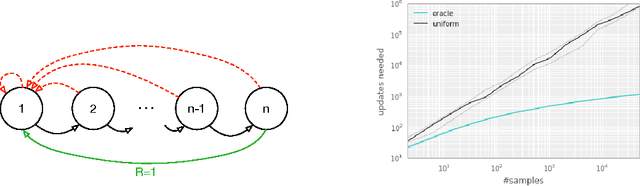
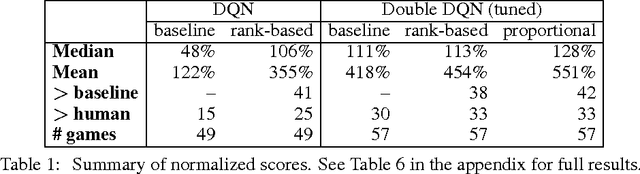
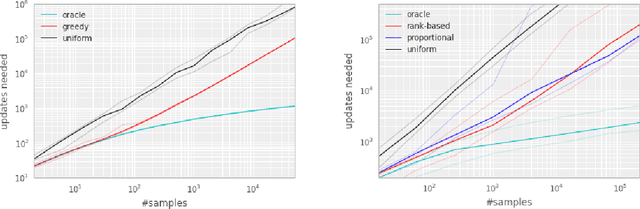

Experience replay lets online reinforcement learning agents remember and reuse experiences from the past. In prior work, experience transitions were uniformly sampled from a replay memory. However, this approach simply replays transitions at the same frequency that they were originally experienced, regardless of their significance. In this paper we develop a framework for prioritizing experience, so as to replay important transitions more frequently, and therefore learn more efficiently. We use prioritized experience replay in Deep Q-Networks (DQN), a reinforcement learning algorithm that achieved human-level performance across many Atari games. DQN with prioritized experience replay achieves a new state-of-the-art, outperforming DQN with uniform replay on 41 out of 49 games.
A Test of Relative Similarity For Model Selection in Generative Models
Feb 15, 2016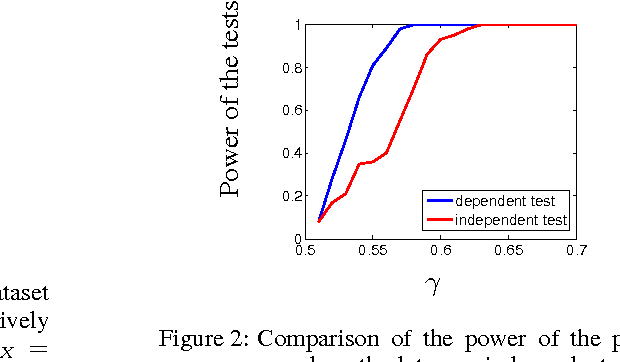


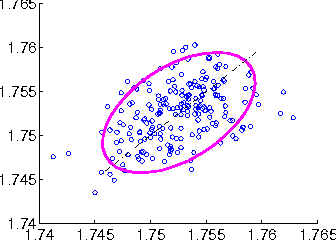
Probabilistic generative models provide a powerful framework for representing data that avoids the expense of manual annotation typically needed by discriminative approaches. Model selection in this generative setting can be challenging, however, particularly when likelihoods are not easily accessible. To address this issue, we introduce a statistical test of relative similarity, which is used to determine which of two models generates samples that are significantly closer to a real-world reference dataset of interest. We use as our test statistic the difference in maximum mean discrepancies (MMDs) between the reference dataset and each model dataset, and derive a powerful, low-variance test based on the joint asymptotic distribution of the MMDs between each reference-model pair. In experiments on deep generative models, including the variational auto-encoder and generative moment matching network, the tests provide a meaningful ranking of model performance as a function of parameter and training settings.
Unit Tests for Stochastic Optimization
Feb 25, 2014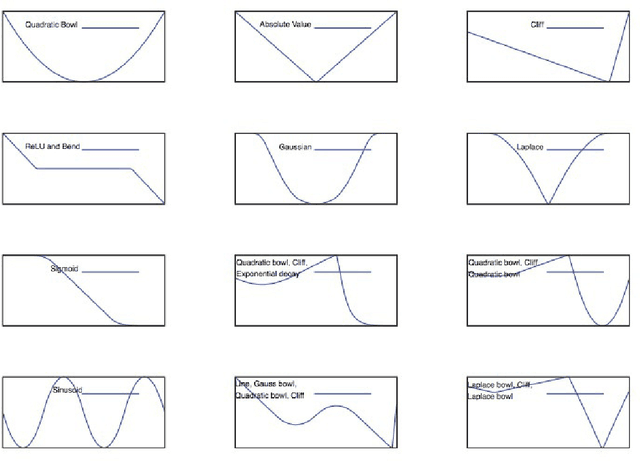
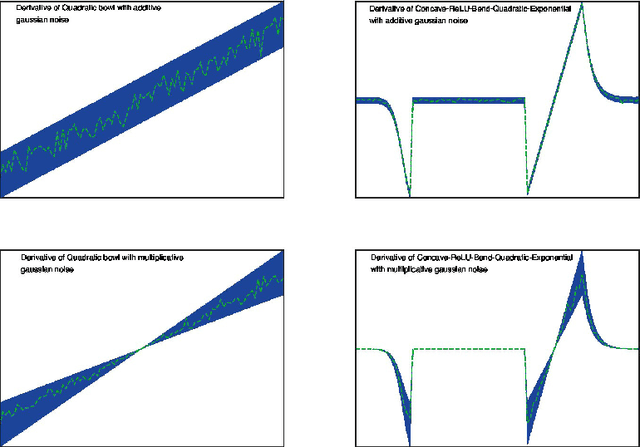
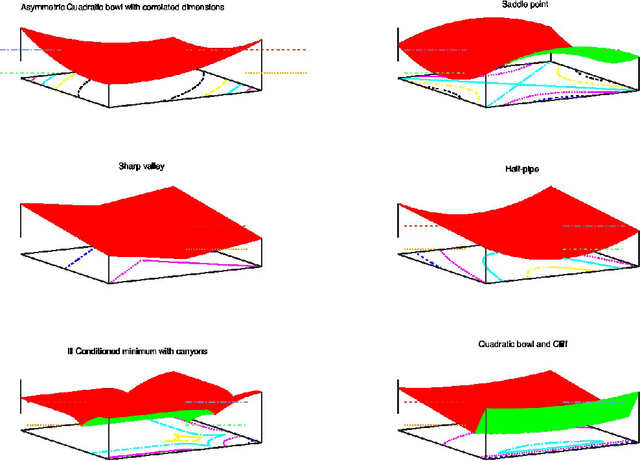

Optimization by stochastic gradient descent is an important component of many large-scale machine learning algorithms. A wide variety of such optimization algorithms have been devised; however, it is unclear whether these algorithms are robust and widely applicable across many different optimization landscapes. In this paper we develop a collection of unit tests for stochastic optimization. Each unit test rapidly evaluates an optimization algorithm on a small-scale, isolated, and well-understood difficulty, rather than in real-world scenarios where many such issues are entangled. Passing these unit tests is not sufficient, but absolutely necessary for any algorithms with claims to generality or robustness. We give initial quantitative and qualitative results on numerous established algorithms. The testing framework is open-source, extensible, and easy to apply to new algorithms.
Playing Atari with Deep Reinforcement Learning
Dec 19, 2013



We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw pixels and whose output is a value function estimating future rewards. We apply our method to seven Atari 2600 games from the Arcade Learning Environment, with no adjustment of the architecture or learning algorithm. We find that it outperforms all previous approaches on six of the games and surpasses a human expert on three of them.