 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEye2Eye: A Simple Approach for Monocular-to-Stereo Video Synthesis
Apr 30, 2025The rising popularity of immersive visual experiences has increased interest in stereoscopic 3D video generation. Despite significant advances in video synthesis, creating 3D videos remains challenging due to the relative scarcity of 3D video data. We propose a simple approach for transforming a text-to-video generator into a video-to-stereo generator. Given an input video, our framework automatically produces the video frames from a shifted viewpoint, enabling a compelling 3D effect. Prior and concurrent approaches for this task typically operate in multiple phases, first estimating video disparity or depth, then warping the video accordingly to produce a second view, and finally inpainting the disoccluded regions. This approach inherently fails when the scene involves specular surfaces or transparent objects. In such cases, single-layer disparity estimation is insufficient, resulting in artifacts and incorrect pixel shifts during warping. Our work bypasses these restrictions by directly synthesizing the new viewpoint, avoiding any intermediate steps. This is achieved by leveraging a pre-trained video model's priors on geometry, object materials, optics, and semantics, without relying on external geometry models or manually disentangling geometry from the synthesis process. We demonstrate the advantages of our approach in complex, real-world scenarios featuring diverse object materials and compositions. See videos on https://video-eye2eye.github.io
TokenVerse: Versatile Multi-concept Personalization in Token Modulation Space
Jan 21, 2025



We present TokenVerse -- a method for multi-concept personalization, leveraging a pre-trained text-to-image diffusion model. Our framework can disentangle complex visual elements and attributes from as little as a single image, while enabling seamless plug-and-play generation of combinations of concepts extracted from multiple images. As opposed to existing works, TokenVerse can handle multiple images with multiple concepts each, and supports a wide-range of concepts, including objects, accessories, materials, pose, and lighting. Our work exploits a DiT-based text-to-image model, in which the input text affects the generation through both attention and modulation (shift and scale). We observe that the modulation space is semantic and enables localized control over complex concepts. Building on this insight, we devise an optimization-based framework that takes as input an image and a text description, and finds for each word a distinct direction in the modulation space. These directions can then be used to generate new images that combine the learned concepts in a desired configuration. We demonstrate the effectiveness of TokenVerse in challenging personalization settings, and showcase its advantages over existing methods. project's webpage in https://token-verse.github.io/
ReCapture: Generative Video Camera Controls for User-Provided Videos using Masked Video Fine-Tuning
Nov 07, 2024



Recently, breakthroughs in video modeling have allowed for controllable camera trajectories in generated videos. However, these methods cannot be directly applied to user-provided videos that are not generated by a video model. In this paper, we present ReCapture, a method for generating new videos with novel camera trajectories from a single user-provided video. Our method allows us to re-generate the reference video, with all its existing scene motion, from vastly different angles and with cinematic camera motion. Notably, using our method we can also plausibly hallucinate parts of the scene that were not observable in the reference video. Our method works by (1) generating a noisy anchor video with a new camera trajectory using multiview diffusion models or depth-based point cloud rendering and then (2) regenerating the anchor video into a clean and temporally consistent reangled video using our proposed masked video fine-tuning technique.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Still-Moving: Customized Video Generation without Customized Video Data
Jul 11, 2024



Customizing text-to-image (T2I) models has seen tremendous progress recently, particularly in areas such as personalization, stylization, and conditional generation. However, expanding this progress to video generation is still in its infancy, primarily due to the lack of customized video data. In this work, we introduce Still-Moving, a novel generic framework for customizing a text-to-video (T2V) model, without requiring any customized video data. The framework applies to the prominent T2V design where the video model is built over a text-to-image (T2I) model (e.g., via inflation). We assume access to a customized version of the T2I model, trained only on still image data (e.g., using DreamBooth or StyleDrop). Naively plugging in the weights of the customized T2I model into the T2V model often leads to significant artifacts or insufficient adherence to the customization data. To overcome this issue, we train lightweight $\textit{Spatial Adapters}$ that adjust the features produced by the injected T2I layers. Importantly, our adapters are trained on $\textit{"frozen videos"}$ (i.e., repeated images), constructed from image samples generated by the customized T2I model. This training is facilitated by a novel $\textit{Motion Adapter}$ module, which allows us to train on such static videos while preserving the motion prior of the video model. At test time, we remove the Motion Adapter modules and leave in only the trained Spatial Adapters. This restores the motion prior of the T2V model while adhering to the spatial prior of the customized T2I model. We demonstrate the effectiveness of our approach on diverse tasks including personalized, stylized, and conditional generation. In all evaluated scenarios, our method seamlessly integrates the spatial prior of the customized T2I model with a motion prior supplied by the T2V model.
Lumiere: A Space-Time Diffusion Model for Video Generation
Feb 05, 2024



We introduce Lumiere -- a text-to-video diffusion model designed for synthesizing videos that portray realistic, diverse and coherent motion -- a pivotal challenge in video synthesis. To this end, we introduce a Space-Time U-Net architecture that generates the entire temporal duration of the video at once, through a single pass in the model. This is in contrast to existing video models which synthesize distant keyframes followed by temporal super-resolution -- an approach that inherently makes global temporal consistency difficult to achieve. By deploying both spatial and (importantly) temporal down- and up-sampling and leveraging a pre-trained text-to-image diffusion model, our model learns to directly generate a full-frame-rate, low-resolution video by processing it in multiple space-time scales. We demonstrate state-of-the-art text-to-video generation results, and show that our design easily facilitates a wide range of content creation tasks and video editing applications, including image-to-video, video inpainting, and stylized generation.
Idempotent Generative Network
Nov 02, 2023



We propose a new approach for generative modeling based on training a neural network to be idempotent. An idempotent operator is one that can be applied sequentially without changing the result beyond the initial application, namely $f(f(z))=f(z)$. The proposed model $f$ is trained to map a source distribution (e.g, Gaussian noise) to a target distribution (e.g. realistic images) using the following objectives: (1) Instances from the target distribution should map to themselves, namely $f(x)=x$. We define the target manifold as the set of all instances that $f$ maps to themselves. (2) Instances that form the source distribution should map onto the defined target manifold. This is achieved by optimizing the idempotence term, $f(f(z))=f(z)$ which encourages the range of $f(z)$ to be on the target manifold. Under ideal assumptions such a process provably converges to the target distribution. This strategy results in a model capable of generating an output in one step, maintaining a consistent latent space, while also allowing sequential applications for refinement. Additionally, we find that by processing inputs from both target and source distributions, the model adeptly projects corrupted or modified data back to the target manifold. This work is a first step towards a ``global projector'' that enables projecting any input into a target data distribution.
The Hidden Language of Diffusion Models
Jun 06, 2023



Text-to-image diffusion models have demonstrated an unparalleled ability to generate high-quality, diverse images from a textual concept (e.g., "a doctor", "love"). However, the internal process of mapping text to a rich visual representation remains an enigma. In this work, we tackle the challenge of understanding concept representations in text-to-image models by decomposing an input text prompt into a small set of interpretable elements. This is achieved by learning a pseudo-token that is a sparse weighted combination of tokens from the model's vocabulary, with the objective of reconstructing the images generated for the given concept. Applied over the state-of-the-art Stable Diffusion model, this decomposition reveals non-trivial and surprising structures in the representations of concepts. For example, we find that some concepts such as "a president" or "a composer" are dominated by specific instances (e.g., "Obama", "Biden") and their interpolations. Other concepts, such as "happiness" combine associated terms that can be concrete ("family", "laughter") or abstract ("friendship", "emotion"). In addition to peering into the inner workings of Stable Diffusion, our method also enables applications such as single-image decomposition to tokens, bias detection and mitigation, and semantic image manipulation. Our code will be available at: https://hila-chefer.github.io/Conceptor/
Teaching CLIP to Count to Ten
Feb 23, 2023



Large vision-language models (VLMs), such as CLIP, learn rich joint image-text representations, facilitating advances in numerous downstream tasks, including zero-shot classification and text-to-image generation. Nevertheless, existing VLMs exhibit a prominent well-documented limitation - they fail to encapsulate compositional concepts such as counting. We introduce a simple yet effective method to improve the quantitative understanding of VLMs, while maintaining their overall performance on common benchmarks. Specifically, we propose a new counting-contrastive loss used to finetune a pre-trained VLM in tandem with its original objective. Our counting loss is deployed over automatically-created counterfactual examples, each consisting of an image and a caption containing an incorrect object count. For example, an image depicting three dogs is paired with the caption "Six dogs playing in the yard". Our loss encourages discrimination between the correct caption and its counterfactual variant which serves as a hard negative example. To the best of our knowledge, this work is the first to extend CLIP's capabilities to object counting. Furthermore, we introduce "CountBench" - a new image-text counting benchmark for evaluating a model's understanding of object counting. We demonstrate a significant improvement over state-of-the-art baseline models on this task. Finally, we leverage our count-aware CLIP model for image retrieval and text-conditioned image generation, demonstrating that our model can produce specific counts of objects more reliably than existing ones.
Imagic: Text-Based Real Image Editing with Diffusion Models
Oct 17, 2022
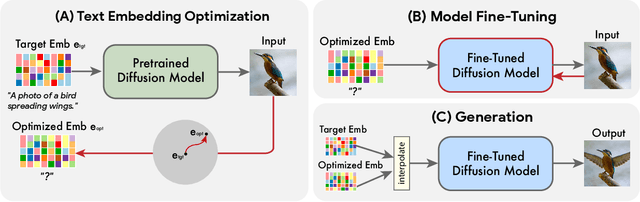


Text-conditioned image editing has recently attracted considerable interest. However, most methods are currently either limited to specific editing types (e.g., object overlay, style transfer), or apply to synthetically generated images, or require multiple input images of a common object. In this paper we demonstrate, for the very first time, the ability to apply complex (e.g., non-rigid) text-guided semantic edits to a single real image. For example, we can change the posture and composition of one or multiple objects inside an image, while preserving its original characteristics. Our method can make a standing dog sit down or jump, cause a bird to spread its wings, etc. -- each within its single high-resolution natural image provided by the user. Contrary to previous work, our proposed method requires only a single input image and a target text (the desired edit). It operates on real images, and does not require any additional inputs (such as image masks or additional views of the object). Our method, which we call "Imagic", leverages a pre-trained text-to-image diffusion model for this task. It produces a text embedding that aligns with both the input image and the target text, while fine-tuning the diffusion model to capture the image-specific appearance. We demonstrate the quality and versatility of our method on numerous inputs from various domains, showcasing a plethora of high quality complex semantic image edits, all within a single unified framework.