 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of Johnson-Lindenstrauss Transform for k-Means and k-Medians Clustering
Nov 08, 2018
Consider an instance of Euclidean $k$-means or $k$-medians clustering. We show that the cost of the optimal solution is preserved up to a factor of $(1+\varepsilon)$ under a projection onto a random $O(\log(k / \varepsilon) / \varepsilon^2)$-dimensional subspace. Further, the cost of every clustering is preserved within $(1+\varepsilon)$. More generally, our result applies to any dimension reduction map satisfying a mild sub-Gaussian-tail condition. Our bound on the dimension is nearly optimal. Additionally, our result applies to Euclidean $k$-clustering with the distances raised to the $p$-th power for any constant $p$. For $k$-means, our result resolves an open problem posed by Cohen, Elder, Musco, Musco, and Persu (STOC 2015); for $k$-medians, it answers a question raised by Kannan.
Approximate Nearest Neighbor Search in High Dimensions
Jun 26, 2018The nearest neighbor problem is defined as follows: Given a set $P$ of $n$ points in some metric space $(X,D)$, build a data structure that, given any point $q$, returns a point in $P$ that is closest to $q$ (its "nearest neighbor" in $P$). The data structure stores additional information about the set $P$, which is then used to find the nearest neighbor without computing all distances between $q$ and $P$. The problem has a wide range of applications in machine learning, computer vision, databases and other fields. To reduce the time needed to find nearest neighbors and the amount of memory used by the data structure, one can formulate the {\em approximate} nearest neighbor problem, where the the goal is to return any point $p' \in P$ such that the distance from $q$ to $p'$ is at most $c \cdot \min_{p \in P} D(q,p)$, for some $c \geq 1$. Over the last two decades, many efficient solutions to this problem were developed. In this article we survey these developments, as well as their connections to questions in geometric functional analysis and combinatorial geometry.
Adversarial examples from computational constraints
May 25, 2018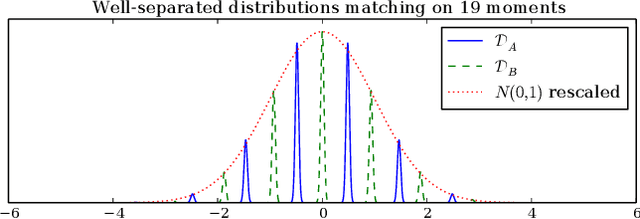
Why are classifiers in high dimension vulnerable to "adversarial" perturbations? We show that it is likely not due to information theoretic limitations, but rather it could be due to computational constraints. First we prove that, for a broad set of classification tasks, the mere existence of a robust classifier implies that it can be found by a possibly exponential-time algorithm with relatively few training examples. Then we give a particular classification task where learning a robust classifier is computationally intractable. More precisely we construct a binary classification task in high dimensional space which is (i) information theoretically easy to learn robustly for large perturbations, (ii) efficiently learnable (non-robustly) by a simple linear separator, (iii) yet is not efficiently robustly learnable, even for small perturbations, by any algorithm in the statistical query (SQ) model. This example gives an exponential separation between classical learning and robust learning in the statistical query model. It suggests that adversarial examples may be an unavoidable byproduct of computational limitations of learning algorithms.
Approximate Near Neighbors for General Symmetric Norms
Jul 24, 2017We show that every symmetric normed space admits an efficient nearest neighbor search data structure with doubly-logarithmic approximation. Specifically, for every $n$, $d = n^{o(1)}$, and every $d$-dimensional symmetric norm $\|\cdot\|$, there exists a data structure for $\mathrm{poly}(\log \log n)$-approximate nearest neighbor search over $\|\cdot\|$ for $n$-point datasets achieving $n^{o(1)}$ query time and $n^{1+o(1)}$ space. The main technical ingredient of the algorithm is a low-distortion embedding of a symmetric norm into a low-dimensional iterated product of top-$k$ norms. We also show that our techniques cannot be extended to general norms.
On the Complexity of Inner Product Similarity Join
Apr 07, 2016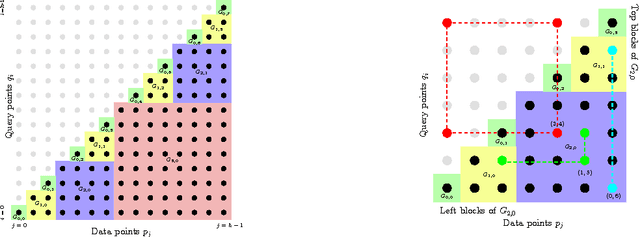
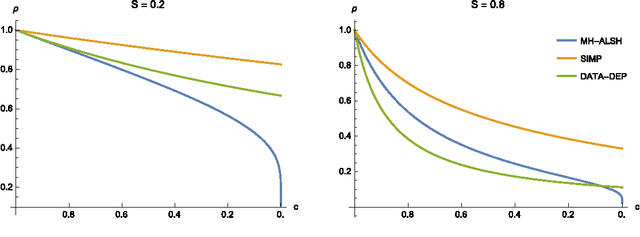
A number of tasks in classification, information retrieval, recommendation systems, and record linkage reduce to the core problem of inner product similarity join (IPS join): identifying pairs of vectors in a collection that have a sufficiently large inner product. IPS join is well understood when vectors are normalized and some approximation of inner products is allowed. However, the general case where vectors may have any length appears much more challenging. Recently, new upper bounds based on asymmetric locality-sensitive hashing (ALSH) and asymmetric embeddings have emerged, but little has been known on the lower bound side. In this paper we initiate a systematic study of inner product similarity join, showing new lower and upper bounds. Our main results are: * Approximation hardness of IPS join in subquadratic time, assuming the strong exponential time hypothesis. * New upper and lower bounds for (A)LSH-based algorithms. In particular, we show that asymmetry can be avoided by relaxing the LSH definition to only consider the collision probability of distinct elements. * A new indexing method for IPS based on linear sketches, implying that our hardness results are not far from being tight. Our technical contributions include new asymmetric embeddings that may be of independent interest. At the conceptual level we strive to provide greater clarity, for example by distinguishing among signed and unsigned variants of IPS join and shedding new light on the effect of asymmetry.