 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoS Certificates for Sparse Singular Values and Their Applications: Robust Statistics, Subspace Distortion, and More
Dec 30, 2024



We study $\textit{sparse singular value certificates}$ for random rectangular matrices. If $M$ is an $n \times d$ matrix with independent Gaussian entries, we give a new family of polynomial-time algorithms which can certify upper bounds on the maximum of $\|M u\|$, where $u$ is a unit vector with at most $\eta n$ nonzero entries for a given $\eta \in (0,1)$. This basic algorithmic primitive lies at the heart of a wide range of problems across algorithmic statistics and theoretical computer science. Our algorithms certify a bound which is asymptotically smaller than the naive one, given by the maximum singular value of $M$, for nearly the widest-possible range of $n,d,$ and $\eta$. Efficiently certifying such a bound for a range of $n,d$ and $\eta$ which is larger by any polynomial factor than what is achieved by our algorithm would violate lower bounds in the SQ and low-degree polynomials models. Our certification algorithm makes essential use of the Sum-of-Squares hierarchy. To prove the correctness of our algorithm, we develop a new combinatorial connection between the graph matrix approach to analyze random matrices with dependent entries, and the Efron-Stein decomposition of functions of independent random variables. As applications of our certification algorithm, we obtain new efficient algorithms for a wide range of well-studied algorithmic tasks. In algorithmic robust statistics, we obtain new algorithms for robust mean and covariance estimation with tradeoffs between breakdown point and sample complexity, which are nearly matched by SQ and low-degree polynomial lower bounds (that we establish). We also obtain new polynomial-time guarantees for certification of $\ell_1/\ell_2$ distortion of random subspaces of $\mathbb{R}^n$ (also with nearly matching lower bounds), sparse principal component analysis, and certification of the $2\rightarrow p$ norm of a random matrix.
Implicit High-Order Moment Tensor Estimation and Learning Latent Variable Models
Nov 23, 2024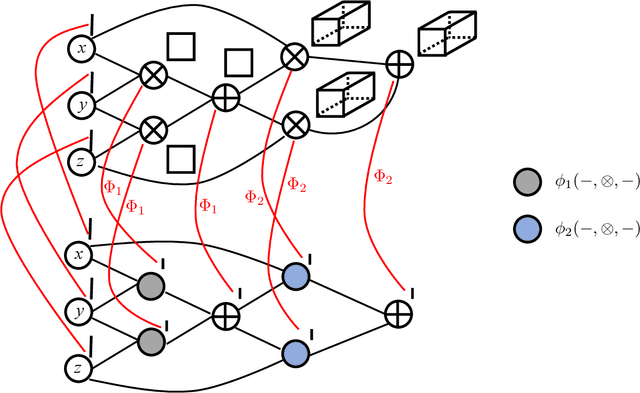
We study the task of learning latent-variable models. An obstacle towards designing efficient algorithms for such models is the necessity of approximating moment tensors of super-constant degree. Motivated by such applications, we develop a general efficient algorithm for implicit moment tensor computation. Our algorithm computes in $\mathrm{poly}(d, k)$ time a succinct approximate description of tensors of the form $M_m=\sum_{i=1}^{k}w_iv_i^{\otimes m}$, for $w_i\in\mathbb{R}_+$--even for $m=\omega(1)$--assuming there exists a polynomial-size arithmetic circuit whose expected output on an appropriate samplable distribution is equal to $M_m$, and whose covariance on this input is bounded. Our framework broadly generalizes the work of~\cite{LL21-opt} which developed an efficient algorithm for the specific moment tensors that arise in clustering mixtures of spherical Gaussians. By leveraging our general algorithm, we obtain the first polynomial-time learners for the following models. * Mixtures of Linear Regressions. We give a $\mathrm{poly}(d, k, 1/\epsilon)$-time algorithm for this task. The previously best algorithm has super-polynomial complexity in $k$. * Learning Mixtures of Spherical Gaussians. We give a $\mathrm{poly}(d, k, 1/\epsilon)$-time density estimation algorithm, under the condition that the means lie in a ball of radius $O(\sqrt{\log k})$. Prior algorithms incur super-polynomial complexity in $k$. We also give a $\mathrm{poly}(d, k, 1/\epsilon)$-time parameter estimation algorithm, under the {\em optimal} mean separation of $\Omega(\log^{1/2}(k/\epsilon))$. * PAC Learning Sums of ReLUs. We give a learner with complexity $\mathrm{poly}(d, k) 2^{\mathrm{poly}(1/\epsilon)}$. This is the first algorithm for this task that runs in $\mathrm{poly}(d, k)$ time for subconstant values of $\epsilon = o_{k, d}(1)$.
Reliable Learning of Halfspaces under Gaussian Marginals
Nov 18, 2024We study the problem of PAC learning halfspaces in the reliable agnostic model of Kalai et al. (2012). The reliable PAC model captures learning scenarios where one type of error is costlier than the others. Our main positive result is a new algorithm for reliable learning of Gaussian halfspaces on $\mathbb{R}^d$ with sample and computational complexity $$d^{O(\log (\min\{1/\alpha, 1/\epsilon\}))}\min (2^{\log(1/\epsilon)^{O(\log (1/\alpha))}},2^{\mathrm{poly}(1/\epsilon)})\;,$$ where $\epsilon$ is the excess error and $\alpha$ is the bias of the optimal halfspace. We complement our upper bound with a Statistical Query lower bound suggesting that the $d^{\Omega(\log (1/\alpha))}$ dependence is best possible. Conceptually, our results imply a strong computational separation between reliable agnostic learning and standard agnostic learning of halfspaces in the Gaussian setting.
Learning a Single Neuron Robustly to Distributional Shifts and Adversarial Label Noise
Nov 11, 2024We study the problem of learning a single neuron with respect to the $L_2^2$-loss in the presence of adversarial distribution shifts, where the labels can be arbitrary, and the goal is to find a ``best-fit'' function. More precisely, given training samples from a reference distribution $\mathcal{p}_0$, the goal is to approximate the vector $\mathbf{w}^*$ which minimizes the squared loss with respect to the worst-case distribution that is close in $\chi^2$-divergence to $\mathcal{p}_{0}$. We design a computationally efficient algorithm that recovers a vector $ \hat{\mathbf{w}}$ satisfying $\mathbb{E}_{\mathcal{p}^*} (\sigma(\hat{\mathbf{w}} \cdot \mathbf{x}) - y)^2 \leq C \, \mathbb{E}_{\mathcal{p}^*} (\sigma(\mathbf{w}^* \cdot \mathbf{x}) - y)^2 + \epsilon$, where $C>1$ is a dimension-independent constant and $(\mathbf{w}^*, \mathcal{p}^*)$ is the witness attaining the min-max risk $\min_{\mathbf{w}~:~\|\mathbf{w}\| \leq W} \max_{\mathcal{p}} \mathbb{E}_{(\mathbf{x}, y) \sim \mathcal{p}} (\sigma(\mathbf{w} \cdot \mathbf{x}) - y)^2 - \nu \chi^2(\mathcal{p}, \mathcal{p}_0)$. Our algorithm follows a primal-dual framework and is designed by directly bounding the risk with respect to the original, nonconvex $L_2^2$ loss. From an optimization standpoint, our work opens new avenues for the design of primal-dual algorithms under structured nonconvexity.
Sample and Computationally Efficient Robust Learning of Gaussian Single-Index Models
Nov 08, 2024A single-index model (SIM) is a function of the form $\sigma(\mathbf{w}^{\ast} \cdot \mathbf{x})$, where $\sigma: \mathbb{R} \to \mathbb{R}$ is a known link function and $\mathbf{w}^{\ast}$ is a hidden unit vector. We study the task of learning SIMs in the agnostic (a.k.a. adversarial label noise) model with respect to the $L^2_2$-loss under the Gaussian distribution. Our main result is a sample and computationally efficient agnostic proper learner that attains $L^2_2$-error of $O(\mathrm{OPT})+\epsilon$, where $\mathrm{OPT}$ is the optimal loss. The sample complexity of our algorithm is $\tilde{O}(d^{\lceil k^{\ast}/2\rceil}+d/\epsilon)$, where $k^{\ast}$ is the information-exponent of $\sigma$ corresponding to the degree of its first non-zero Hermite coefficient. This sample bound nearly matches known CSQ lower bounds, even in the realizable setting. Prior algorithmic work in this setting had focused on learning in the realizable case or in the presence of semi-random noise. Prior computationally efficient robust learners required significantly stronger assumptions on the link function.
SoS Certifiability of Subgaussian Distributions and its Algorithmic Applications
Oct 28, 2024
We prove that there is a universal constant $C>0$ so that for every $d \in \mathbb N$, every centered subgaussian distribution $\mathcal D$ on $\mathbb R^d$, and every even $p \in \mathbb N$, the $d$-variate polynomial $(Cp)^{p/2} \cdot \|v\|_{2}^p - \mathbb E_{X \sim \mathcal D} \langle v,X\rangle^p$ is a sum of square polynomials. This establishes that every subgaussian distribution is \emph{SoS-certifiably subgaussian} -- a condition that yields efficient learning algorithms for a wide variety of high-dimensional statistical tasks. As a direct corollary, we obtain computationally efficient algorithms with near-optimal guarantees for the following tasks, when given samples from an arbitrary subgaussian distribution: robust mean estimation, list-decodable mean estimation, clustering mean-separated mixture models, robust covariance-aware mean estimation, robust covariance estimation, and robust linear regression. Our proof makes essential use of Talagrand's generic chaining/majorizing measures theorem.
Sum-of-squares lower bounds for Non-Gaussian Component Analysis
Oct 28, 2024



Non-Gaussian Component Analysis (NGCA) is the statistical task of finding a non-Gaussian direction in a high-dimensional dataset. Specifically, given i.i.d.\ samples from a distribution $P^A_{v}$ on $\mathbb{R}^n$ that behaves like a known distribution $A$ in a hidden direction $v$ and like a standard Gaussian in the orthogonal complement, the goal is to approximate the hidden direction. The standard formulation posits that the first $k-1$ moments of $A$ match those of the standard Gaussian and the $k$-th moment differs. Under mild assumptions, this problem has sample complexity $O(n)$. On the other hand, all known efficient algorithms require $\Omega(n^{k/2})$ samples. Prior work developed sharp Statistical Query and low-degree testing lower bounds suggesting an information-computation tradeoff for this problem. Here we study the complexity of NGCA in the Sum-of-Squares (SoS) framework. Our main contribution is the first super-constant degree SoS lower bound for NGCA. Specifically, we show that if the non-Gaussian distribution $A$ matches the first $(k-1)$ moments of $\mathcal{N}(0, 1)$ and satisfies other mild conditions, then with fewer than $n^{(1 - \varepsilon)k/2}$ many samples from the normal distribution, with high probability, degree $(\log n)^{{1\over 2}-o_n(1)}$ SoS fails to refute the existence of such a direction $v$. Our result significantly strengthens prior work by establishing a super-polynomial information-computation tradeoff against a broader family of algorithms. As corollaries, we obtain SoS lower bounds for several problems in robust statistics and the learning of mixture models. Our SoS lower bound proof introduces a novel technique, that we believe may be of broader interest, and a number of refinements over existing methods.
Efficient Testable Learning of General Halfspaces with Adversarial Label Noise
Aug 30, 2024


We study the task of testable learning of general -- not necessarily homogeneous -- halfspaces with adversarial label noise with respect to the Gaussian distribution. In the testable learning framework, the goal is to develop a tester-learner such that if the data passes the tester, then one can trust the output of the robust learner on the data.Our main result is the first polynomial time tester-learner for general halfspaces that achieves dimension-independent misclassification error. At the heart of our approach is a new methodology to reduce testable learning of general halfspaces to testable learning of nearly homogeneous halfspaces that may be of broader interest.
* Presented to COLT'24
Online Learning of Halfspaces with Massart Noise
May 21, 2024We study the task of online learning in the presence of Massart noise. Instead of assuming that the online adversary chooses an arbitrary sequence of labels, we assume that the context $\mathbf{x}$ is selected adversarially but the label $y$ presented to the learner disagrees with the ground-truth label of $\mathbf{x}$ with unknown probability at most $\eta$. We study the fundamental class of $\gamma$-margin linear classifiers and present a computationally efficient algorithm that achieves mistake bound $\eta T + o(T)$. Our mistake bound is qualitatively tight for efficient algorithms: it is known that even in the offline setting achieving classification error better than $\eta$ requires super-polynomial time in the SQ model. We extend our online learning model to a $k$-arm contextual bandit setting where the rewards -- instead of satisfying commonly used realizability assumptions -- are consistent (in expectation) with some linear ranking function with weight vector $\mathbf{w}^\ast$. Given a list of contexts $\mathbf{x}_1,\ldots \mathbf{x}_k$, if $\mathbf{w}^*\cdot \mathbf{x}_i > \mathbf{w}^* \cdot \mathbf{x}_j$, the expected reward of action $i$ must be larger than that of $j$ by at least $\Delta$. We use our Massart online learner to design an efficient bandit algorithm that obtains expected reward at least $(1-1/k)~ \Delta T - o(T)$ bigger than choosing a random action at every round.
Super Non-singular Decompositions of Polynomials and their Application to Robustly Learning Low-degree PTFs
Mar 31, 2024
We study the efficient learnability of low-degree polynomial threshold functions (PTFs) in the presence of a constant fraction of adversarial corruptions. Our main algorithmic result is a polynomial-time PAC learning algorithm for this concept class in the strong contamination model under the Gaussian distribution with error guarantee $O_{d, c}(\text{opt}^{1-c})$, for any desired constant $c>0$, where $\text{opt}$ is the fraction of corruptions. In the strong contamination model, an omniscient adversary can arbitrarily corrupt an $\text{opt}$-fraction of the data points and their labels. This model generalizes the malicious noise model and the adversarial label noise model. Prior to our work, known polynomial-time algorithms in this corruption model (or even in the weaker adversarial label noise model) achieved error $\tilde{O}_d(\text{opt}^{1/(d+1)})$, which deteriorates significantly as a function of the degree $d$. Our algorithm employs an iterative approach inspired by localization techniques previously used in the context of learning linear threshold functions. Specifically, we use a robust perceptron algorithm to compute a good partial classifier and then iterate on the unclassified points. In order to achieve this, we need to take a set defined by a number of polynomial inequalities and partition it into several well-behaved subsets. To this end, we develop new polynomial decomposition techniques that may be of independent interest.