 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePokemonChat: Auditing ChatGPT for Pokémon Universe Knowledge
Jun 05, 2023The recently released ChatGPT model demonstrates unprecedented capabilities in zero-shot question-answering. In this work, we probe ChatGPT for its conversational understanding and introduce a conversational framework (protocol) that can be adopted in future studies. The Pok\'emon universe serves as an ideal testing ground for auditing ChatGPT's reasoning capabilities due to its closed world assumption. After bringing ChatGPT's background knowledge (on the Pok\'emon universe) to light, we test its reasoning process when using these concepts in battle scenarios. We then evaluate its ability to acquire new knowledge and include it in its reasoning process. Our ultimate goal is to assess ChatGPT's ability to generalize, combine features, and to acquire and reason over newly introduced knowledge from human feedback. We find that ChatGPT has prior knowledge of the Pokemon universe, which can reason upon in battle scenarios to a great extent, even when new information is introduced. The model performs better with collaborative feedback and if there is an initial phase of information retrieval, but also hallucinates occasionally and is susceptible to adversarial attacks.
Efficient Document Embeddings via Self-Contrastive Bregman Divergence Learning
May 25, 2023



Learning quality document embeddings is a fundamental problem in natural language processing (NLP), information retrieval (IR), recommendation systems, and search engines. Despite recent advances in the development of transformer-based models that produce sentence embeddings with self-contrastive learning, the encoding of long documents (Ks of words) is still challenging with respect to both efficiency and quality considerations. Therefore, we train Longfomer-based document encoders using a state-of-the-art unsupervised contrastive learning method (SimCSE). Further on, we complement the baseline method -- siamese neural network -- with additional convex neural networks based on functional Bregman divergence aiming to enhance the quality of the output document representations. We show that overall the combination of a self-contrastive siamese network and our proposed neural Bregman network outperforms the baselines in two linear classification settings on three long document topic classification tasks from the legal and biomedical domains.
Retrieval-augmented Multi-label Text Classification
May 22, 2023Multi-label text classification (MLC) is a challenging task in settings of large label sets, where label support follows a Zipfian distribution. In this paper, we address this problem through retrieval augmentation, aiming to improve the sample efficiency of classification models. Our approach closely follows the standard MLC architecture of a Transformer-based encoder paired with a set of classification heads. In our case, however, the input document representation is augmented through cross-attention to similar documents retrieved from the training set and represented in a task-specific manner. We evaluate this approach on four datasets from the legal and biomedical domains, all of which feature highly skewed label distributions. Our experiments show that retrieval augmentation substantially improves model performance on the long tail of infrequent labels especially so for lower-resource training scenarios and more challenging long-document data scenarios.
LeXFiles and LegalLAMA: Facilitating English Multinational Legal Language Model Development
May 22, 2023



In this work, we conduct a detailed analysis on the performance of legal-oriented pre-trained language models (PLMs). We examine the interplay between their original objective, acquired knowledge, and legal language understanding capacities which we define as the upstream, probing, and downstream performance, respectively. We consider not only the models' size but also the pre-training corpora used as important dimensions in our study. To this end, we release a multinational English legal corpus (LeXFiles) and a legal knowledge probing benchmark (LegalLAMA) to facilitate training and detailed analysis of legal-oriented PLMs. We release two new legal PLMs trained on LeXFiles and evaluate them alongside others on LegalLAMA and LexGLUE. We find that probing performance strongly correlates with upstream performance in related legal topics. On the other hand, downstream performance is mainly driven by the model's size and prior legal knowledge which can be estimated by upstream and probing performance. Based on these findings, we can conclude that both dimensions are important for those seeking the development of domain-specific PLMs.
An Exploration of Encoder-Decoder Approaches to Multi-Label Classification for Legal and Biomedical Text
May 09, 2023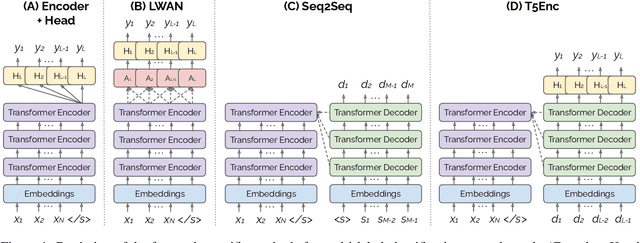
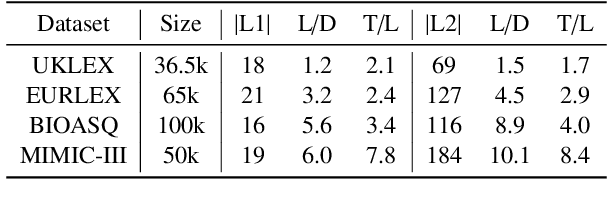
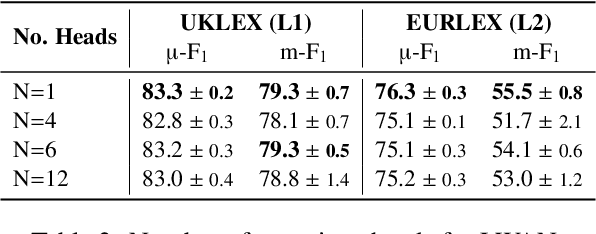
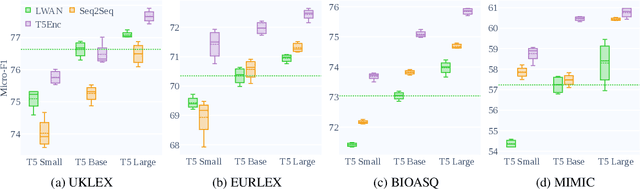
Standard methods for multi-label text classification largely rely on encoder-only pre-trained language models, whereas encoder-decoder models have proven more effective in other classification tasks. In this study, we compare four methods for multi-label classification, two based on an encoder only, and two based on an encoder-decoder. We carry out experiments on four datasets -- two in the legal domain and two in the biomedical domain, each with two levels of label granularity -- and always depart from the same pre-trained model, T5. Our results show that encoder-decoder methods outperform encoder-only methods, with a growing advantage on more complex datasets and labeling schemes of finer granularity. Using encoder-decoder models in a non-autoregressive fashion, in particular, yields the best performance overall, so we further study this approach through ablations to better understand its strengths.
LEXTREME: A Multi-Lingual and Multi-Task Benchmark for the Legal Domain
Jan 30, 2023



Lately, propelled by the phenomenal advances around the transformer architecture, the legal NLP field has enjoyed spectacular growth. To measure progress, well curated and challenging benchmarks are crucial. However, most benchmarks are English only and in legal NLP specifically there is no multilingual benchmark available yet. Additionally, many benchmarks are saturated, with the best models clearly outperforming the best humans and achieving near perfect scores. We survey the legal NLP literature and select 11 datasets covering 24 languages, creating LEXTREME. To provide a fair comparison, we propose two aggregate scores, one based on the datasets and one on the languages. The best baseline (XLM-R large) achieves both a dataset aggregate score a language aggregate score of 61.3. This indicates that LEXTREME is still very challenging and leaves ample room for improvement. To make it easy for researchers and practitioners to use, we release LEXTREME on huggingface together with all the code required to evaluate models and a public Weights and Biases project with all the runs.
Processing Long Legal Documents with Pre-trained Transformers: Modding LegalBERT and Longformer
Nov 10, 2022



Pre-trained Transformers currently dominate most NLP tasks. They impose, however, limits on the maximum input length (512 sub-words in BERT), which are too restrictive in the legal domain. Even sparse-attention models, such as Longformer and BigBird, which increase the maximum input length to 4,096 sub-words, severely truncate texts in three of the six datasets of LexGLUE. Simpler linear classifiers with TF-IDF features can handle texts of any length, require far less resources to train and deploy, but are usually outperformed by pre-trained Transformers. We explore two directions to cope with long legal texts: (i) modifying a Longformer warm-started from LegalBERT to handle even longer texts (up to 8,192 sub-words), and (ii) modifying LegalBERT to use TF-IDF representations. The first approach is the best in terms of performance, surpassing a hierarchical version of LegalBERT, which was the previous state of the art in LexGLUE. The second approach leads to computationally more efficient models at the expense of lower performance, but the resulting models still outperform overall a linear SVM with TF-IDF features in long legal document classification.
Legal-Tech Open Diaries: Lesson learned on how to develop and deploy light-weight models in the era of humongous Language Models
Oct 24, 2022



In the era of billion-parameter-sized Language Models (LMs), start-ups have to follow trends and adapt their technology accordingly. Nonetheless, there are open challenges since the development and deployment of large models comes with a need for high computational resources and has economical consequences. In this work, we follow the steps of the R&D group of a modern legal-tech start-up and present important insights on model development and deployment. We start from ground zero by pre-training multiple domain-specific multi-lingual LMs which are a better fit to contractual and regulatory text compared to the available alternatives (XLM-R). We present benchmark results of such models in a half-public half-private legal benchmark comprising 5 downstream tasks showing the impact of larger model size. Lastly, we examine the impact of a full-scale pipeline for model compression which includes: a) Parameter Pruning, b) Knowledge Distillation, and c) Quantization: The resulting models are much more efficient without sacrificing performance at large.
An Exploration of Hierarchical Attention Transformers for Efficient Long Document Classification
Oct 11, 2022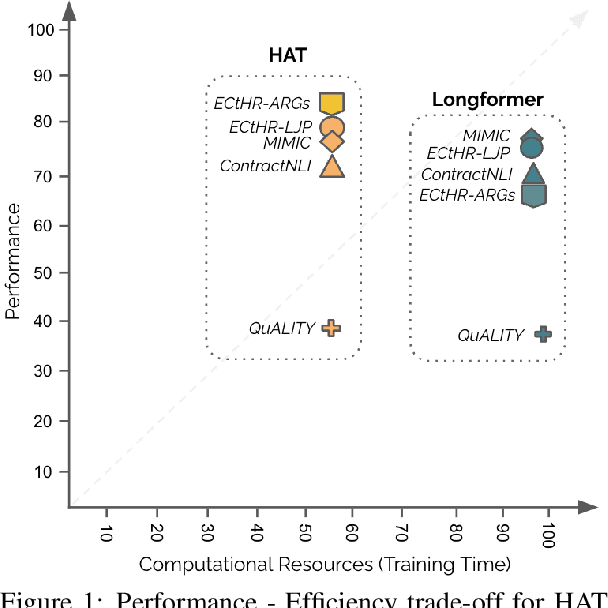

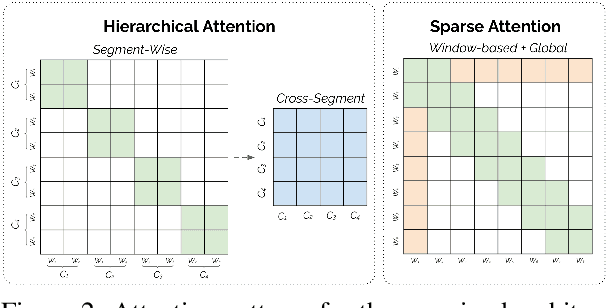
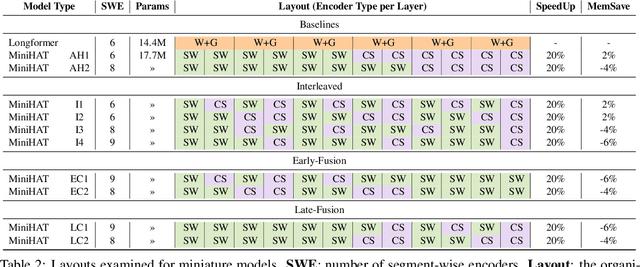
Non-hierarchical sparse attention Transformer-based models, such as Longformer and Big Bird, are popular approaches to working with long documents. There are clear benefits to these approaches compared to the original Transformer in terms of efficiency, but Hierarchical Attention Transformer (HAT) models are a vastly understudied alternative. We develop and release fully pre-trained HAT models that use segment-wise followed by cross-segment encoders and compare them with Longformer models and partially pre-trained HATs. In several long document downstream classification tasks, our best HAT model outperforms equally-sized Longformer models while using 10-20% less GPU memory and processing documents 40-45% faster. In a series of ablation studies, we find that HATs perform best with cross-segment contextualization throughout the model than alternative configurations that implement either early or late cross-segment contextualization. Our code is on GitHub: https://github.com/coastalcph/hierarchical-transformers.
An Empirical Study on Cross-X Transfer for Legal Judgment Prediction
Sep 25, 2022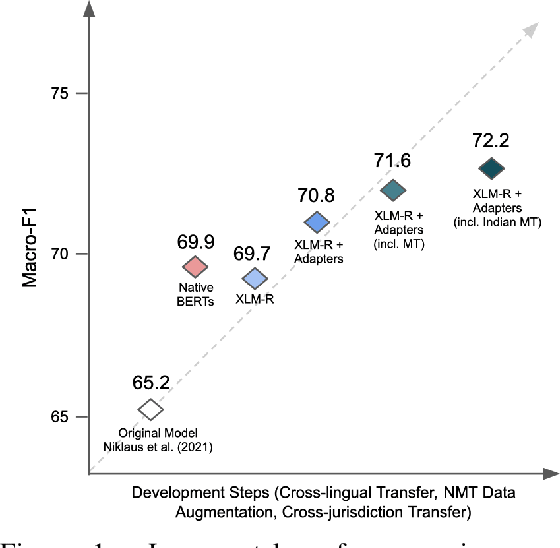
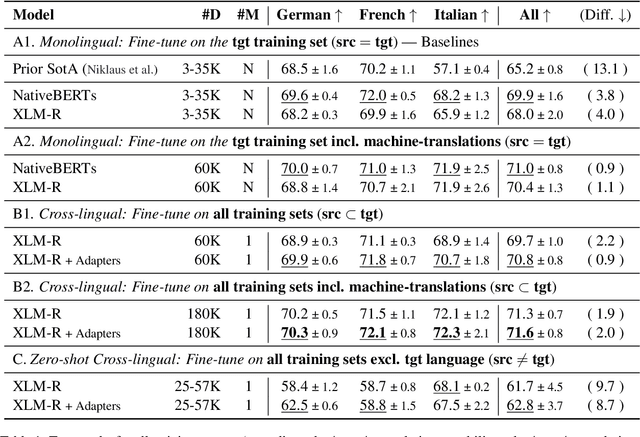
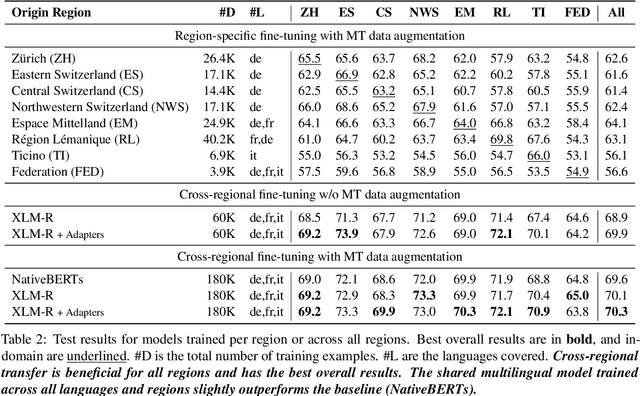
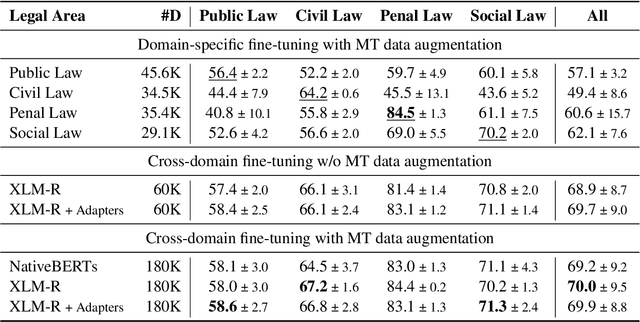
Cross-lingual transfer learning has proven useful in a variety of Natural Language Processing (NLP) tasks, but it is understudied in the context of legal NLP, and not at all in Legal Judgment Prediction (LJP). We explore transfer learning techniques on LJP using the trilingual Swiss-Judgment-Prediction dataset, including cases written in three languages. We find that cross-lingual transfer improves the overall results across languages, especially when we use adapter-based fine-tuning. Finally, we further improve the model's performance by augmenting the training dataset with machine-translated versions of the original documents, using a 3x larger training corpus. Further on, we perform an analysis exploring the effect of cross-domain and cross-regional transfer, i.e., train a model across domains (legal areas), or regions. We find that in both settings (legal areas, origin regions), models trained across all groups perform overall better, while they also have improved results in the worst-case scenarios. Finally, we report improved results when we ambitiously apply cross-jurisdiction transfer, where we further augment our dataset with Indian legal cases.