 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Associative Memory and Probabilistic Modeling
Feb 15, 2024



Associative memory and probabilistic modeling are two fundamental topics in artificial intelligence. The first studies recurrent neural networks designed to denoise, complete and retrieve data, whereas the second studies learning and sampling from probability distributions. Based on the observation that associative memory's energy functions can be seen as probabilistic modeling's negative log likelihoods, we build a bridge between the two that enables useful flow of ideas in both directions. We showcase four examples: First, we propose new energy-based models that flexibly adapt their energy functions to new in-context datasets, an approach we term \textit{in-context learning of energy functions}. Second, we propose two new associative memory models: one that dynamically creates new memories as necessitated by the training data using Bayesian nonparametrics, and another that explicitly computes proportional memory assignments using the evidence lower bound. Third, using tools from associative memory, we analytically and numerically characterize the memory capacity of Gaussian kernel density estimators, a widespread tool in probababilistic modeling. Fourth, we study a widespread implementation choice in transformers -- normalization followed by self attention -- to show it performs clustering on the hypersphere. Altogether, this work urges further exchange of useful ideas between these two continents of artificial intelligence.
Self-Supervised Learning of Representations for Space Generates Multi-Modular Grid Cells
Nov 04, 2023



To solve the spatial problems of mapping, localization and navigation, the mammalian lineage has developed striking spatial representations. One important spatial representation is the Nobel-prize winning grid cells: neurons that represent self-location, a local and aperiodic quantity, with seemingly bizarre non-local and spatially periodic activity patterns of a few discrete periods. Why has the mammalian lineage learnt this peculiar grid representation? Mathematical analysis suggests that this multi-periodic representation has excellent properties as an algebraic code with high capacity and intrinsic error-correction, but to date, there is no satisfactory synthesis of core principles that lead to multi-modular grid cells in deep recurrent neural networks. In this work, we begin by identifying key insights from four families of approaches to answering the grid cell question: coding theory, dynamical systems, function optimization and supervised deep learning. We then leverage our insights to propose a new approach that combines the strengths of all four approaches. Our approach is a self-supervised learning (SSL) framework - including data, data augmentations, loss functions and a network architecture - motivated from a normative perspective, without access to supervised position information or engineering of particular readout representations as needed in previous approaches. We show that multiple grid cell modules can emerge in networks trained on our SSL framework and that the networks and emergent representations generalize well outside their training distribution. This work contains insights for neuroscientists interested in the origins of grid cells as well as machine learning researchers interested in novel SSL frameworks.
Double Descent Demystified: Identifying, Interpreting & Ablating the Sources of a Deep Learning Puzzle
Mar 24, 2023



Double descent is a surprising phenomenon in machine learning, in which as the number of model parameters grows relative to the number of data, test error drops as models grow ever larger into the highly overparameterized (data undersampled) regime. This drop in test error flies against classical learning theory on overfitting and has arguably underpinned the success of large models in machine learning. This non-monotonic behavior of test loss depends on the number of data, the dimensionality of the data and the number of model parameters. Here, we briefly describe double descent, then provide an explanation of why double descent occurs in an informal and approachable manner, requiring only familiarity with linear algebra and introductory probability. We provide visual intuition using polynomial regression, then mathematically analyze double descent with ordinary linear regression and identify three interpretable factors that, when simultaneously all present, together create double descent. We demonstrate that double descent occurs on real data when using ordinary linear regression, then demonstrate that double descent does not occur when any of the three factors are ablated. We use this understanding to shed light on recent observations in nonlinear models concerning superposition and double descent. Code is publicly available.
Streaming Inference for Infinite Non-Stationary Clustering
May 02, 2022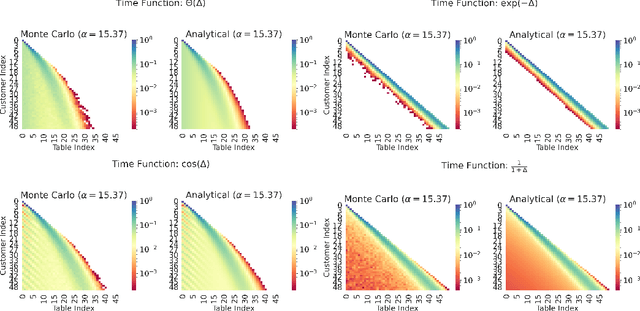



Learning from a continuous stream of non-stationary data in an unsupervised manner is arguably one of the most common and most challenging settings facing intelligent agents. Here, we attack learning under all three conditions (unsupervised, streaming, non-stationary) in the context of clustering, also known as mixture modeling. We introduce a novel clustering algorithm that endows mixture models with the ability to create new clusters online, as demanded by the data, in a probabilistic, time-varying, and principled manner. To achieve this, we first define a novel stochastic process called the Dynamical Chinese Restaurant Process (Dynamical CRP), which is a non-exchangeable distribution over partitions of a set; next, we show that the Dynamical CRP provides a non-stationary prior over cluster assignments and yields an efficient streaming variational inference algorithm. We conclude with experiments showing that the Dynamical CRP can be applied on diverse synthetic and real data with Gaussian and non-Gaussian likelihoods.