 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic-Aware Response Generation in Task-Oriented Dialogue with Unstructured Knowledge Access
Dec 10, 2022To alleviate the problem of structured databases' limited coverage, recent task-oriented dialogue systems incorporate external unstructured knowledge to guide the generation of system responses. However, these usually use word or sentence level similarities to detect the relevant knowledge context, which only partially capture the topical level relevance. In this paper, we examine how to better integrate topical information in knowledge grounded task-oriented dialogue and propose ``Topic-Aware Response Generation'' (TARG), an end-to-end response generation model. TARG incorporates multiple topic-aware attention mechanisms to derive the importance weighting scheme over dialogue utterances and external knowledge sources towards a better understanding of the dialogue history. Experimental results indicate that TARG achieves state-of-the-art performance in knowledge selection and response generation, outperforming previous state-of-the-art by 3.2, 3.6, and 4.2 points in EM, F1 and BLEU-4 respectively on Doc2Dial, and performing comparably with previous work on DSTC9; both being knowledge-grounded task-oriented dialogue datasets.
Training Dynamics for Curriculum Learning: A Study on Monolingual and Cross-lingual NLU
Oct 22, 2022Curriculum Learning (CL) is a technique of training models via ranking examples in a typically increasing difficulty trend with the aim of accelerating convergence and improving generalisability. Current approaches for Natural Language Understanding (NLU) tasks use CL to improve in-distribution data performance often via heuristic-oriented or task-agnostic difficulties. In this work, instead, we employ CL for NLU by taking advantage of training dynamics as difficulty metrics, i.e., statistics that measure the behavior of the model at hand on specific task-data instances during training and propose modifications of existing CL schedulers based on these statistics. Differently from existing works, we focus on evaluating models on in-distribution (ID), out-of-distribution (OOD) as well as zero-shot (ZS) cross-lingual transfer datasets. We show across several NLU tasks that CL with training dynamics can result in better performance mostly on zero-shot cross-lingual transfer and OOD settings with improvements up by 8.5% in certain cases. Overall, experiments indicate that training dynamics can lead to better performing models with smoother training compared to other difficulty metrics while being 20% faster on average. In addition, through analysis we shed light on the correlations of task-specific versus task-agnostic metrics.
EntityCS: Improving Zero-Shot Cross-lingual Transfer with Entity-Centric Code Switching
Oct 22, 2022Accurate alignment between languages is fundamental for improving cross-lingual pre-trained language models (XLMs). Motivated by the natural phenomenon of code-switching (CS) in multilingual speakers, CS has been used as an effective data augmentation method that offers language alignment at word- or phrase-level, in contrast to sentence-level via parallel instances. Existing approaches either use dictionaries or parallel sentences with word-alignment to generate CS data by randomly switching words in a sentence. However, such methods can be suboptimal as dictionaries disregard semantics, and syntax might become invalid after random word switching. In this work, we propose EntityCS, a method that focuses on Entity-level Code-Switching to capture fine-grained cross-lingual semantics without corrupting syntax. We use Wikidata and the English Wikipedia to construct an entity-centric CS corpus by switching entities to their counterparts in other languages. We further propose entity-oriented masking strategies during intermediate model training on the EntityCS corpus for improving entity prediction. Evaluation of the trained models on four entity-centric downstream tasks shows consistent improvements over the baseline with a notable increase of 10% in Fact Retrieval. We release the corpus and models to assist research on code-switching and enriching XLMs with external knowledge.
Relational Graph Convolutional Neural Networks for Multihop Reasoning: A Comparative Study
Oct 13, 2022
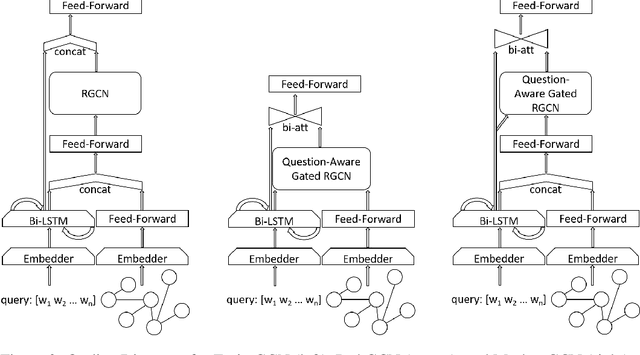


Multihop Question Answering is a complex Natural Language Processing task that requires multiple steps of reasoning to find the correct answer to a given question. Previous research has explored the use of models based on Graph Neural Networks for tackling this task. Various architectures have been proposed, including Relational Graph Convolutional Networks (RGCN). For these many node types and relations between them have been introduced, such as simple entity co-occurrences, modelling coreferences, or "reasoning paths" from questions to answers via intermediary entities. Nevertheless, a thoughtful analysis on which relations, node types, embeddings and architecture are the most beneficial for this task is still missing. In this paper we explore a number of RGCN-based Multihop QA models, graph relations, and node embeddings, and empirically explore the influence of each on Multihop QA performance on the WikiHop dataset.
PanGu-Coder: Program Synthesis with Function-Level Language Modeling
Jul 22, 2022
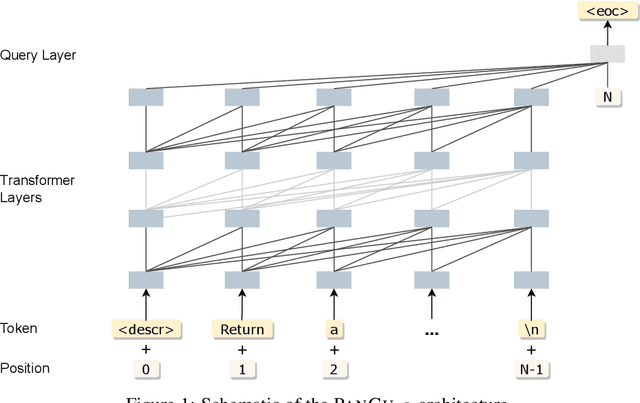
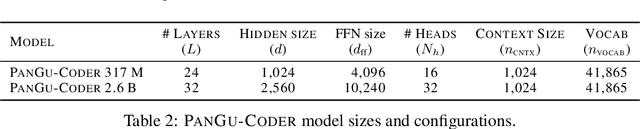
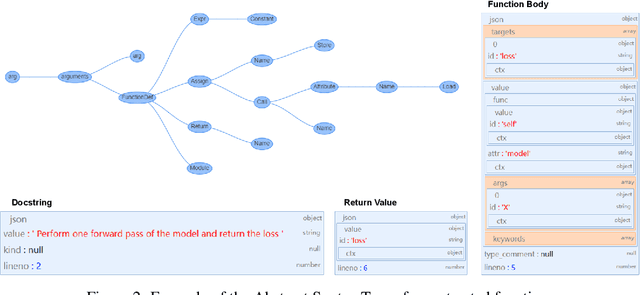
We present PanGu-Coder, a pretrained decoder-only language model adopting the PanGu-Alpha architecture for text-to-code generation, i.e. the synthesis of programming language solutions given a natural language problem description. We train PanGu-Coder using a two-stage strategy: the first stage employs Causal Language Modelling (CLM) to pre-train on raw programming language data, while the second stage uses a combination of Causal Language Modelling and Masked Language Modelling (MLM) training objectives that focus on the downstream task of text-to-code generation and train on loosely curated pairs of natural language program definitions and code functions. Finally, we discuss PanGu-Coder-FT, which is fine-tuned on a combination of competitive programming problems and code with continuous integration tests. We evaluate PanGu-Coder with a focus on whether it generates functionally correct programs and demonstrate that it achieves equivalent or better performance than similarly sized models, such as CodeX, while attending a smaller context window and training on less data.
XQA-DST: Multi-Domain and Multi-Lingual Dialogue State Tracking
Apr 12, 2022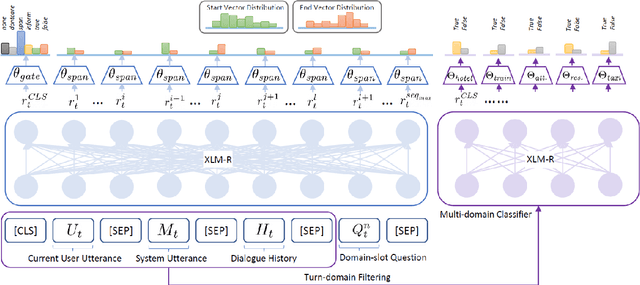
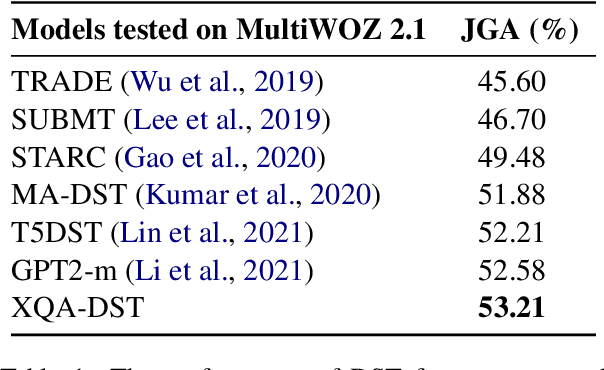

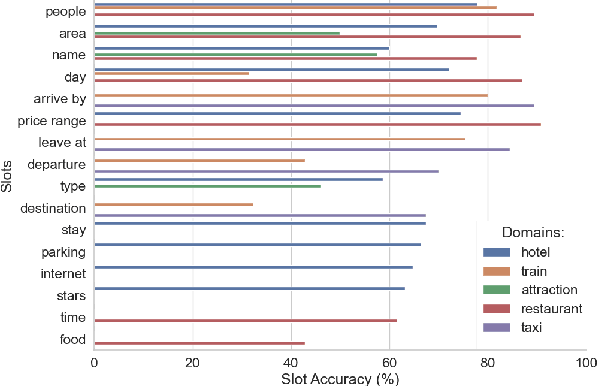
In a task-oriented dialogue system, Dialogue State Tracking (DST) keeps track of all important information by filling slots with values given through the conversation. Existing methods generally rely on a predefined set of values and struggle to generalise to previously unseen slots in new domains. In this paper, we propose a multi-domain and multi-lingual dialogue state tracker in a neural reading comprehension approach. Our approach fills the slot values using span prediction, where the values are extracted from the dialogue itself. With a novel training strategy and an independent domain classifier, empirical results demonstrate that our model is a domain-scalable and open-vocabulary model that achieves 53.2% Joint Goal Accuracy (JGA) on MultiWOZ 2.1. We show its competitive transferability by zero-shot domain-adaptation experiments on MultiWOZ 2.1 with an average JGA of 31.6% for five domains. In addition, it achieves cross-lingual transfer with state-of-the-art zero-shot results, 64.9% JGA from English to German and 68.6% JGA from English to Italian on WOZ 2.0.
CrossAligner & Co: Zero-Shot Transfer Methods for Task-Oriented Cross-lingual Natural Language Understanding
Mar 18, 2022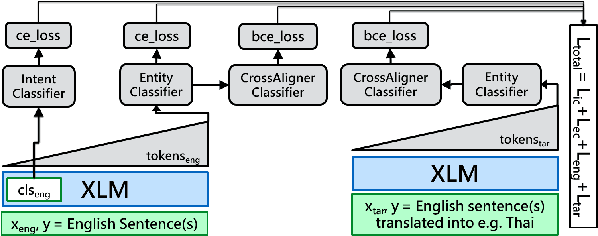
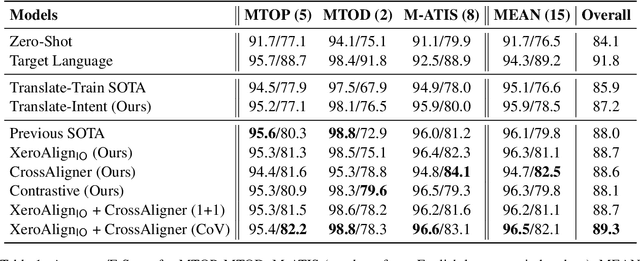
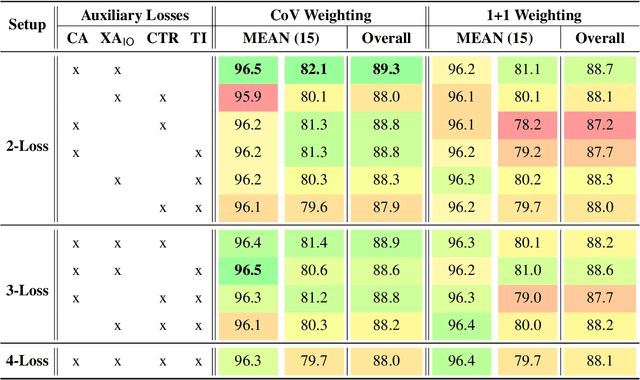
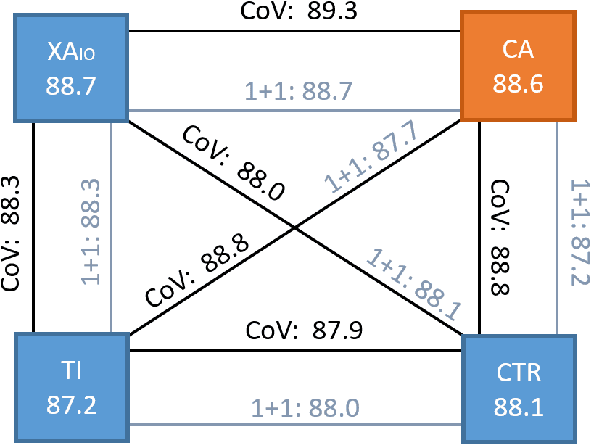
Task-oriented personal assistants enable people to interact with a host of devices and services using natural language. One of the challenges of making neural dialogue systems available to more users is the lack of training data for all but a few languages. Zero-shot methods try to solve this issue by acquiring task knowledge in a high-resource language such as English with the aim of transferring it to the low-resource language(s). To this end, we introduce CrossAligner, the principal method of a variety of effective approaches for zero-shot cross-lingual transfer based on learning alignment from unlabelled parallel data. We present a quantitative analysis of individual methods as well as their weighted combinations, several of which exceed state-of-the-art (SOTA) scores as evaluated across nine languages, fifteen test sets and three benchmark multilingual datasets. A detailed qualitative error analysis of the best methods shows that our fine-tuned language models can zero-shot transfer the task knowledge better than anticipated.
Enhancing Transformers with Gradient Boosted Decision Trees for NLI Fine-Tuning
May 08, 2021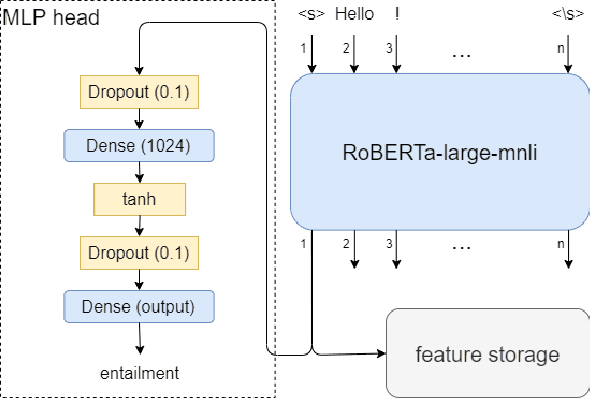
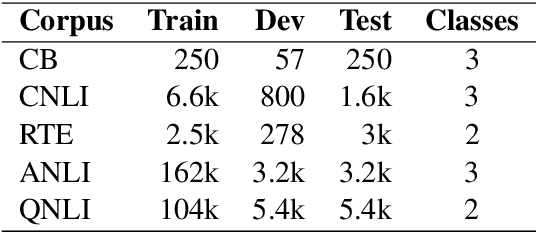
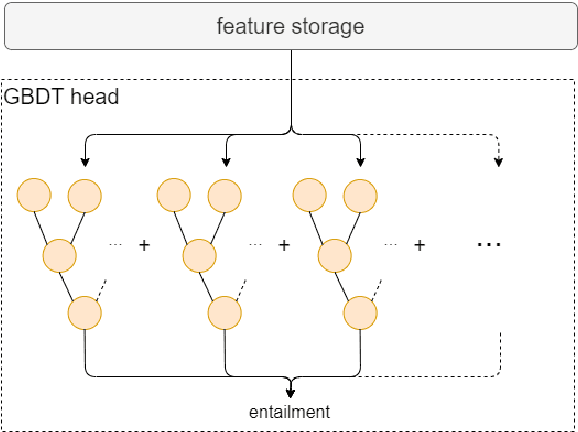

Transfer learning has become the dominant paradigm for many natural language processing tasks. In addition to models being pretrained on large datasets, they can be further trained on intermediate (supervised) tasks that are similar to the target task. For small Natural Language Inference (NLI) datasets, language modelling is typically followed by pretraining on a large (labelled) NLI dataset before fine-tuning with each NLI subtask. In this work, we explore Gradient Boosted Decision Trees (GBDTs) as an alternative to the commonly used Multi-Layer Perceptron (MLP) classification head. GBDTs have desirable properties such as good performance on dense, numerical features and are effective where the ratio of the number of samples w.r.t the number of features is low. We then introduce FreeGBDT, a method of fitting a GBDT head on the features computed during fine-tuning to increase performance without additional computation by the neural network. We demonstrate the effectiveness of our method on several NLI datasets using a strong baseline model (RoBERTa-large with MNLI pretraining). The FreeGBDT shows a consistent improvement over the MLP classification head.
XeroAlign: Zero-Shot Cross-lingual Transformer Alignment
May 06, 2021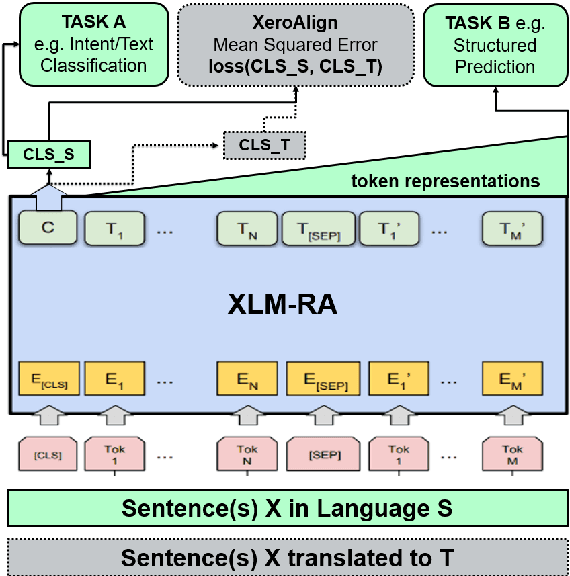

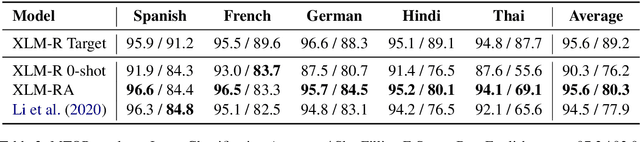
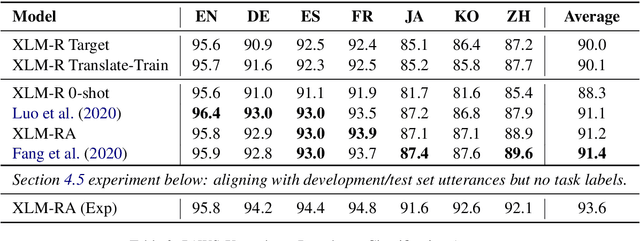
The introduction of pretrained cross-lingual language models brought decisive improvements to multilingual NLP tasks. However, the lack of labelled task data necessitates a variety of methods aiming to close the gap to high-resource languages. Zero-shot methods in particular, often use translated task data as a training signal to bridge the performance gap between the source and target language(s). We introduce XeroAlign, a simple method for task-specific alignment of cross-lingual pretrained transformers such as XLM-R. XeroAlign uses translated task data to encourage the model to generate similar sentence embeddings for different languages. The XeroAligned XLM-R, called XLM-RA, shows strong improvements over the baseline models to achieve state-of-the-art zero-shot results on three multilingual natural language understanding tasks. XLM-RA's text classification accuracy exceeds that of XLM-R trained with labelled data and performs on par with state-of-the-art models on a cross-lingual adversarial paraphrasing task.
Improving Commonsense Causal Reasoning by Adversarial Training and Data Augmentation
Jan 13, 2021
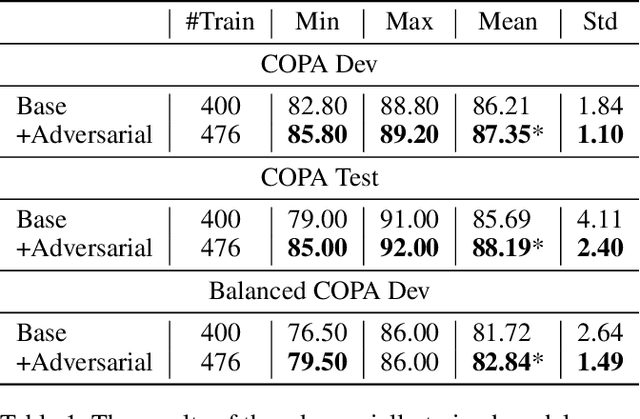
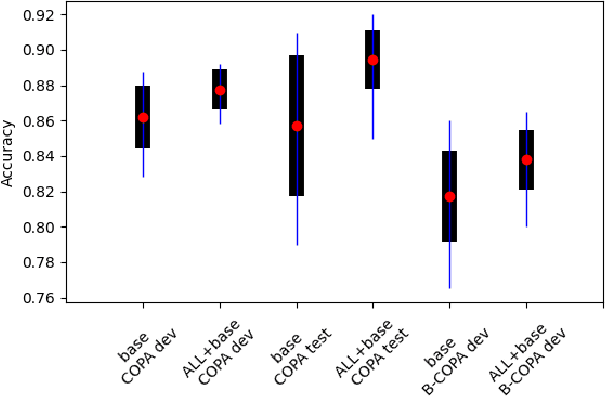
Determining the plausibility of causal relations between clauses is a commonsense reasoning task that requires complex inference ability. The general approach to this task is to train a large pretrained language model on a specific dataset. However, the available training data for the task is often scarce, which leads to instability of model training or reliance on the shallow features of the dataset. This paper presents a number of techniques for making models more robust in the domain of causal reasoning. Firstly, we perform adversarial training by generating perturbed inputs through synonym substitution. Secondly, based on a linguistic theory of discourse connectives, we perform data augmentation using a discourse parser for detecting causally linked clauses in large text, and a generative language model for generating distractors. Both methods boost model performance on the Choice of Plausible Alternatives (COPA) dataset, as well as on a Balanced COPA dataset, which is a modified version of the original data that has been developed to avoid superficial cues, leading to a more challenging benchmark. We show a statistically significant improvement in performance and robustness on both datasets, even with only a small number of additionally generated data points.