 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Modeling with Multiple Attributes for Watchlist Recommendation in E-Commerce
Oct 24, 2021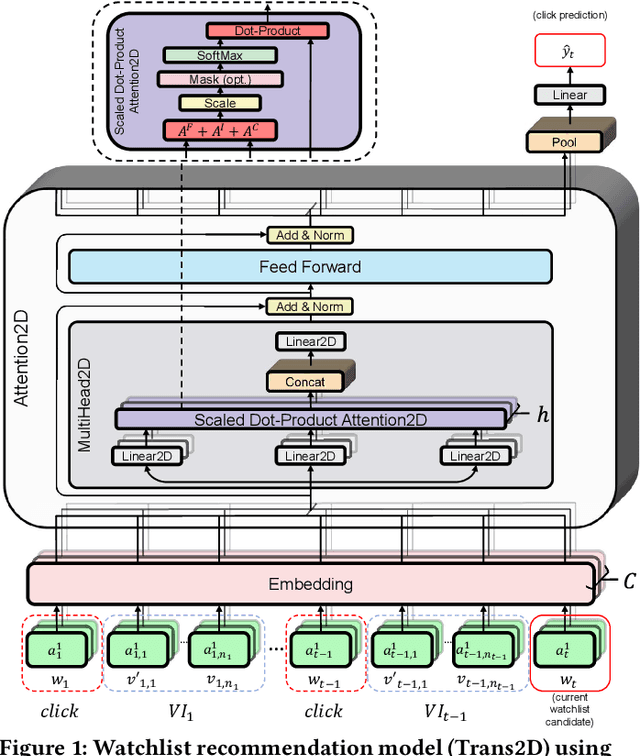
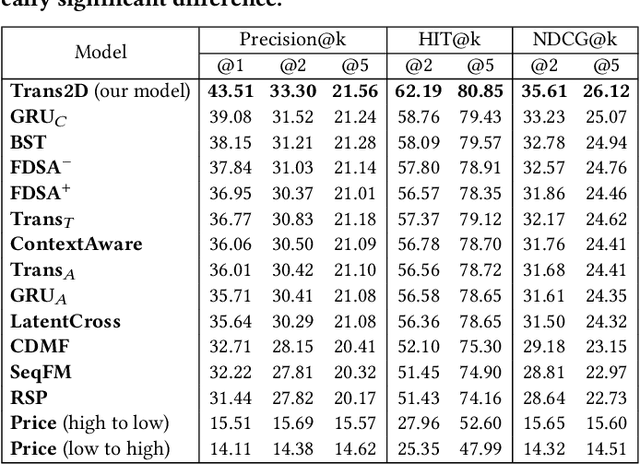

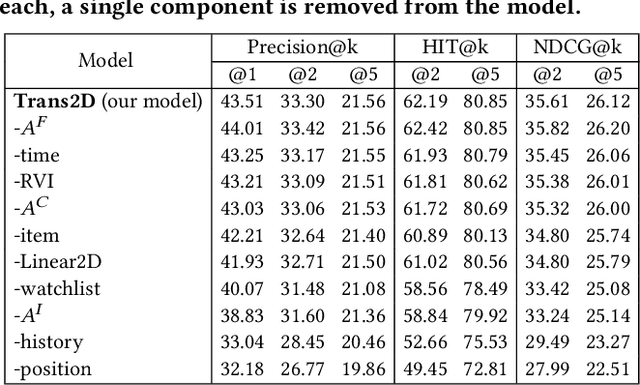
In e-commerce, the watchlist enables users to track items over time and has emerged as a primary feature, playing an important role in users' shopping journey. Watchlist items typically have multiple attributes whose values may change over time (e.g., price, quantity). Since many users accumulate dozens of items on their watchlist, and since shopping intents change over time, recommending the top watchlist items in a given context can be valuable. In this work, we study the watchlist functionality in e-commerce and introduce a novel watchlist recommendation task. Our goal is to prioritize which watchlist items the user should pay attention to next by predicting the next items the user will click. We cast this task as a specialized sequential recommendation task and discuss its characteristics. Our proposed recommendation model, Trans2D, is built on top of the Transformer architecture, where we further suggest a novel extended attention mechanism (Attention2D) that allows to learn complex item-item, attribute-attribute and item-attribute patterns from sequential-data with multiple item attributes. Using a large-scale watchlist dataset from eBay, we evaluate our proposed model, where we demonstrate its superiority compared to multiple state-of-the-art baselines, many of which are adapted for this task.
Time Masking for Temporal Language Models
Oct 22, 2021

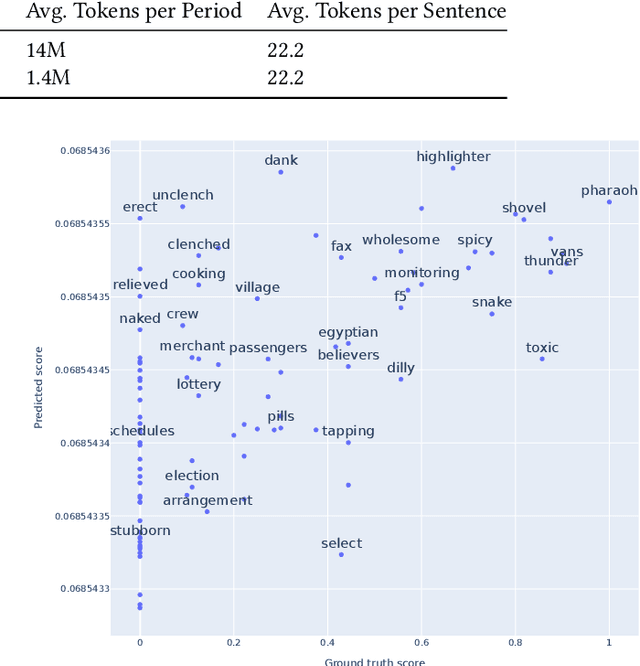
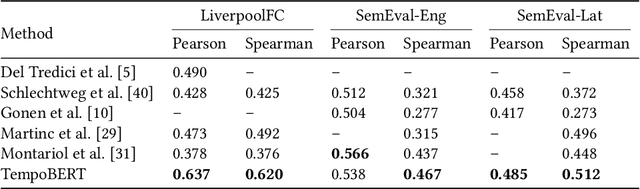
Our world is constantly evolving, and so is the content on the web. Consequently, our languages, often said to mirror the world, are dynamic in nature. However, most current contextual language models are static and cannot adapt to changes over time. In this work, we propose a temporal contextual language model called TempoBERT, which uses time as an additional context of texts. Our technique is based on modifying texts with temporal information and performing time masking - specific masking for the supplementary time information. We leverage our approach for the tasks of semantic change detection and sentence time prediction, experimenting on diverse datasets in terms of time, size, genre, and language. Our extensive evaluation shows that both tasks benefit from exploiting time masking.
E-Commerce Dispute Resolution Prediction
Oct 13, 2021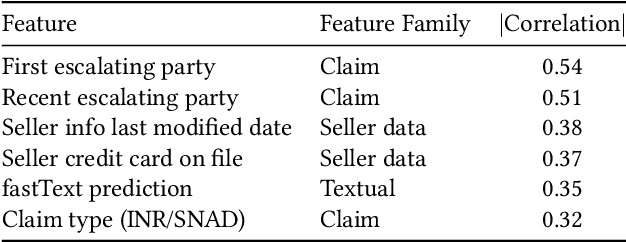
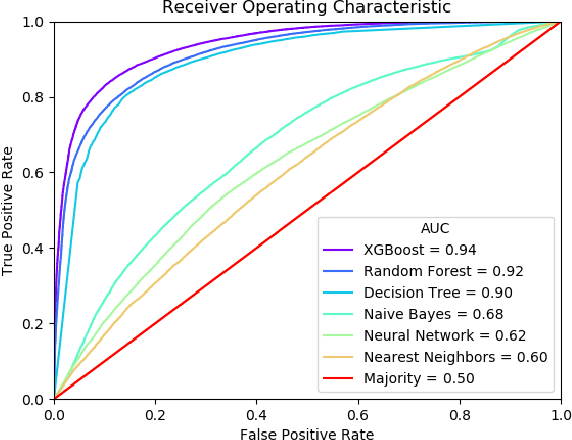
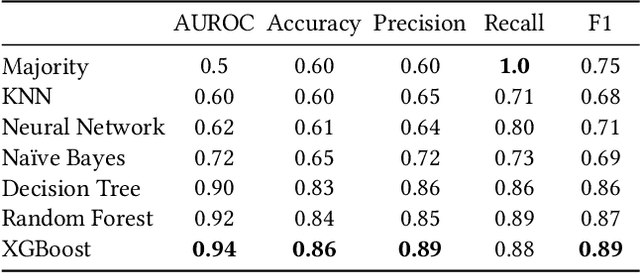

E-Commerce marketplaces support millions of daily transactions, and some disagreements between buyers and sellers are unavoidable. Resolving disputes in an accurate, fast, and fair manner is of great importance for maintaining a trustworthy platform. Simple cases can be automated, but intricate cases are not sufficiently addressed by hard-coded rules, and therefore most disputes are currently resolved by people. In this work we take a first step towards automatically assisting human agents in dispute resolution at scale. We construct a large dataset of disputes from the eBay online marketplace, and identify several interesting behavioral and linguistic patterns. We then train classifiers to predict dispute outcomes with high accuracy. We explore the model and the dataset, reporting interesting correlations, important features, and insights.
Event-Driven Query Expansion
Dec 22, 2020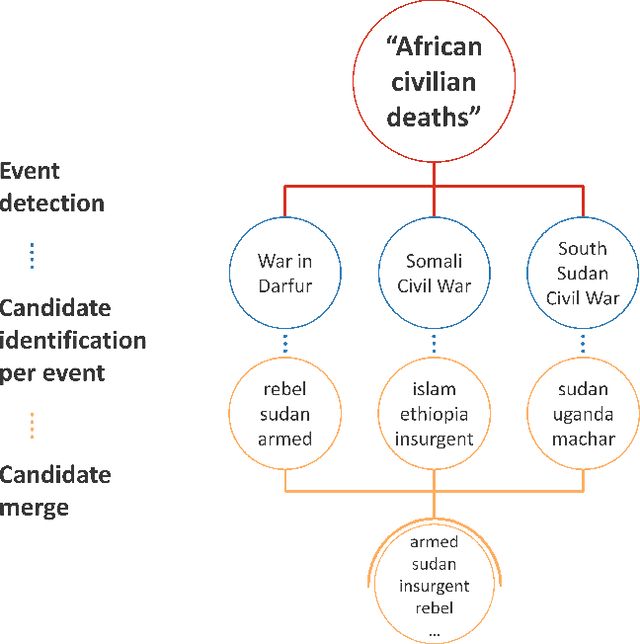
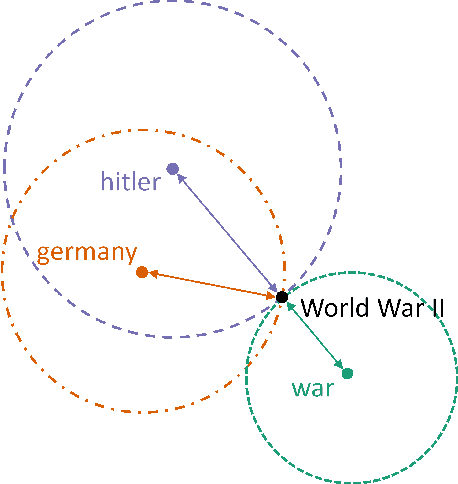
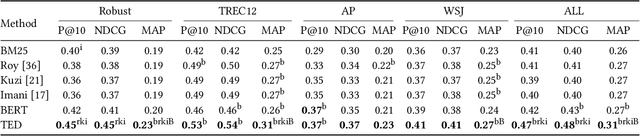
A significant number of event-related queries are issued in Web search. In this paper, we seek to improve retrieval performance by leveraging events and specifically target the classic task of query expansion. We propose a method to expand an event-related query by first detecting the events related to it. Then, we derive the candidates for expansion as terms semantically related to both the query and the events. To identify the candidates, we utilize a novel mechanism to simultaneously embed words and events in the same vector space. We show that our proposed method of leveraging events improves query expansion performance significantly compared with state-of-the-art methods on various newswire TREC datasets.
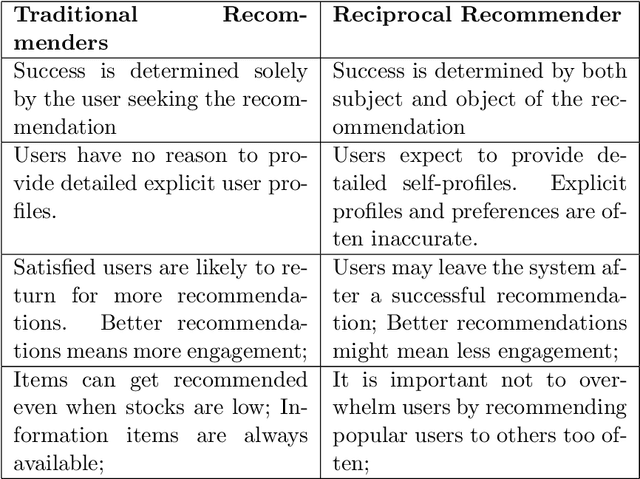
Reciprocal Recommender Systems: Analysis of State-of-Art Literature, Challenges and Opportunities on Social Recommendation
Jul 17, 2020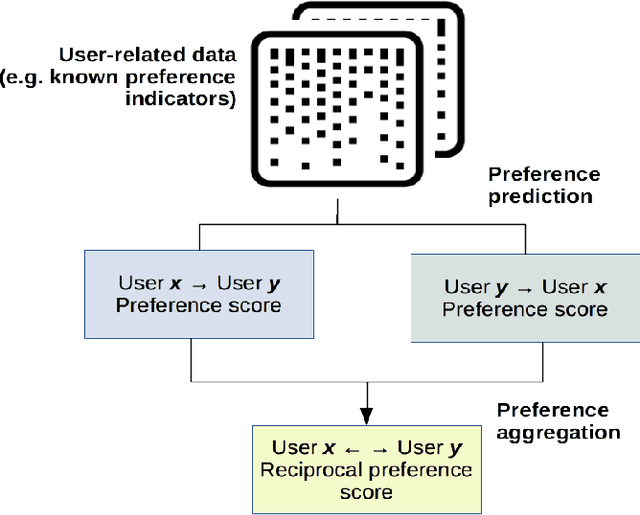
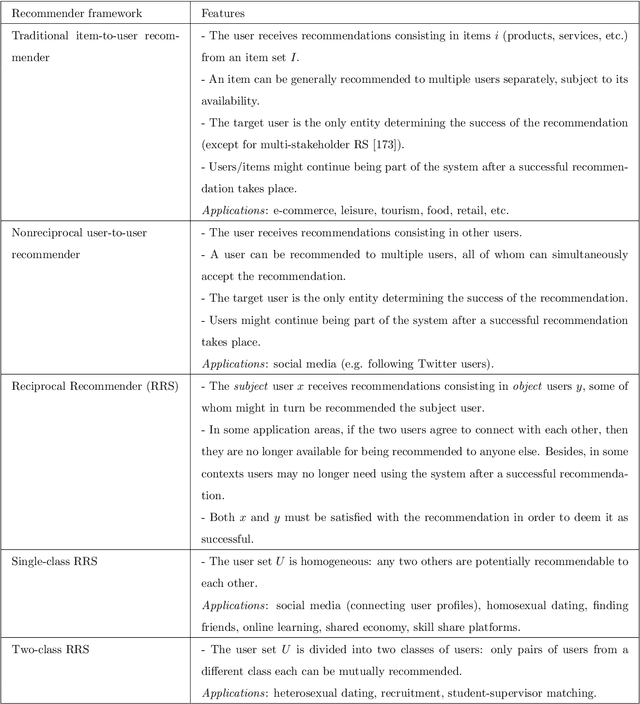
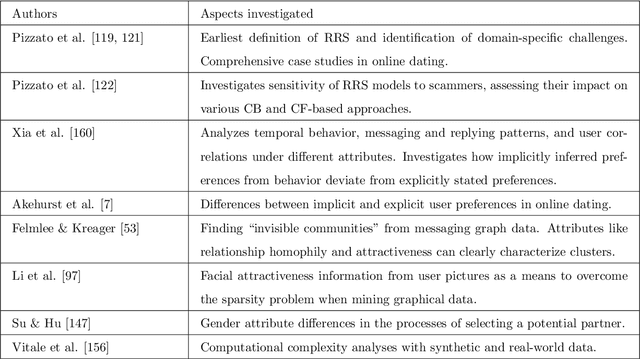
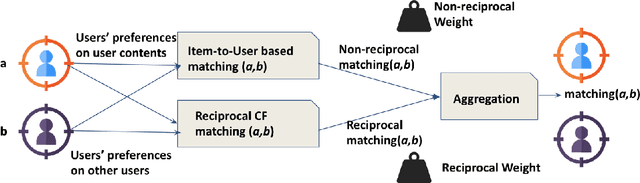
Many social services including online dating, social media, recruitment and online learning, largely rely on \matching people with the right people". The success of these services and the user experience with them often depends on their ability to match users. Reciprocal Recommender Systems (RRS) arose to facilitate this process by identifying users who are a potential match for each other, based on information provided by them. These systems are inherently more complex than user-item recommendation approaches and unidirectional user recommendation services, since they need to take into account both users' preferences towards each other in the recommendation process. This entails not only predicting accurate preference estimates as classical recommenders do, but also defining adequate fusion processes for aggregating user-to-user preferential information. The latter is a crucial and distinctive, yet barely investigated aspect in RRS research. This paper presents a snapshot analysis of the extant literature to summarize the state-of-the-art RRS research to date, focusing on the fundamental features that differentiate RRSs from other classes of recommender systems. Following this, we discuss the challenges and opportunities for future research on RRSs, with special focus on (i) fusion strategies to account for reciprocity and (ii) emerging application domains related to social recommendation.
Beyond Personalization: Research Directions in Multistakeholder Recommendation
May 01, 2019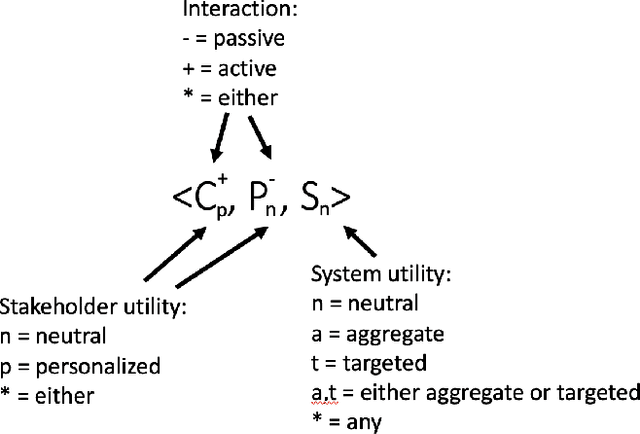

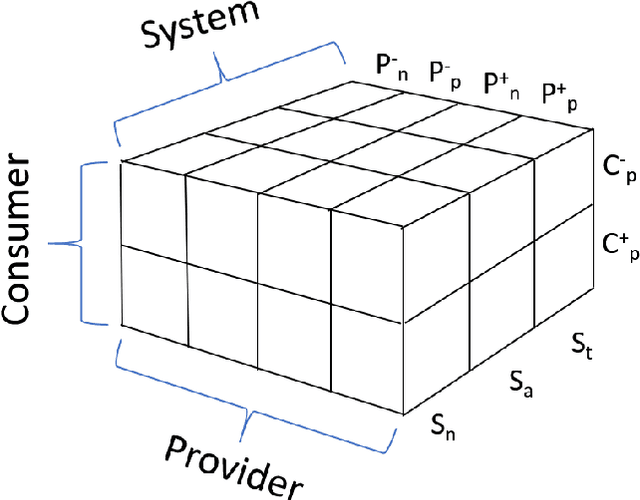
Recommender systems are personalized information access applications; they are ubiquitous in today's online environment, and effective at finding items that meet user needs and tastes. As the reach of recommender systems has extended, it has become apparent that the single-minded focus on the user common to academic research has obscured other important aspects of recommendation outcomes. Properties such as fairness, balance, profitability, and reciprocity are not captured by typical metrics for recommender system evaluation. The concept of multistakeholder recommendation has emerged as a unifying framework for describing and understanding recommendation settings where the end user is not the sole focus. This article describes the origins of multistakeholder recommendation, and the landscape of system designs. It provides illustrative examples of current research, as well as outlining open questions and research directions for the field.
Node Embedding over Temporal Graphs
Apr 02, 2019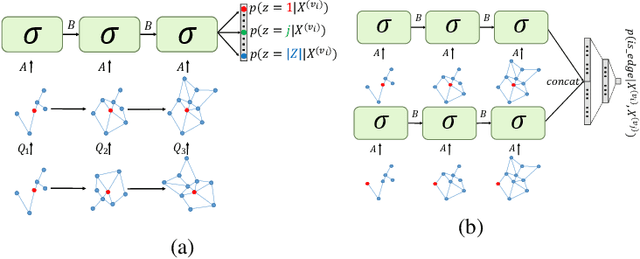
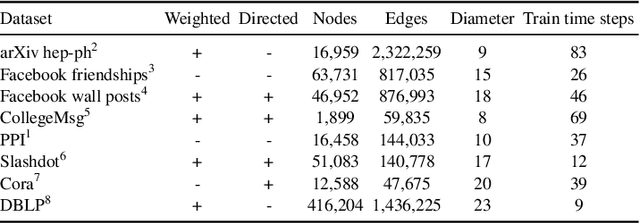

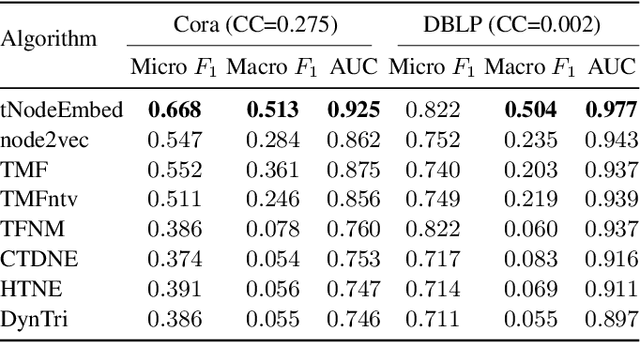
In this work, we present a method for node embedding in temporal graphs. We propose an algorithm that learns the evolution of a temporal graph's nodes and edges over time and incorporates this dynamics in a temporal node embedding framework for different graph prediction tasks. We present a joint loss function that creates a temporal embedding of a node by learning to combine its historical temporal embeddings, such that it optimizes per given task (e.g., link prediction). The algorithm is initialized using static node embeddings, which are then aligned over the representations of a node at different time points, and eventually adapted for the given task in a joint optimization. We evaluate the effectiveness of our approach over a variety of temporal graphs for the two fundamental tasks of temporal link prediction and multi-label node classification, comparing to competitive baselines and algorithmic alternatives. Our algorithm shows performance improvements across many of the datasets and baselines and is found particularly effective for graphs that are less cohesive, with a lower clustering coefficient.
Implicit Dimension Identification in User-Generated Text with LSTM Networks
Feb 01, 2019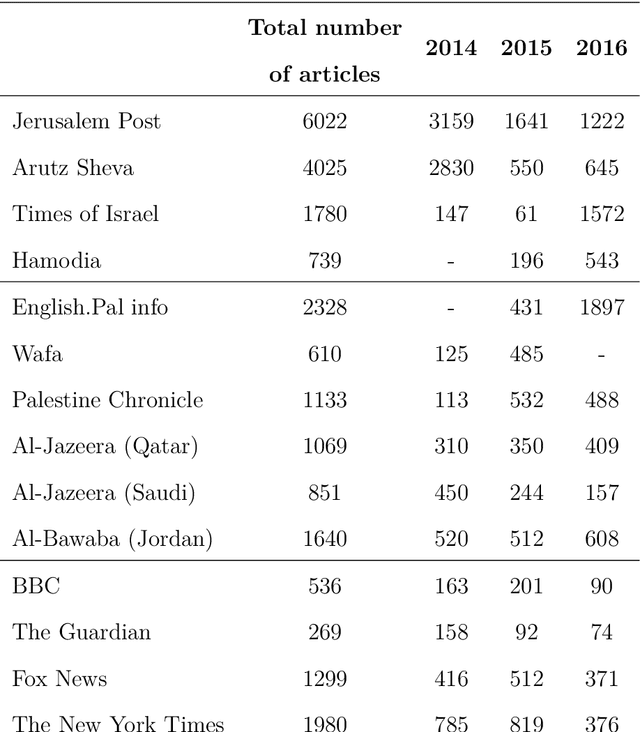


In the process of online storytelling, individual users create and consume highly diverse content that contains a great deal of implicit beliefs and not plainly expressed narrative. It is hard to manually detect these implicit beliefs, intentions and moral foundations of the writers. We study and investigate two different tasks, each of which reflect the difficulty of detecting an implicit user's knowledge, intent or belief that may be based on writer's moral foundation: 1) political perspective detection in news articles 2) identification of informational vs. conversational questions in community question answering (CQA) archives and. In both tasks we first describe new interesting annotated datasets and make the datasets publicly available. Second, we compare various classification algorithms, and show the differences in their performance on both tasks. Third, in political perspective detection task we utilize a narrative representation language of local press to identify perspective differences between presumably neutral American and British press.