 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow "Multi" is Multi-Document Summarization?
Oct 23, 2022



The task of multi-document summarization (MDS) aims at models that, given multiple documents as input, are able to generate a summary that combines disperse information, originally spread across these documents. Accordingly, it is expected that both reference summaries in MDS datasets, as well as system summaries, would indeed be based on such dispersed information. In this paper, we argue for quantifying and assessing this expectation. To that end, we propose an automated measure for evaluating the degree to which a summary is ``disperse'', in the sense of the number of source documents needed to cover its content. We apply our measure to empirically analyze several popular MDS datasets, with respect to their reference summaries, as well as the output of state-of-the-art systems. Our results show that certain MDS datasets barely require combining information from multiple documents, where a single document often covers the full summary content. Overall, we advocate using our metric for assessing and improving the degree to which summarization datasets require combining multi-document information, and similarly how summarization models actually meet this challenge. Our code is available in https://github.com/ariecattan/multi_mds.
Cross-document Event Coreference Search: Task, Dataset and Modeling
Oct 23, 2022The task of Cross-document Coreference Resolution has been traditionally formulated as requiring to identify all coreference links across a given set of documents. We propose an appealing, and often more applicable, complementary set up for the task - Cross-document Coreference Search, focusing in this paper on event coreference. Concretely, given a mention in context of an event of interest, considered as a query, the task is to find all coreferring mentions for the query event in a large document collection. To support research on this task, we create a corresponding dataset, which is derived from Wikipedia while leveraging annotations in the available Wikipedia Event Coreference dataset (WEC-Eng). Observing that the coreference search setup is largely analogous to the setting of Open Domain Question Answering, we adapt the prominent Deep Passage Retrieval (DPR) model to our setting, as an appealing baseline. Finally, we present a novel model that integrates a powerful coreference scoring scheme into the DPR architecture, yielding improved performance.
QASem Parsing: Text-to-text Modeling of QA-based Semantics
May 23, 2022
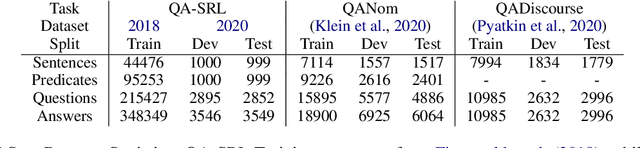
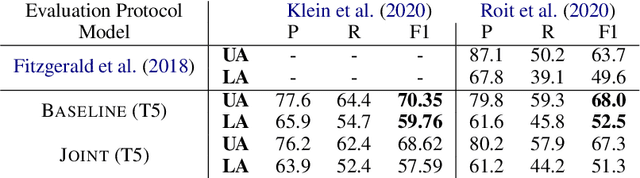
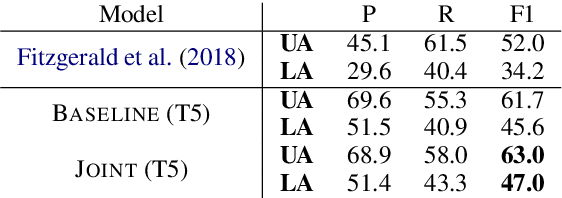
Several recent works have suggested to represent semantic relations with questions and answers, decomposing textual information into separate interrogative natural language statements. In this paper, we consider three QA-based semantic tasks - namely, QA-SRL, QANom and QADiscourse, each targeting a certain type of predication - and propose to regard them as jointly providing a comprehensive representation of textual information. To promote this goal, we investigate how to best utilize the power of sequence-to-sequence (seq2seq) pre-trained language models, within the unique setup of semi-structured outputs, consisting of an unordered set of question-answer pairs. We examine different input and output linearization strategies, and assess the effect of multitask learning and of simple data augmentation techniques in the setting of imbalanced training data. Consequently, we release the first unified QASem parsing tool, practical for downstream applications who can benefit from an explicit, QA-based account of information units in a text.
Utilizing Evidence Spans via Sequence-Level Contrastive Learning for Long-Context Question Answering
Dec 16, 2021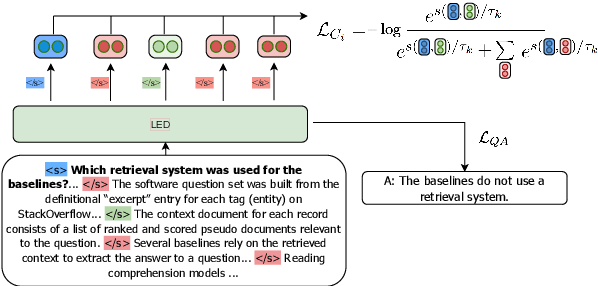

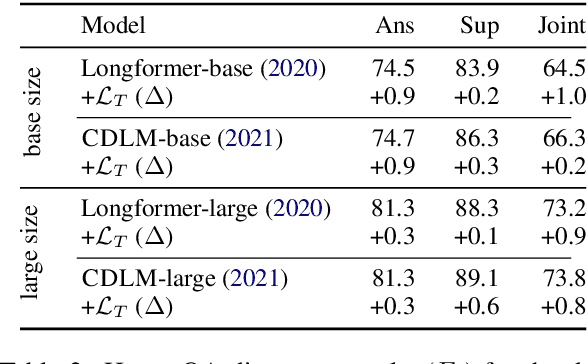
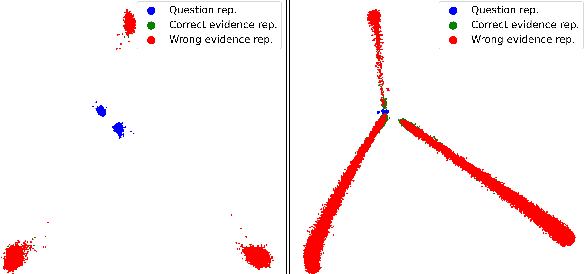
Long-range transformer models have achieved encouraging results on long-context question answering (QA) tasks. Such tasks often require reasoning over a long document, and they benefit from identifying a set of evidence spans (e.g., sentences) that provide supporting evidence for addressing the question. In this work, we propose a novel method for equipping long-range transformers with an additional sequence-level objective for better identification of supporting evidence spans. We achieve this by proposing an additional contrastive supervision signal in finetuning, where the model is encouraged to explicitly discriminate supporting evidence sentences from negative ones by maximizing the question-evidence similarity. The proposed additional loss exhibits consistent improvements on three different strong long-context transformer models, across two challenging question answering benchmarks - HotpotQA and QAsper.
A Proposition-Level Clustering Approach for Multi-Document Summarization
Dec 16, 2021
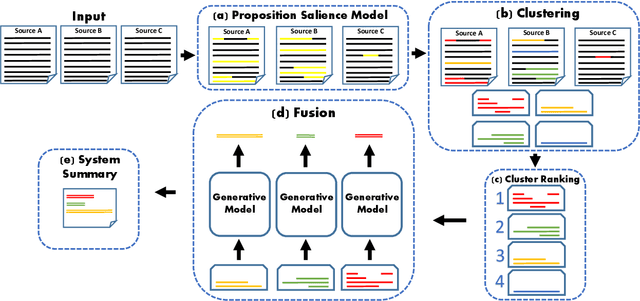

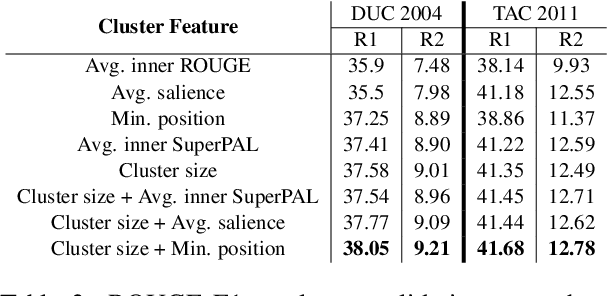
Text clustering methods were traditionally incorporated into multi-document summarization (MDS) as a means for coping with considerable information repetition. Clusters were leveraged to indicate information saliency and to avoid redundancy. These methods focused on clustering sentences, even though closely related sentences also usually contain non-aligning information. In this work, we revisit the clustering approach, grouping together propositions for more precise information alignment. Specifically, our method detects salient propositions, clusters them into paraphrastic clusters, and generates a representative sentence for each cluster by fusing its propositions. Our summarization method improves over the previous state-of-the-art MDS method in the DUC 2004 and TAC 2011 datasets, both in automatic ROUGE scores and human preference.
Extending Multi-Text Sentence Fusion Resources via Pyramid Annotations
Oct 09, 2021


NLP models that compare or consolidate information across multiple documents often struggle when challenged with recognizing substantial information redundancies across the texts. For example, in multi-document summarization it is crucial to identify salient information across texts and then generate a non-redundant summary, while facing repeated and usually differently-phrased salient content. To facilitate researching such challenges, the sentence-level task of \textit{sentence fusion} was proposed, yet previous datasets for this task were very limited in their size and scope. In this paper, we revisit and substantially extend previous dataset creation efforts. With careful modifications, relabeling and employing complementing data sources, we were able to triple the size of a notable earlier dataset. Moreover, we show that our extended version uses more representative texts for multi-document tasks and provides a larger and more diverse training set, which substantially improves model training.
Multi-Document Keyphrase Extraction: A Literature Review and the First Dataset
Oct 03, 2021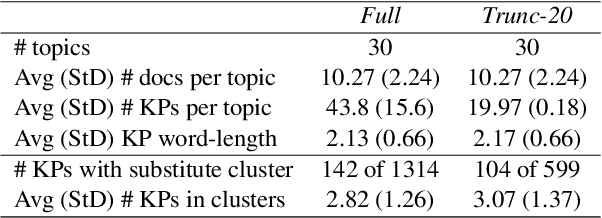
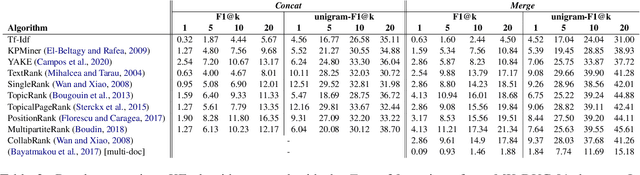
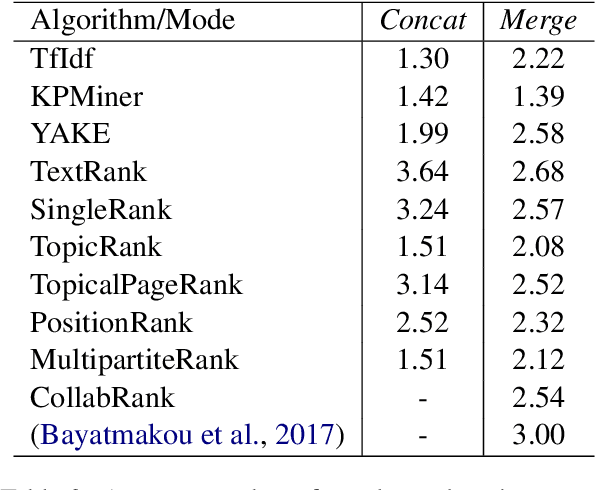
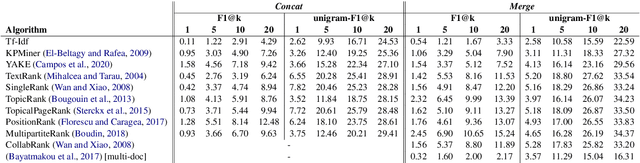
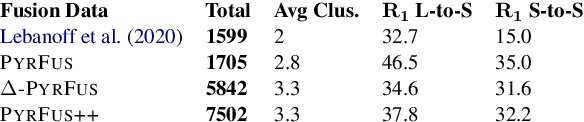
Keyphrase extraction has been comprehensively researched within the single-document setting, with an abundance of methods and a wealth of datasets. In contrast, multi-document keyphrase extraction has been infrequently studied, despite its utility for describing sets of documents, and its use in summarization. Moreover, no dataset existed for multi-document keyphrase extraction, hindering the progress of the task. Recent advances in multi-text processing make the task an even more appealing challenge to pursue. To initiate this pursuit, we present here the first literature review and the first dataset for the task, MK-DUC-01, which can serve as a new benchmark. We test several keyphrase extraction baselines on our data and show their results.
QA-Align: Representing Cross-Text Content Overlap by Aligning Question-Answer Propositions
Sep 26, 2021
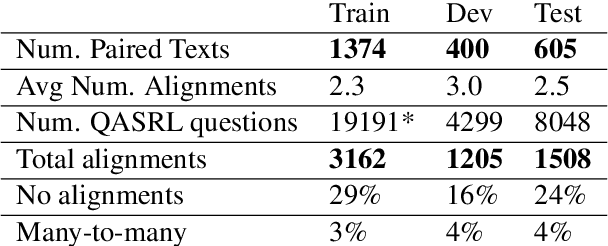
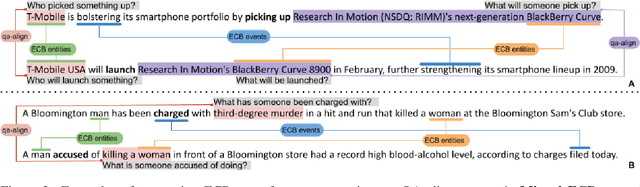
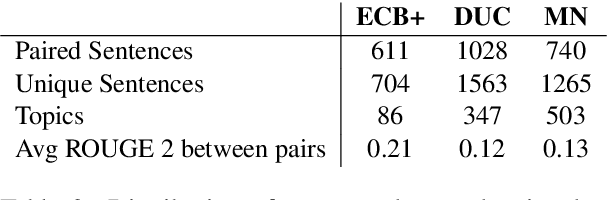
Multi-text applications, such as multi-document summarization, are typically required to model redundancies across related texts. Current methods confronting consolidation struggle to fuse overlapping information. In order to explicitly represent content overlap, we propose to align predicate-argument relations across texts, providing a potential scaffold for information consolidation. We go beyond clustering coreferring mentions, and instead model overlap with respect to redundancy at a propositional level, rather than merely detecting shared referents. Our setting exploits QA-SRL, utilizing question-answer pairs to capture predicate-argument relations, facilitating laymen annotation of cross-text alignments. We employ crowd-workers for constructing a dataset of QA-based alignments, and present a baseline QA alignment model trained over our dataset. Analyses show that our new task is semantically challenging, capturing content overlap beyond lexical similarity and complements cross-document coreference with proposition-level links, offering potential use for downstream tasks.
iFacetSum: Coreference-based Interactive Faceted Summarization for Multi-Document Exploration
Sep 23, 2021

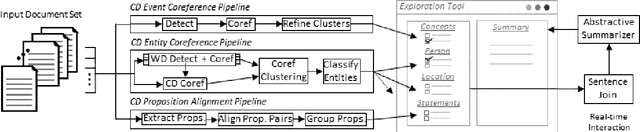
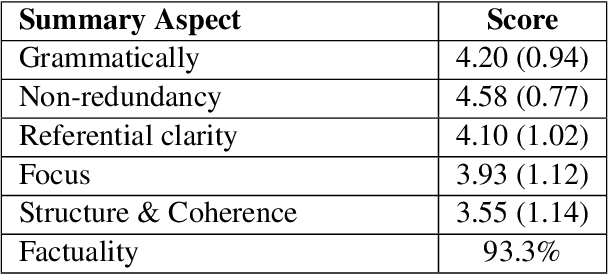
We introduce iFacetSum, a web application for exploring topical document sets. iFacetSum integrates interactive summarization together with faceted search, by providing a novel faceted navigation scheme that yields abstractive summaries for the user's selections. This approach offers both a comprehensive overview as well as concise details regarding subtopics of choice. Fine-grained facets are automatically produced based on cross-document coreference pipelines, rendering generic concepts, entities and statements surfacing in the source texts. We analyze the effectiveness of our application through small-scale user studies, which suggest the usefulness of our approach.
Asking It All: Generating Contextualized Questions for any Semantic Role
Sep 10, 2021

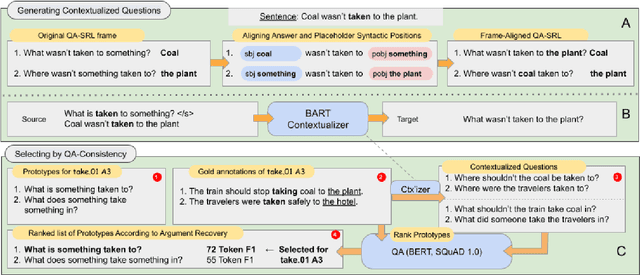
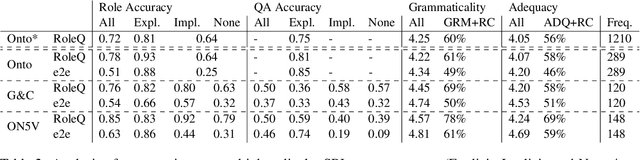
Asking questions about a situation is an inherent step towards understanding it. To this end, we introduce the task of role question generation, which, given a predicate mention and a passage, requires producing a set of questions asking about all possible semantic roles of the predicate. We develop a two-stage model for this task, which first produces a context-independent question prototype for each role and then revises it to be contextually appropriate for the passage. Unlike most existing approaches to question generation, our approach does not require conditioning on existing answers in the text. Instead, we condition on the type of information to inquire about, regardless of whether the answer appears explicitly in the text, could be inferred from it, or should be sought elsewhere. Our evaluation demonstrates that we generate diverse and well-formed questions for a large, broad-coverage ontology of predicates and roles.